Langchain
RAG (Retrieval-Augmented Generation) 정리
RAG란?
"Retrieval-Augmented Generation"
- 모델이 미리 학습한 정보만 사용하는 것이 아니라,
외부 문서에서 관련 정보를 검색(retrieve)하여
그 정보를 바탕으로 응답을 생성(augmented generation)하는 방식이다.
왜 RAG가 필요한가?
- 기존 모델은 훈련된 지식만을 바탕으로 답변 → 최신 정보 반영 어려움
- 비정형 데이터를 다룰 수 없고, 특정 문서 내용도 빠르게 접근 불가
- 결과적으로 사실과 다른 응답(Hallucination) 가능성 증가
RAG는 이런 문제를 해결하기 위한 구조이다.
RAG 시스템 구조
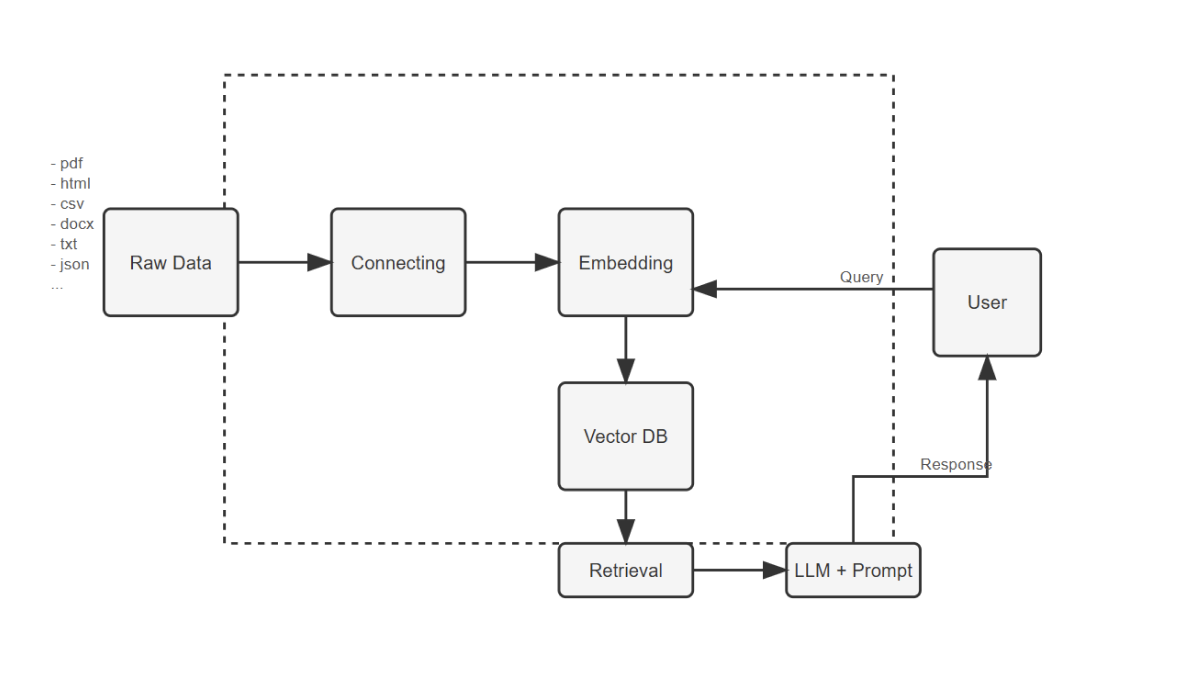
Query
↓
Retrieval
↓
Context + Prompt
↓
Generator (LLM)
↓
Response- 사용자 질의(Query)에 대해
- 외부 문서에서 관련 정보 검색 (Retrieval)
- 검색된 문서를 포함한 프롬프트를 구성
- LLM이 최종 응답을 생성
RAG 구성 요소
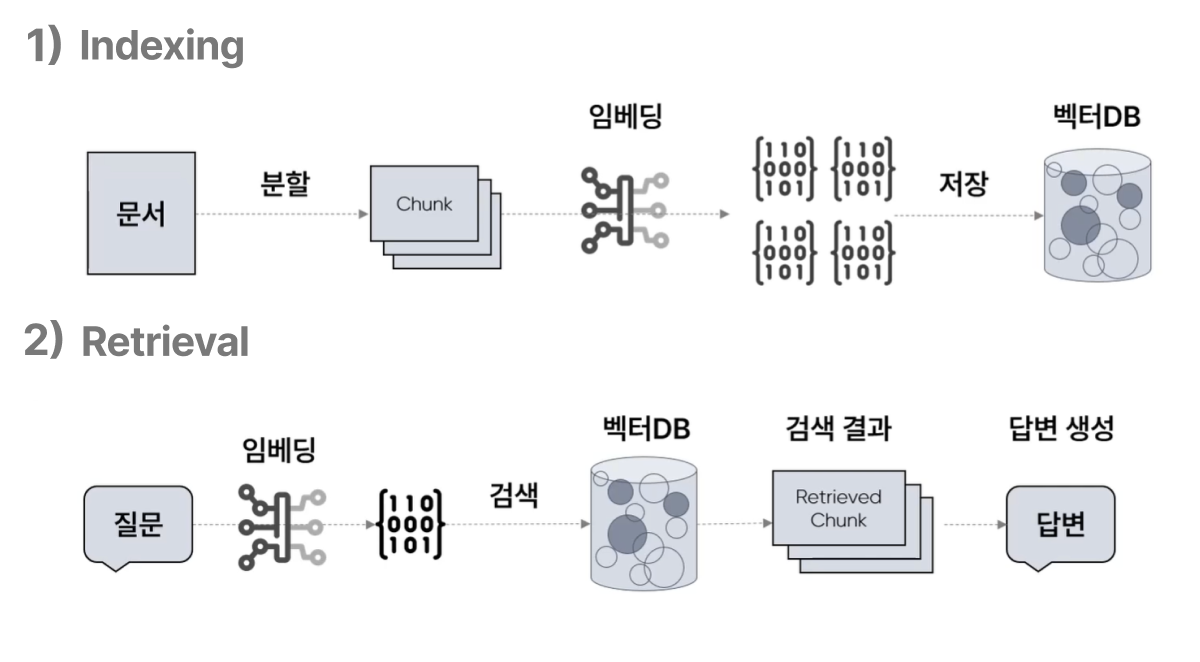
1) Indexing
- 문서를 벡터화하여 벡터 DB에 저장
- 텍스트 → Chunk 단위로 나누고
- 각 조각을 임베딩(Embedding)으로 변환 후 저장
2) Retrieval
- 사용자가 질문을 입력하면
- 관련도가 높은 문서 조각을 검색
- 이 조각들을 LLM에 함께 제공하여 정확한 응답 생성
요약
| 구성 단계 | 설명 |
|---|---|
| Indexing | 문서를 벡터화하여 검색 가능하게 만듦 |
| Retrieval | 질문에 맞는 조각을 검색 |
| Generation | 검색된 정보를 바탕으로 GPT가 응답 생성 |
RAG는 정확하고 최신의 정보를 반영한 답변을 만들 수 있도록 해주는
현대 AI 시스템의 핵심 구성 방식이다.
LangChain 정리
LangChain이란?
LLM(대형 언어 모델)을 활용하여
다양한 기능을 체인 형태로 연결해 복잡한 애플리케이션을 구축할 수 있도록 도와주는 프레임워크이다.
LangChain vs LangGraph
| 항목 | LangChain | LangGraph |
|---|---|---|
| 목적 | LLM 사용한 체인 구성 | 상태기반 Agent 시스템 구성 |
| 개념 | Chain, Tool, Retriever 등을 조합 | Node + Edge 기반 그래프 구조 |
| 실행 흐름 | 순차적 또는 조건 기반 | 비선형, 조건 기반 |
| 예시 | 대화형 에이전트, RAG 등 | 복잡한 Agent, 비동기 작업 흐름 |
LangGraph는 LangChain의 확장판으로
조건 분기, 상태 추적이 필요한 고급 Agent 설계에 적합하다.
LangChain 구성요소
- Chat Model (LLM)
- Prompt Template
- Document Loaders
- Text Splitters
- Embeddings
- Vector Stores
- Retrievers
- Chains
- Tools
- Agents
- Memory
- Callbacks
- Output Parsers
... 등 다양하게 구성 가능!
LangChain Module
1️⃣ Indexing
- 문서를 로딩하고 분할한 뒤 벡터화하여 Vector DB에 저장
문서 → DocumentLoader
→ TextSplitter
→ Embeddings
→ VectorStore 저장2️⃣ Retrieval
- 사용자의 질문 → 관련된 문서 chunk 검색 → LLM 응답 생성
질문 → Embeddings 생성
→ VectorStore에서 유사 문서 검색
→ Prompt에 삽입 후 응답 생성🔧 Retrieval 연동 방식 예시:
LLMChain + PromptTemplateRetrievalQA
요약
| 구성 단계 | 설명 |
|---|---|
| Indexing | 문서 벡터화 후 저장 |
| Retrieval | 질문에 맞는 문서 검색 |
| Generation | 문서 + 질문 조합으로 응답 생성 |
LangChain은 RAG, Agent, Tool Calling 등 복잡한 LLM 시스템의 기반을 구축하는 데 필수적인 프레임워크입니다.
LangChain 기반 RAG 구축 단계별 정리
LangChain을 활용하여 문서 기반 RAG 시스템을 구성하는 전체 흐름을 단계별로 정리합니다.
각 단계에 맞는 실제 코드 예시도 함께 포함했습니다.
1. Document Loading
다양한 소스(PDF, Notion, 웹 등)로부터 문서를 불러올 수 있도록
DocumentLoader를 통해 데이터를 읽어옵니다.
예시 코드:
from langchain.document_loaders import TextLoader
loader = TextLoader("sample.txt")
documents = loader.load()2. Chunking
LLM은 긴 텍스트를 한 번에 처리하지 못하기 때문에
문서를 적절한 길이로 나눠주는 과정이 필요합니다.
예시 코드:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
docs = text_splitter.split_documents(documents)3. Embedding
각 텍스트 조각을 벡터로 변환해주는 과정입니다.
예시 코드:
from langchain.embeddings import OpenAIEmbeddings
embedding_model = OpenAIEmbeddings()4. Vector Store
벡터화된 데이터를 저장하는 DB 역할을 합니다.
나중에 유사한 문서를 찾기 위한 기반이 됩니다.
예시 코드:
from langchain.vectorstores import FAISS
db = FAISS.from_documents(docs, embedding_model)
db.save_local("vector_db")5. Retriever
저장된 벡터 DB에서 질문과 가장 유사한 문서 조각을 찾아주는 도구입니다.
예시 코드:
retriever = db.as_retriever()전체 요약 흐름
- 문서 불러오기 →
DocumentLoader - 텍스트 쪼개기 →
TextSplitter - 벡터화 →
OpenAIEmbeddings - 저장 →
Vector Store - 검색 →
Retriever - 등등...
이렇게 구성된 RAG 시스템은 GPT 모델에게 필요한 문맥을 제공하여 보다 정확하고 풍부한 응답을 생성할 수 있게 한다.
