NLU
NLP의 하위 분야인 NLU를 소개하고 NLU 의 subtask 중 하나인 QA(QQuestion Answering) 에 대해 정리했습니다.
: Natural Language Understanding
기계가 자연어에 대한 Synthetic과 Semenatic Understanding을 보인다면 그 기계는 NLU를 수행하고 있다고 볼 수 있다.
Question Answering(task)
특정 자연어 텍스트를 기계가 올바르게 이해하고 답변하는지 평가하는 Reading Comprehension의 일종이다.
질문에 대해 기계가 답변하는 QA의 형태를 가지고 있다는 점에서 NLU task라고 볼 수 있다.
QA task의 경우 질문에 대한 답이 Input인 지문안에 분명히 존재하기 때문에 평가지표로 Accuracy와 F1 Score를 사용할 수 있다.
1.2 대표적인 데이터셋
SQuAD
: Stanford Question Answering Dataset
QA와 같은 Reading Comprehension 문제의 해결을 위해 스탠포스에서 개발한 대표 Benchmark.
Input은 지문인 Context와 지문 내에서 답을 찾을 수 있는 Question으로 구성된다.
SQuAD 데이터 셋을 통해 QA task를 수행할 경우 기계는 출력값으로 지문(Context) 내에 포함된 질문의 답의 시작과 끝의 인덱스를 반환해야 한다,
- ex) SQuAD의 예시

SOTA models for QA task
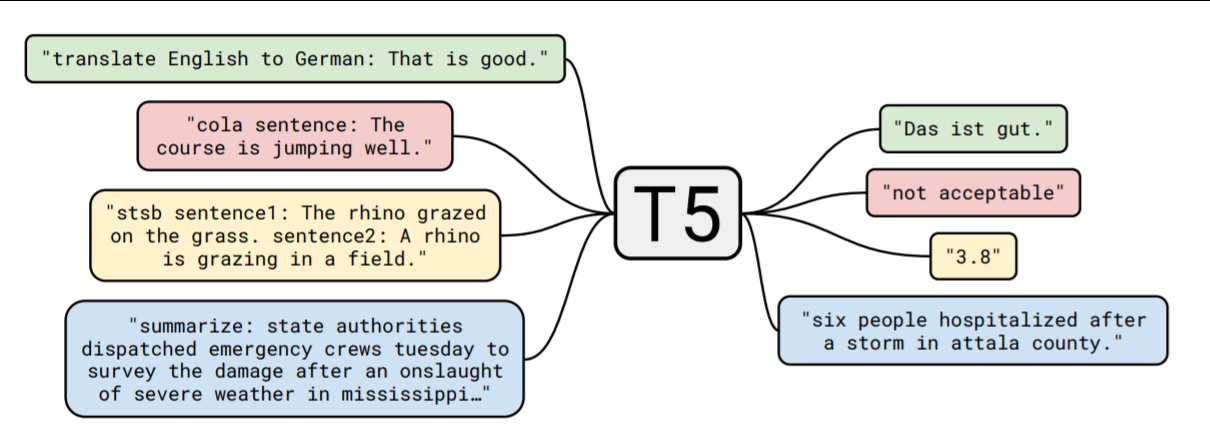
T5 (Text to Text Transfer)
T5는 전이학습을 기반으로한 구글에서 개발한 Transformer 기반 Language Model이다.
현 시점에서 QA task에서 가장 높은 성능을 보이는 SOTA 모델의 하나이다.
전이학습(Transfer Learning)
- 전이학습은 이미 학습된 큰 데이터셋의 가중치를 가지고 와서 해결하고자 하는 다른 과제에 맞게 튜닝해서 사용하는 방법론이다.
- T5 paper에서는 하나의 언어모델을 비지도로 pre-train한 뒤 세부 task에 따라 지도학습으로 fine tuning하는 방식을 사용하였다.
XLNet: Generalized Autoregressive Pretraining for Language Understanding
BERT의 Autoencoding method에 Autoregressive기법을 더해 성능을 개선시킨 언어모델.
Autoregressive Pretrained method
- AR(자기회귀) 방법론은 기존 BERT가 가지고 있는 masking을 보완하기 위해 사용되었다.
- AR은 BERT가 가지고 있는 문제점을 보완할 수 있지만 알고리즘 특성상 단방향 만을 고려한다는 문제점이 있다.
- BERT의 경우 AutoEncoding 과정에서 토큰이 독립적으로 예측되기 때문에 토큰 간 Dependency가 학습이 안되는 문제점이 있었다.
- XLNet에서는 permutaion을 이용해 모든 가능한 sequence를 고려해서 (Factorization Order) AR 방법론을 적용하여 AR과 AutoEncoding 방법론을 모두 보완해 성능을 개선시켰다.
References

6개의 댓글

T5는 정말 많은 task에서 좋은 성능을 보이는 것 같네요!
궁금한건 Question 은 NLU인데, Answering은 NLG부분이 아닌가요? 둘 다 있으니, NLU와 NLG 양 분야의 task인걸까요?


T5가 Question Answering에서 좋은 성능을 보이는군요!! 좋은 정보 감사합니다