Few Shot Learning (One shot, Zero shot ...)
Few shot learning
-
적은 데이터로 학습을 잘 시킬 순 없을까...?
-
기존의 딥러닝은 사람의 인지 과정과 얼마나 다른가?
- 우리는 처음보는 아르마딜로, 천산갑 사진 1-2만 있어도 임의의 사진이 아르마딜로인지, 천산갑인지 구분할 수 있다.
-> 이는 우리가 "구분하는 방법"을 알고 있기 때문! Learn to Learn, Meta Learning- Traning set, Support set, Query Image가 필요
- Training image를 통해 "구분하는 방법"을 배우고, Query image가 들어왔을 때 이 Query image가 Support set 중 어느 것과 같은 종류인지 맞추기
- Query image가 어떤 클래스에 "속하냐"보다 어떤 클래스와 "같은 클래스냐"를 구분하는 것
- Support set의 class 개수와 sample 수를 기준으로 k-way n-shot이라는 표현을 쓴다. - k-way: Support set의 클래스 개수=k
- n-shot: 클래스가 가진 sample 수=n
- Training image를 통해 "구분하는 방법"을 배우고, Query image가 들어왔을 때 이 Query image가 Support set 중 어느 것과 같은 종류인지 맞추기
- Traning set, Support set, Query Image가 필요
-
Transfer learning과 다른 점을 말하기가 애매함
- Transfer learning: 특히 vision 분야에서 다른 domain으로 학습된 모델의 layer를 일부 얼리고 일부를 다른 domain image로 fine-tuning하는 과정- Few shot learning은 꼭 일부를 얼리고 fine-tuning하는 것을 의미하진 않음. 말 그대로 새로운 domain(unseed dataset)이 적게 있는 경우
- 기본 학습 방법: Similarity를 학습하기
- 기초 few shot learning에서는 Siamese Network(샴 네트워크)를 사용함.
즉, 같은 CNN 모델을 사용하여 hidden representation을 구한 후 이 차이를 이용하는 형식!
One Shot Learning
- Downstream task의 data를 한 건만 사용해 어떻게 수행되는지 참고한 후 바로 downstream task 수행
- 각 class에 따른 하나의 Training 이미지만으로, 이미지를 인식하고 분류하는 모델을 만드는 것.
-> Distance function으로 입력 이미지와 사원 이미지 간의 유사도를 구할 수 있게 하자 - 입력 이미지와 사원 이미지는 각각 Simeses Network (동일한 구조, 파라미터)를 통과
- Triplet Loss
- 3개 이미지에서 loss function을 만드는 방법.
- A(Anchor) : 입력 이미지 encoding vector
- P(Positive) : 입력 이미지와 동일한 class의 encoding vector
- N(Negative) : 입력 이미지와 다른 class의 encoding vector
- d(A, P) - d(A, N) + alpha <=0 이 되도록 하기
- 이때 A, P, N vector, d(A, P), d(A, N)는 0이면 안됨.


- 단점
- A, P, N에 사용될 이미지를 random하게 고를 때 Loss가 너무 쉽게 0이 됨
- 구분하기 어려운 sample 조합을 고르는 게 중요함. 즉 d(A, P)와 d(A, N)의 차이가 크지 않은 이미지를 우선적으로 사용하는 게 좋음.
- A, P, N에 사용될 이미지를 random하게 고를 때 Loss가 너무 쉽게 0이 됨
- 단점
Zero Shot Learning
- Downstream task의 data를 전혀 사용하지 않고 pretrained model로 downstream task를 바로 수행.
- 한 번도 보지 못한 dataset으로 성능을 측정함.
참고 자료 : https://velog.io/@stapers/%EB%85%BC%EB%AC%B8%EC%8A%A4%ED%84%B0%EB%94%94-Week9-10-Zero-shot-Learning-Through-Cross-Modal-Transfer (ZSL through Cross-modal Transfer)
본 논문의 main idea
-
- 이미지들은 신경망 모델로 학습된 단어의 의미적 공간에 mapping 됨
-
- 분류기는 test 이미지를 seen class로 분류하는 걸 선호하기 때문에 모델은 새로운 이미지가 seen class인지 결정하는 novelty detection도 포함하게 됨
-
Domain Adaptation
한 domain에서 학습된 분류기를 다른 domain이 adaption 시키는 방법 연구 -
Multimodal Embedding
여러 source에서 나온 정보들을 연관짓는 것. -
Word, Image Representation : Distributional Approach
단어들 간의 의미적 유사성 catch
co-occurences 방식 이용. -
Zero-shot learning model
- Notations

- Parameters
- x에 대한 p(y|x)를 예측하기! x가 f in F_t에 매핑된 semantic vector를 사용
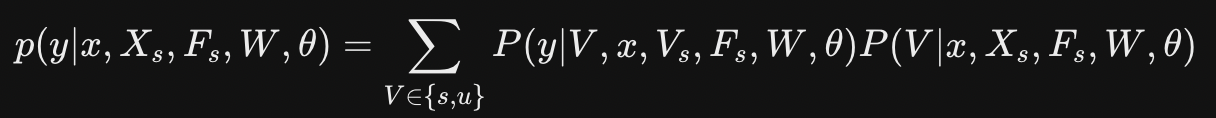
- 신규 데이터 탐지 전략
- P(V=u | x, X_s, F_s, W, theta)는 unseen class image에 대한 확률이라 train 과정에서는 얻을 수 없음
-> 이상치 탐지로 seen과 unseen을 판별하자- 1. 각 클래스마다 등거리 변환된 정규 분포 사용 (Isometric, Class-specific Gaussians) - 각 seen class y에 대해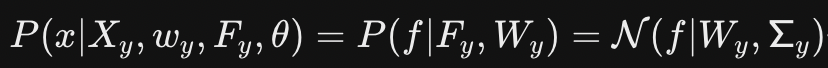
- threshold T_y를 설정해 확률이 T_y 이하이면 이상치(1), unseen으로 판별

- T_y가 작을 수록 unseen class로 판별되는 데이터가 적어짐. 가장 큰 단점은 이상치에 대해 실제 확률 값을 도출하지 않는다는 점.
- 2. seen과 unseen에 대한 weighted combinated classifier를 사용해 class에 대한 조건부 확률을 구함

- 많은 unseen 이미지는 전체 데이터 manifold에 대해 이상치가 아님.
- 2개의 parameter를 가짐.
- k: 특정 point가 이상치인지 결정하기 위해 고려되는 가장 가까운 이웃의 수
- lambda: 표준 편차의 계수. lambda가 클 수록 더 많은 point가 평균에서 떨어져 있음.
- seen class의 training data 중 각 point f in F_t에 대해 가장 가까운 k개 이웃을 context set C(f) in F_s로 정의. 이를 이용해 각 x와 C(f)에 대한 pdist(probabilistic set distance)를 구할 수 있음. 여기서 distance는 euclidean distance를 사용함.

- 여기에 로그를 취하고, normalization factor Z를 아래와 같이 정의한다.

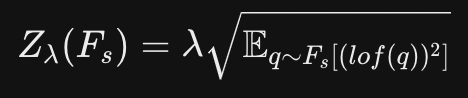
- lof와 Z를 이용해 Local outlier Probability (LoOP)를 아래처럼 구한다.
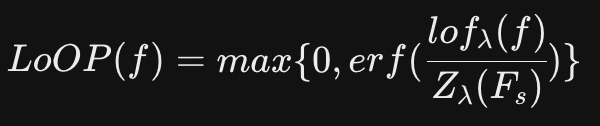
- 3. 분류
- V=s의 경우 P(y|V=s, x, X_s)를 구하기 위해 아무 분류 모델이나 쓸 수 있지만 논문에서는 softmax classifier를 사용함.
- V=u의 경우, 즉 zero-shot의 경우 각 novel class word vectors에 isometric Gaussian을 가정해 likelihood에 따라 class를 분류함.
CLIP
- https://daeun-computer-uneasy.tistory.com/39
- nlp, vision, ZSL
