BERT
BERT: Pre-training of deep directional transformers for language understanding
- 사전 훈련 언어 모델. 사전 훈련 embedding을 통해 특정 과제의 성능을 더 좋게 할 수 있는 언어 모델.
Bert의 input representation
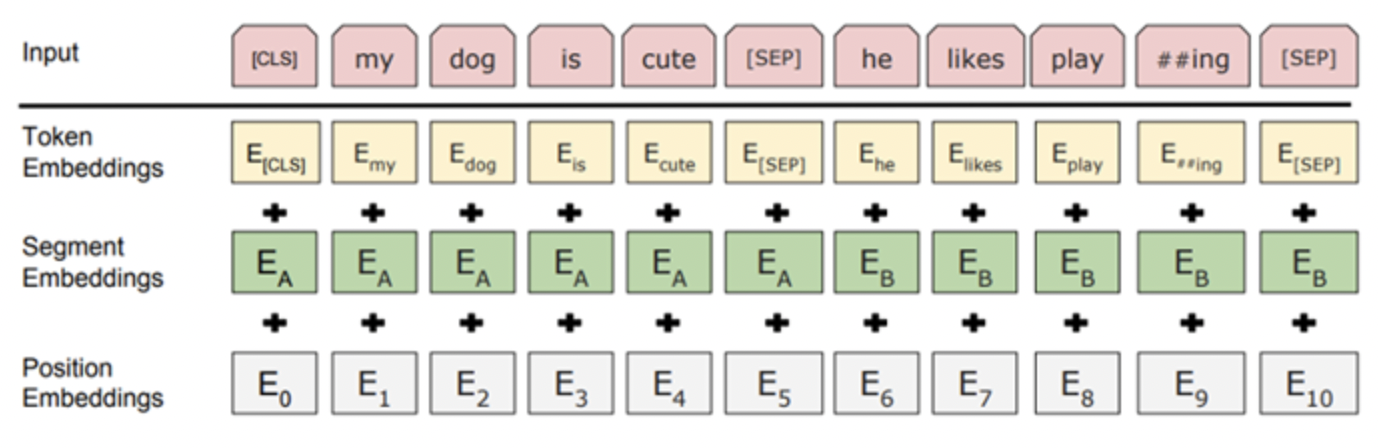
- Token embedding
- word piece embedding 방식을 사용함. 자주 등장하면서 가장 긴 길이의 sub-word를 하나의 단위로 만듦. 즉, 자주 사용하는 단어는 그 자체가 단위가 되고, 자주 사용하지 않는 단어는 더 작은 sub-word로 쪼개짐.
- 모든 문장의 시작에는 [CLS], 문장의 끝에는 [SEP]이 위치함.
- Segment embedding
Token으로 나뉘어진 문장들을 다시 하나의 문장으로 만들고 첫번째 [SEP] 토큰까지는 0으로, 그 이후 [SEP] 토큰까지는 1로 마스크를 만들어 문장들을 구분함. - Position Embedding
토큰의 순서를 embedding함.
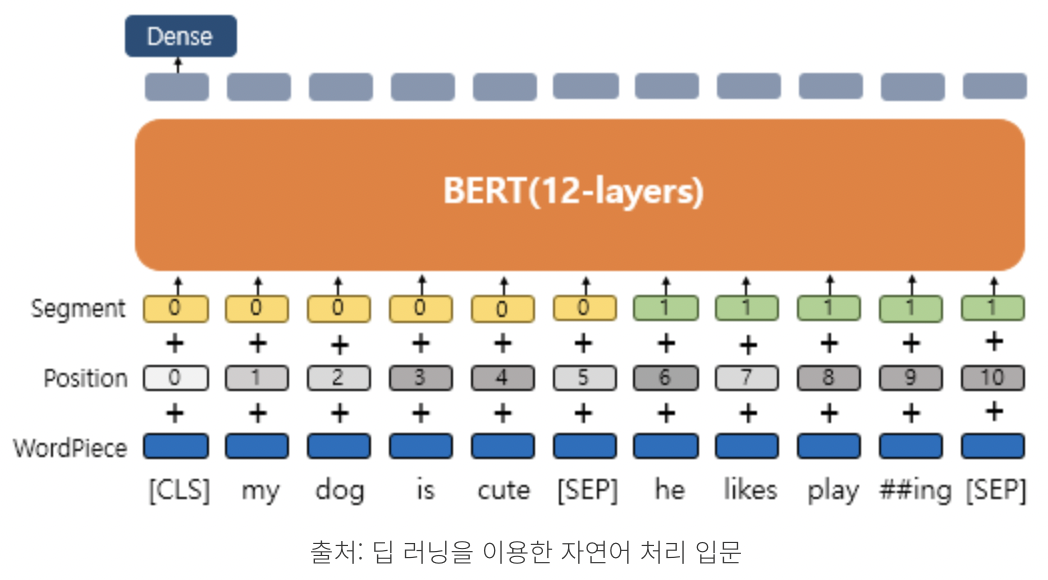
Transformer 기반의 BERT
1. BERT의 MLM(Masked Langauge Model)
- 입력에서 몇 개의 단어를 무작위로 masking하고, 이를 Transformer 구조에 넣어 주변 단어의 맥락으로 masking된 token을 예측함.
- 15% token 중 80%는 token을 [MASK]로 바꾸고, 10%는 token을 무작위 단어로 바꿈.
- 이 [MASK] token은 pre-training에만 이용되고, fine-tuning에는 이용되지 않음.
- BERT의 NSP(Next Sentence Prediction)
- 두개의 문장이 동시에 입력되면 두 번째 문장이 첫 번째 문장의 뒤에 오는 문장인지 판단함.
https://moondol-ai.tistory.com/463
: bert 설명, 간단한 실습

:):):)