1. Index
1.1 개념
인덱스는 테이블의 검색 속도를 향상시키기 위한 데이터 구조이다.
전체 테이블을 스캔하지 않고, 조건절에 맞는 행을 빠르게 탐색할 수 있다.
- WHERE / JOIN / ORDER BY / GROUP BY 등에 자주 사용된다.
- 인덱스는 조회 성능은 향상, 그러나 데이터 변경(INSERT/UPDATE/DELETE) 시 부하가 발생한다.
1.2 Index를 쓰는 이유
인덱스는 결국 찾는 과정을 줄이기 위한 도구이다.
데이터베이스의 저장하는 양이 커질 수록 탐색의 범위도 늘어나게 되는데, 이 과정을 “사전의 목차” 처럼 정렬해 놓고 모든 테이블을 읽지 않고도 원하는 값을 O(log N) 시간 안에 찾을 수 있다.
그렇다고 모든 컬럼 인덱스를 적용하면?
모든 칼럼에 인덱스를 적용하면 성능은 오히려 나빠진다. INSERT 시 삽입된 데이터 외에도 인덱스 정보도 다시 수정하기 때문에 쓰기 성능이 매우 나빠진다. 또한 인덱스도 별도로 저장해야하기 때문에 디스크 공간의 낭비가 발생한다.
1.3 Index 스캔 방식
- 옵티마이저 : SQL을 가장 빠르게 실행할 방법(실행 계획)을 자동으로 결정해주는 엔진이다.
옵티마이저는 SQL 실행 시 인덱스를 사용할지 결정하고, 사용하기로 했다면 어떤 방식으로 인덱스를 읽을지 선택한다.
→ “인덱스를 어떻게 탈 것인가”를 정의하는 단계이다.
1.3.1 인덱스 접근 방식
- Sequential Access (순차 접근) : 인덱스 리프 노드를 정렬된 순서대로 앞→뒤로 읽는 방식
- B-Tree 인덱스의 리프 노드는 항상 정렬된 상태로 연결되어 있음
- 디스크 I/O 효율이 가장 좋음 (캐시 효율, prefetch 효과)
- 많은 데이터를 읽어야 할 때도 빠른 방식
- 정렬이 필요한 쿼리와 궁합이 좋음
- 사용되는 스캔 방식:
- Index Range Scan (범위 내부)
- Index Full Scan (전체 순차 스캔)
- Random Access (랜덤 접근) : 필요한 블록으로 임의 위치에 점프해서 읽는 방식
- 특정 키를 찾기 위해 B-Tree를 타고 내려갈 때 사용
- ROWID로 테이블 데이터를 찾을 때도 랜덤 접근
- SSD에서도 순차 읽기보다 비용이 크다
- 인덱스 → 테이블 접근에서 성능 차이가 발생하는 핵심 원인
- 사용되는 스캔 방식:
- Index Unique Scan (한 건 찾기)
- Index Range Scan의 시작점 탐색
- Table Access By ROWID
- Index Fast Full Scan 일부 구간(랜덤 병행)
- Parallel Access (병렬 접근) : 인덱스 블록을 여러 프로세스가 동시에 나눠서 읽는 방식
- 정렬 순서가 필요 없을 때만 가능
- 다중 프로세스 또는 스레드를 활용해 I/O 성능 극대화
- 대용량 인덱스 전체 읽기에서 매우 빠름
- COUNT(*), 통계형 쿼리에서 높은 성능
- 사용되는 스캔 방식:
- Index Fast Full Scan 전용
1.3.2 Index Range Scan
B-Tree 인덱스에서 조건에 해당하는 키 값 구간만 찾아서, 그 구간에 속한 리프 노드들만 순차적으로 읽는 방식
- 예:
WHERE age BETWEEN 20 AND 30,WHERE name LIKE 'J%'- 인덱스의 특정 구간만 순차적으로 탐색
- 가장 일반적이고 효율적인 스캔 방식
특징:
- 범위 조건(>, <, BETWEEN, LIKE)에서 자주 사용
- 조건에 맞는 구간만 인덱스 리프 노드를 순차 접근
1.3.3 Index Unique Scan
인덱스 키가 유일한 경우, 단 하나의 ROWID만 찾는 방식
(= 조건이 무조건 한 행만 반환하는 경우)
- 예:
WHERE id = 100(PK, UNIQUE INDEX)- 인덱스 트리를 통해 정확히 한 행만 즉시 접근 가능
특징:
- Primary Key / Unique Key 조건에서만 사용
- 트리 탐색 깊이 최소 (Root → Leaf 직행)
1.3.4 Index Full Scan
인덱스 전체를 처음부터 끝까지 읽는 방식
- 예: 인덱스는 있지만 WHERE 조건이 없을 때
SELECT * FROM users ORDER BY name;- 인덱스가 정렬되어 있으므로, 정렬된 결과를 그대로 이용할 때 유용
특징:
- 인덱스 전체를 순차 접근 (모든 리프 노드 읽음)
- WHERE 조건이 없거나, 인덱스만으로 결과를 얻을 때 사용
Index Fast Full Scan
→ 인덱스 전체를 읽지만, 정렬 순서를 보장하지 않고 빠르게 읽는 방식
- 특징
- 인덱스 블록을 병렬/랜덤 읽기 방식으로 가져오기 때문에 Index Full Scan보다 빠르다.
- 예시
SELECT COUNT(*) FROM users;
- 정렬이 필요하지 않은 COUNT 연산에 효과적으로 사용된다.
1.3.5 Index Skip Scan
결합 인덱스의 첫 번째 컬럼을 조건절에 사용하지 않았을 때
옵티마이저가 첫 컬럼 값을 반복 대입하면서 인덱스를 ‘부분적으로’ 사용하는 기술
- 예: 인덱스
(gender, age)에서WHERE age = 30
gender = 'F' 인 구간에서 age=30 스캔
gender = 'M' 인 구간에서 age=30 스캔
gender = 'U' 인 구간에서 age=30 스캔 (있다면)- 옵티마이저가 첫 컬럼(`gender`)의 값을 내부적으로 반복 추정하여 스캔
→ **첫 컬럼을 내부에서 “카테고리”처럼 돌려가며 여러 번 Range Scan 수행**특징:
- 결합 인덱스(Composite Index) 에서만 발생
- 첫 컬럼을 조건절에 사용하지 않아도 인덱스 일부 활용 가능
- 하지만 성능은 Range Scan보다 느림
1.4 Index를 사용하지 못하는 경우
인덱스가 존재해도 Oracle Database 옵티마이저가 인덱스를 사용하지 않고 풀 테이블 스캔이나 다른 접근 경로를 선택하는 경우가 있다.
1.4.1 인덱스를 사용하지 않는 주요 원인**
| 구분 | 설명 |
|---|---|
| 선두(Leading) 컬럼 미사용 | 복합 인덱스의 첫 번째 컬럼이 WHERE 조건절에 포함되지 않으면 인덱스 탐색 불가 |
| 부정 조건 (NOT, !=, <>) | 옵티마이저가 검색 범위를 좁히기 어렵다고 판단 |
| 함수 또는 연산 사용 | 인덱스 컬럼에 함수나 계산식을 적용하면 인덱스 구조를 직접 활용할 수 없음 |
| 암시적 형변환 발생 | 문자열-숫자 비교 등에서 타입이 변환되면 인덱스 사용 불가 |
와일드카드 선두 사용 (LIKE '%abc') | 인덱스는 왼쪽부터 정렬되어 있으므로, 첫 글자가 고정되지 않으면 사용 불가 |
| 데이터 대부분을 반환하는 조건 | 인덱스를 써도 읽는 양이 많으면 오히려 비효율 → 풀스캔 선택 |
| 최신 통계 정보 부재 | 옵티마이저가 인덱스 효율을 잘못 계산함 |
-
선두 컬럼(Leading Column)을 사용하지 않은 경우
복합 인덱스는 왼쪽부터 정렬되어 있기 때문에 첫 번째 컬럼이 WHERE 조건절에 등장하지 않으면 인덱스를 타고 내려갈 출발점을 찾을 수 없다.
-
예시
// 인덱스: (name, age)
WHERE age = 26; // 인덱스 사용 불가
WHERE name = 'max'; // 사용 가능
WHERE name='max' AND age=26; // 사용 가능 이유 : 복합 인덱스는 전화번호부처럼 앞글자부터 찾아야 한다. 첫 컬럼을 건너뛰면 구조적으로 탐색 불가능하다.
-
함수 또는 계산식을 인덱스 컬럼에 적용한 경우
인덱스는 “원본 값의 정렬”을 기준으로 구성된다.
하지만 함수가 적용된 순간 전혀 다른 값이 되기 때문에 인덱스의 정렬 정보를 사용할 수 없다.- 예시
- 예시
WHERE LOWER(name) = 'max' // 인덱스 사용 불가
WHERE SUBSTR(phone, 2) = '010' // 사용 불가- 암시적 형변환 (Implicit Conversion)
문자열 ↔ 숫자 비교처럼 타입이 맞지 않으면
DB가 내부적으로 컬럼에 자동 변환 함수(TO_NUMBER / TO_CHAR) 를 적용한다.
이것도 결국 “함수 적용”이므로 인덱스를 깨뜨린다.
- 예시
// user_id NUMBER 컬럼
WHERE user_id = '100' // 인덱스 미사용 (암시적 TO_NUMBER(user_id))-
이유 : 함수가 들어가면 인덱스가 보관한 정렬 정보가 무효화된다.
-
와일드카드 선두 사용 (
LIKE '%ABC')인덱스는 문자열의 앞부분부터 정렬되기 때문에 앞이 '%'로 시작하면 DB가 “시작 위치”를 판단할 수 없다. → 결국 전체 스캔 필요.
- 예시
- 예시
WHERE name LIKE '%AM' // 인덱스 미사용
WHERE name LIKE 'MA%' // Range Scan 사용 가능이유 : 형변환은 숨어 있는 함수 적용이다. 결국 인덱스를 못 타게 만든다
-
데이터 대부분을 반환하는 조건
인덱스를 타면 “ROWID → 테이블 랜덤 읽기”가 발생한다.
하지만 결과가 너무 많으면 랜덤 IO가 폭발한다.그래서 옵티마이저는 판단한다:
어차피 대부분 읽을 거면 인덱스보다 Full Scan이 빠르다.- 예시
- 예시
WHERE status IN ('A', 'B', 'C') // 결과가 전체의 70% 이상일 때이유 : 인덱스는 왼쪽이 고정되어야 한다. 앞이 '%'면 시작점을 알 수 없어 전체 스캔으로 간다.
-
통계 정보가 오래되었거나 없는 경우
옵티마이저는 테이블의 카디널리티(행 수), 분포도, 블록 수, 인덱스 구조 등을 기반으로 “인덱스를 타는 게 빠른지”를 계산한다.
통계가 오래되면 잘못된 판단을 하고 인덱스를 타지 않거나, 반대로 불필요하게 타는 상황도 생긴다.
- 예시
-
최근에 테이블 데이터 폭증했는데 통계 미갱신
-
인덱스가 사실상 비효율인데 옵티마이저는 아직 효율적이라고 착각
이유 : 인덱스는 ‘소수의 데이터 찾기’에 최적화. 많이 읽을 거면 차라리 테이블 한 번에 스캔하는 게 더 빠르다.”
-
- 예시
2. Join
둘 이상의 테이블을 논리적으로 결합해 데이터를 조회하는 SQL 연산.
테이블 간 공통된 컬럼(보통 PK–FK 관계) 을 기준으로 데이터를 합친다.
| 구분 | 기준 | 설명 | 결과 |
|---|---|---|---|
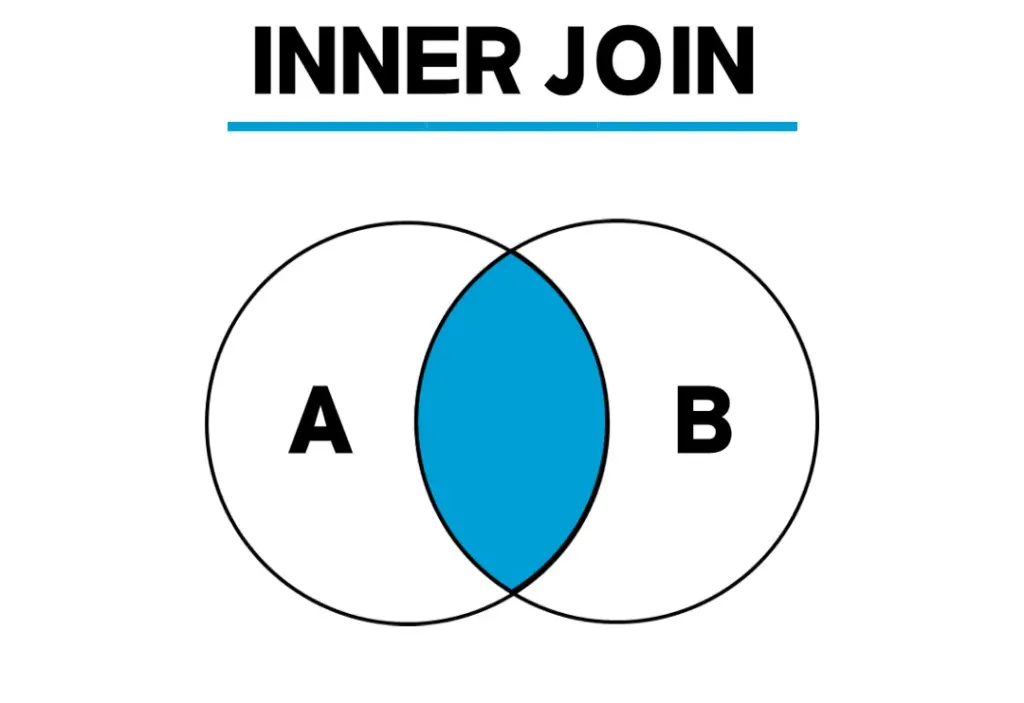
| INNER JOIN | 교집합 | 두 테이블에서 조건이 일치하는 행만 반환 | 공통된 데이터만 |
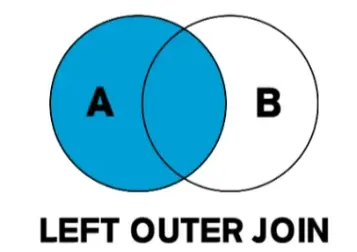
| LEFT OUTER JOIN | 왼쪽 기준 | 왼쪽 테이블의 모든 행 + 오른쪽 일치하는 행 | 일치하지 않으면 NULL |
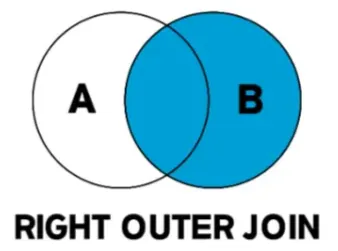
| RIGHT OUTER JOIN | 오른쪽 기준 | 오른쪽 테이블의 모든 행 + 왼쪽 일치하는 행 | 일치하지 않으면 NULL |
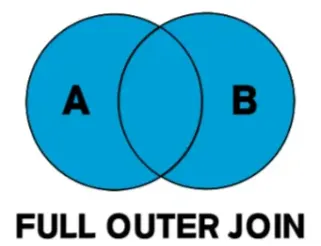
| FULL OUTER JOIN | 합집합 | 양쪽 테이블의 모든 행 반환 | 일치하지 않으면 NULL |
| CROSS JOIN | 모든 조합 | 조건 없이 모든 행을 곱집합으로 결합 | N×M개 행 |
| SELF JOIN | 자기 자신 | 같은 테이블끼리 조인 (별칭 필수) | 계층, 상하관계 표현 시 사용 |
2.1 INNER JOIN
SELECT a.id, a.name, b.category
FROM A a
JOIN B b ON a.b_id = b.id;- 두 테이블의 id가 같은 행만 결과로 반환
2.2 LEFT OUTER JOIN
SELECT a.name, b.category
FROM A a
LEFT JOIN B b ON a.b_id = b.id;- a를 기준으로, B에 매칭되는 데이터가 없으면 B.category 같은 컬럼이 NULL로 표시됨.
2.3 RIGHT OUTER JOIN
SELECT a.name, b.category
FROM A a
RIGHT JOIN B b ON a.b_id = b.id;- B 테이블을 기준으로 조회하므로, A에 매칭되는 데이터가 없으면 A.name 같은 컬럼이 NULL로 표시.
2.4 FULL OUTER JOIN (MySQL 미지원, Oracle 가능)
SELECT a.name, b.category
FROM A a
FULL OUTER JOIN B b ON a.b_id = b.id;- 두 테이블의 모든 행을 결합하고, 일치하지 않는 쪽은 NULL로 채움.
2.5 CROSS JOIN
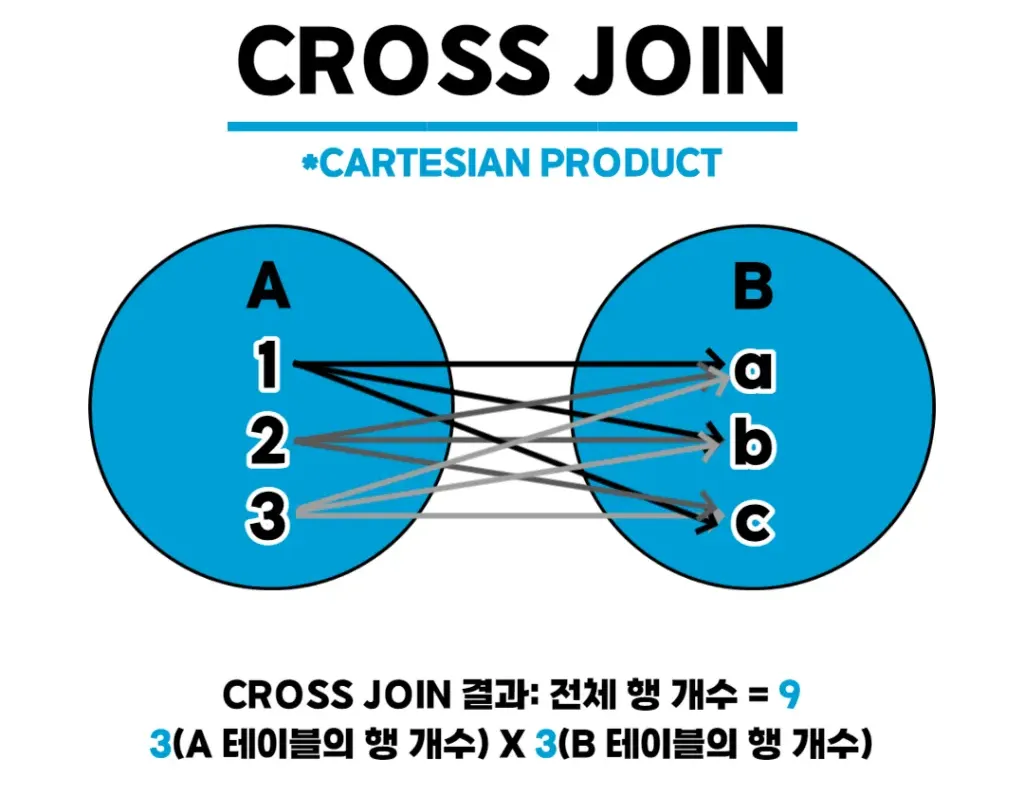
SELECT a.name, b.category
FROM A a
CROSS JOIN B b;- A와 B의 모든 조합(곱집합)을 생성하며, 조건 없이 모든 행이 서로 매칭
2.6 SELF JOIN

// A 테이블에는 상품 목록이 저장되어 있고, 일부 상품은 상위 상품(parent_id) 을 가진다.
SELECT a.product AS item, b.product AS parent_item
FROM A a
JOIN A b ON a.parent_id = b.id; 같은 테이블에서 상품과 그 상품의 상위 상품을 함께 조회하는 자기 조인이다.
3. JOIN 방식
조인에는 세 가지 기법이 존재한다.
다양한 상황에서 최적의 성능을 내기 위한 적절한 JOIN 계획을 세워 동작을 수행한다.
- 일반적으로는 옵티마이저가 계획을 세워 동작을 수행하지만, 항상 최적화된 계획만 세우지 않는다.
- 그런 경우는 수동적으로 JOIN 계획을 세워 넣어줘야하는 경우가 있다.
3.1 Nested Loops(중첩 반복) 조인
두 테이블 중 작은 테이블(Outer)의 각 행을 기준으로,
큰 테이블(Inner) 을 반복 탐색하면서 일치하는 데이터를 찾는 조인 방식이다.
이때 선행 테이블이(Outer Table) 작고, 후행 테이블(Inner Table)이 커야 효과적이다.
→ 인덱스가 없는 경우는 효율이 급격히 떨어져서 거의 선택하지 않는다.
- 선행 테이블 (Outer Table) : 조인하려는 두 테이블 중 더 작은 테이블
- 후행 테이블 (Inner Table) : 더 큰 테이블
동작 방식
- 1단계: Outer Table(선행 테이블)의 첫 번째 행을 선택
- 2단계: Inner Table(후행 테이블)에서 조인 조건(
=,<,>)으로 일치하는 행 탐색 - 3단계: 일치하면 결과 집합에 추가
- 4단계: Outer Table의 다음 행으로 이동 → 반복
특징
-
인덱스 필수
- Join 열에 해당하는 컬럼들은 인덱스를 가지고 있어야 한다. 인덱스가 없으면 성능이 매우 떨어질 수 있다
- 없다면 후행 테이블(Inner Table)을 매번 Full Scan 하게 되어 성능이 급격히 저하된다.
- Join 열에 해당하는 컬럼들은 인덱스를 가지고 있어야 한다. 인덱스가 없으면 성능이 매우 떨어질 수 있다
-
작은 데이터에 적합
- NL Join은 Outer Table(선행 테이블) 의 각 행을 기준으로 Inner Table(후행 테이블) 을 반복적으로 탐색하는 구조이다.
- 이때 인덱스가 아무리 잘 구성되어 있어도, 데이터량이 많을수록 반복적인 랜덤 액세스가 폭증한다.
→ 작은 테이블에는 매우 빠르지만. 대량 데이터 처리에는 비효율적인 구조이다.
3.2 Sort Merge조인
조인하려는 두 개의 테이블을 조인 칼럼을 기준으로 오름차순 정렬한 후, 두개의 테이블에서 정렬된 조인 대상 키를 스캔하면서 조인 결과를 생성하는 방식
동작 방식
- 1단계 : 옵티마이저는 조인 조건을 확인하고, 두 테이블 모두 조인 키 기준으로 정렬
- 2단계 : 이미 조인 컬럼에 인덱스가 있다면, 정렬 단계는 생략될 수 있다.
- A 테이블을 test_id 순으로 정렬
- B 테이블도 test_id 순으로 정렬
- 3단계 : 병합 단계
- 정렬된 두 결과를 나란히 놓고 조인 키를 순차적으로 비교하며 매칭
-
A의
test_id = 10←→ B의test_id = 10일치 하면 매칭 결과 생성 -
A, B 모두 다음 키로 이동 …
-
반복
→ 정렬되어 있으므로 순차 비교만으로 조인 가능
→ 인덱스 기반의 랜덤 엑세스 없음
-
- 정렬된 두 결과를 나란히 놓고 조인 키를 순차적으로 비교하며 매칭
특징
- NL 조인 단점을 보완
- Inner Table 을 반복적으로 탐색하는 NL 조인과 달리 Merge 조인은 두 테이블을 한 번에 액세스 한 후 메모리에서 모두 정렬 후 비교해서 탐색한다.
- 정렬 작업에 의한 비용 발생
- 정렬되어 값을 빠르게 찾아낼 수 있으나, 정렬 작업에 의한 비용이 발생한다.
- 정렬할 데이터가 너무 많으면 메모리에서 수행하기 어려워 질수 있어서 성능 하락 가능성이 있다. → 조인 컬럼에 인덱스를 생성하여 정렬 작업을 생략할 수 있도록 하는 것을 권장
- 정렬할 데이터가 너무 많으면 메모리에서 수행하기 어려워 질수 있어서 성능 하락 가능성이 있다. → 조인 컬럼에 인덱스를 생성하여 정렬 작업을 생략할 수 있도록 하는 것을 권장
- 정렬되어 값을 빠르게 찾아낼 수 있으나, 정렬 작업에 의한 비용이 발생한다.
- 스캔(순차 읽기) 방식 사용
- 랜덤 액세스 방식을 사용하는 NL 조인과 달리 Sort Merge 조인은 주로 스캔(순차 읽기)방식을 사용한다.
- 테이블들을 순차적(정렬된 데이터)으로 스캔하기 때문에 인덱스를 사용하지 않는다.
- 각 테이블을 1회씩만 읽기 때문에 이는 테이블의 크기가 큰 경우 더 효율적이다.
- 동등 조건 필요
- 조인 조건 중 동등 조건(=) 이 있어야한다. '=' 조건은 두 테이블의 조인 키 값이 정확히 일치하는 행을 쉽게 찾는데 사용된다.
❓왜 동등 조건 필요이 필요할까?
정렬된 두 테이블을 병합하려면, “기준이 되는 정확히 동일한 값”이 있어야 하기 때문이다.- 다른 비동등 조건(<,>,!=) 을 사용하면 정렬된 순서를 활용하기 어려우며 이는 조인의 성능을 저하시킬 수 있다.
- 하지만 FULL OUTER JOIN 의 경우, '=' 조건 없이도 가능하다.
❓ FULL OUTER JOIN은 왜 = 조건 없이 가능할까?
FULL OUTER JOIN은 양쪽 테이블의 모든 행을 다 포함 하는 조인 방식이다.
조건에 맞지 않아도 결과에 들어와야 하기 때문이다.
- 조인 조건 중 동등 조건(=) 이 있어야한다. '=' 조건은 두 테이블의 조인 키 값이 정확히 일치하는 행을 쉽게 찾는데 사용된다.
- 중복 데이터 제거 필요
- 중복 값이 아주 많은 경우, 중복 데이터를 제거하기 위해 메모리에서 임시 테이블을 생성하게 되는데 이는 많은 비용을 발생시킨다.
- 이를 피하기 위해 UNIQUE INDEX 를 생성하거나, GROUP BY 로 묶는 방법 등 중복 데이터 처리가 중요하다.
- 주의 : 중복을 줄이려다 일부 데이터가 버려질 수 있음.
- 중복 값이 아주 많은 경우, 중복 데이터를 제거하기 위해 메모리에서 임시 테이블을 생성하게 되는데 이는 많은 비용을 발생시킨다.
3.3 Hash 조인 작동 방식
Build Input 테이블의 조인 컬럼에 Hash Function(해시 함수) 를 이용해서 Hash Key(테이블의 인덱스 역할) 을 생성 후, Hash Table(해시 맵) 을 생성한다.
그리고 Probe Input 테이블의 조인 조건에 맞는 해시 테이블을 탐색하며, 해시 함수를 적용하여 해시 키를 생성하고, 해시 테이블에서 같은 해시 키를 찾아서 조인을 진행하는 방식이다.
- 조인 대상의 두 테이블 중 데이터가 더 작은 테이블을 Build Input(빌드 입력) 이라 하고,
- 큰 테이블을 Probe Input(프로브 입력) 이라고 한다.
> **❓ 왜 작은 테이블로 Hash Table(해시 맵) 을 생성할까?**
작은 테이블을 메모리에 올려서(+ cpu 기반 주소 접근) 빠르게 탐색하는게 해시 맵의 핵심이다.
따라서 Build 테이블이 크면 메모리에 다 올리지 못하고 오히려 성능이 저하될 수 있다.
> 동작 방식
- 1단계 : build 단계
- 작은 테이블(Build Input)을 읽고
- 조인 키에 해시 함수를 적용
- 결과값을 이용해 해시 테이블을 메모리에 생성
- 동일한 해시 키 값이 여러 행에서 발생하면, 같은 버킷 안에 체인(Linked List) 형태로 연결
- 2단계 : Probe 단계
- Probe Input 의 각 행을 순회하며 조인 키에 동일한 해시 함수를 적용해 해시값 계산
- 동일한 해시 값이 존재하는 버킷만 조회
- 그 버킷 안에서 실제 조인 키 값이 동일한 행을 비교해 매칭
- 일치하는 데이터만 결과로 반환
특징
- NL 조인 Sort Merge 조인 단점 보완
- 조인 대상 테이블에 인덱스가 없고 결과를 정렬할 필요가 없을 때 효율적으로 사용할 수 있는 조인 방법
- Merge Join 을 하기에는 테이블의 크기가 너무 클 때 사용하면 좋다.
- 이 경우, 조인 속도가 NL 조인과 Sort Merge 조인에 비해 빠르다.
❓ 얼마나 빠를까?
데이터의 양이나 특정 조건에 대해서 차이가 있기 때문에 정량적 수치로는 보장할 수 는 없지만,
데이터 양이 커질수록 Nested Loop은 탐색 비용이 기하급수적으로 증가하지만, 해시 조인은 비교적 완만하게 증가한다.
해시 조인은 Sort Merge 조인보다 대량 정렬 부담이 작다.
- 이 경우, 조인 속도가 NL 조인과 Sort Merge 조인에 비해 빠르다.
- Hash Function 사용
- 해시 함수: 같은 입력값에 대해 같은 출력 값을 보장하는 함수
- 다른 입력 값에 대한 해시 출력이 같을 경우 해시 출동이 발생하면 해당 값이 해시 버킷에 들어가고 해시 버킷에 들어간 값들 중 해시 값이 동일한 값들은 체인으로 연결된다.
❓ 해시 충돌은 오류 아닌가?
Hash Join에서는 충돌을 허용하면서도 정확한 조인을 보장하는 구조로 설계.- DB 해시 조인에서는 해시 함수가 단순히 버킷(bucket) 을 분류하기 위한 역할만 한다.
- “완벽히 구분하지 않아도, 같은 해시값끼리 모아놓고 나중에 진짜 비교하면 된다”
- 다른 입력 값에 대한 해시 출력이 같을 경우 해시 출동이 발생하면 해당 값이 해시 버킷에 들어가고 해시 버킷에 들어간 값들 중 해시 값이 동일한 값들은 체인으로 연결된다.
- 해시 함수: 같은 입력값에 대해 같은 출력 값을 보장하는 함수
- Hash Table 사용
- 해시 버킷으로 구성되 배열.
- 해시 테이블은 데이터를 빠르게 처리할 수 있지만, 메모리를 많이 사용하는 단점이 있다.
- 해시 테이블은 생성 후 조인이 끝나면 곧바로 소멸하여 재활용이 불가능 하다.
- 동등 조건 필요
-
해시 조인 종류
아래와 같이 4가지 계획이 존재하며, 옵티마이저가 Build Input 크기에 따라 1번 부터 4번까지 순차적으로 점차 전환하며 실행한다.
- In-Memory Hash Join(인 메모리 해시 조인)
- 해시 테이블을 메모리에 유지할 수 있는 경우의 조인 방법
- build input을 스캔하여 해시 테이블을 생성한다.
- 해시 함수를 통해 Probe input을 스캔하여 읽은 데이터로 해시 테이블을 탐색
- 해시 값으로 버킷을 찾아가 해쉬 체인을 스캔하며 데이터 탐색
- 해시 테이블을 메모리에 유지할 수 있는 경우의 조인 방법
- Grace Hash Join(유예 해시 조인)
- 해시 테이블을 저장할 메모리가 부족해서 디스크가 필요한 경우의 조인 방법이다.
- 이 때 파티션 단계와 조인 단계 두 단계로 나누어 진행한다. (파티션 & 조인)
- 파티션 단계
- where 조건으로 양쪽 테이블을 필터링한다.
- 해시 함수를 적용해서 해시 값에 따라 파티셔닝 한 후, 각각의 파티션 별로 Tempdb 에 임시 파일로 저장한다.
- 각 테이블에는 동일한 해시 함수가 적용되며, 같은 해시 키를 가지게 된다. 이러한 두 파티션을 Partition Pair 라고 한다.
- 이 파티션 단계에서 양쪽 집합을 모두 읽어 Tempdb 에 저장해야하므로 In-Memory Hash Join 보다 성능이 크게 떨어진다.
- 조인 단계
- Partition Pair 에서 한 쪽의 파티션 파일에 대해 해시 함수를 적용하여 해시 테이블을 생성한다.
- 이 때 옵티마이저의 판단에 따라 Build Input, Probe Input 의 테이블이 정해진다.
- Partition Pair 에서 반대쪽 파티션 파일의 row 를 하나씩 읽어가며 해시 테이블을 탐색한다.
- 이 과정을 모든 Partition Pair 에 대한 처리가 완료될 때까지 반복한다.
- In-Memory Hash Join(인 메모리 해시 조인)
- Recursive Hash Join(재귀 해쉬 조인)
- Tempdb 에 있는 Partition Pair 끼리 조인을 수행하려고 더 작은 파티션을 메모리에 올리는 과정해서 또 메모리를 초과하는 경우, 추가적인 파티셔닝 단계를 수행한다.
- Hybrid Hash Join
- Build Input 이 가용 메모리보다 조금 밖에 크지 않다면, In-Memory Hash Join 과 Grace Hash Join 요소가 결합되어 조인한다.
4. SQL 실행 계획
실행 계획이란 사용자가 SQL을 실행하여 데이터를 추출하려고 할 때 옵티마이저가 수립하는 작업 절차이다.
- 실행 계획은 여러 가지 단계로 이루어져 있는데 이것을 스텝이라고 한다.
- 각각의 스텝에는 그 단계에서 어떤 명령이 수행되었고 총 몇 건의 데이터가 처리되었으며 이 처리를 위해 얼마만큼의 비용과 시간이 소요되었는지를 표시한다.
4.1 옵티마이저(Optimizer)의 역할
옵티마이저는 쿼리를 보고 가장 빠를거 같은 경로를 선택한다.
- 옵티마이저가 고려하는 요소
- 통계 정보(카디널리티, 블록 수, 인덱스 유무 등)
- 조건절 형태 (=, BETWEEN, LIKE 등)
- 조인 방식(해시 • NL • 소트머지)
- SCAN 방식(ROWID, INDEX, FULL)
- 정렬 필요 여부
- 병렬 처리 가능 여부
- 옵티마이저의 목적
- 최소 비용(Cost)
- 최소 IO
- 최소 CPU 사용량
- 최소 블록 읽기 수
동작 시나리오
// EMP : 사원의 기본 정보가 담김
// DEPT : 부서 정보가 담김(EMP와 1:N 관계를 가지는 참조 테이블)
// SALGRADE : 급여 범위를 등급으로 나누어 놓은 테이블(lookup)
SELECT e.empno, e.ename, d.dname, s.grade
FROM emp e
JOIN dept d ON e.deptno = d.deptno
JOIN salgrade s
ON e.sal BETWEEN s.losal AND s.hisal
WHERE e.job = 'SALESMAN';- EMP 테이블에서 “영업사원(SALESMAN)”을 먼저 찾고,
- 해당 사원이 속한 부서를 DEPT 테이블에서 조인하고,
- 그 사원의 급여가 어느 등급(SALGRADE)에 속하는지 확인한 뒤
- 최종적으로
- 사번, 이름, 부서명, 급여등급을 결과로 반환하는 SELECT
4.2 실행계획 읽는 법 (룰 3가지)
DBMS가 만든 작업 순서(Operation) 리스트
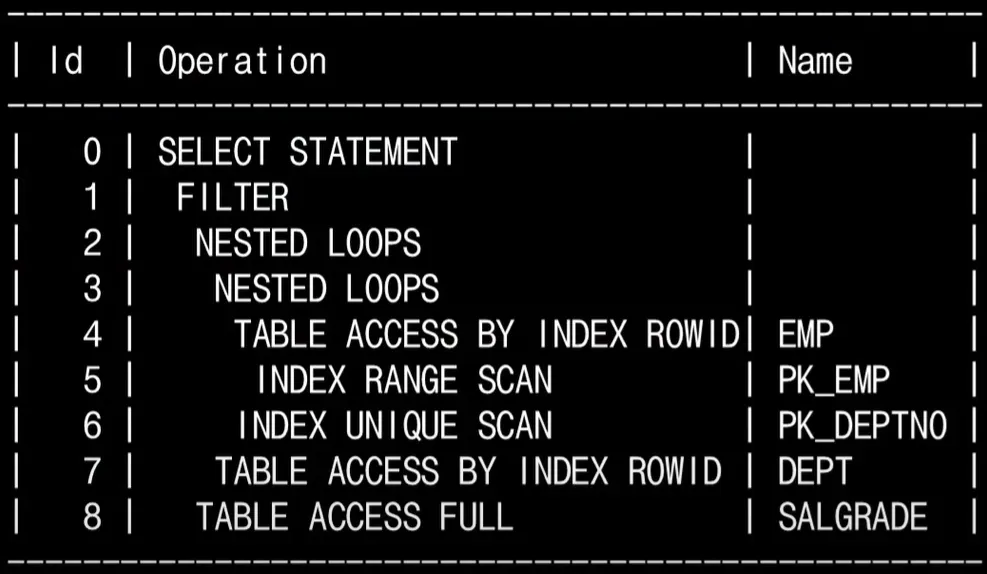
Id, Operation, Name으로 구성됨.
- Operation = 어떤 작업인지
- Name = 테이블 또는 인덱스 이름
- Id = 스텝 고유 번호 (이게 트리 구조에서 노드 번호)
- SQL 실행계획은 트리 구조다.
- 위 → 아래로 훑으면서 가장 먼저 실행될 스텝을 찾는다.
- 같은 깊이(들여쓰기)는 위 → 아래 순.
- 들여쓰기가 되어 있다면 가장 안쪽 → 한 단계씩 밖으로 나온다.
- 5 -> 4 -> 6 -> 3 -> 7 -> 2 -> 8 -> 1 -> 0
4.3 실행계획 해석 (조인 단위)
- 5 -> 4 -> 6 -> 3 -> 7 -> 2 -> 8 -> 1 -> 0
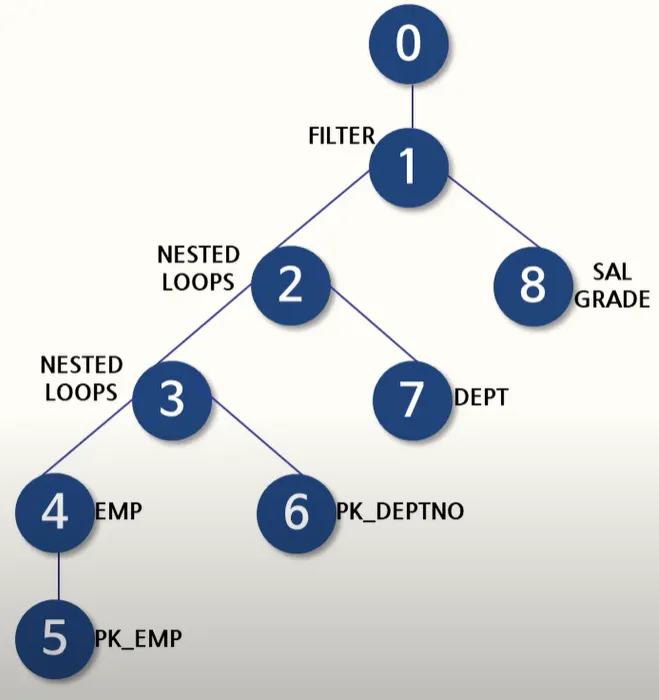
STEP 1 - EMP 테이블에서 시작하는 첫 번째 Nested Loop
노드 5 : PK_EMP
- EMP 테이블의 PK 인덱스 스캔
- 조건에 맞는 ROWID 획득
노드 4 : TABLE ACCESS BY INDEX ROWID EMP
- ROWID 기반으로 EMP 데이터 실제 읽기
- → EMP 한 행씩 읽기 시작
노드 3 : NESTED LOOPS
- EMP의 각 행마다
- 다음 단계(DEPT 조회)를 반복하는 루프 시작
→ 이 박스 전체는 “EMP를 기반으로 조인을 시작하는 루틴”을 의미함.
💡왜 EMP가 첫 번째 드라이빙 테이블인가? (Optimizer Reason)
- WHERE 조건(e.job='SALESMAN')의 선택도가 높음
- 먼저 EMP를 읽으면 이후 조인 비용이 대폭 감소.
- EMP는 WHERE 조건으로 row 수가 가장 많이 줄어든다.
- 드라이빙 테이블로 쓰기 최적.
STEP 2 - EMP + DEPT 조인 루틴
노드 6 : PK_DEPTNO
- EMP.deptno 값을 기준으로
- DEPT의 PK 인덱스 탐색
노드 7 : TABLE ACCESS BY INDEX ROWID DEPT
- 인덱스에서 얻은 ROWID로
- DEPT 테이블의 실제 행을 읽음
노드 2 : NESTED LOOPS
- EMP + DEPT 조인 결과 생성
- 다음 SALGRADE 조인 루틴으로 전달
→ 이 박스는 “EMP + DEPT 조인 결과를 만드는 단계”.
💡왜 DEPT는 인덱스를 사용해 Nested Loop로 조인되었는가? (Optimizer Reason)
- DEPT는 PK(DEPTNO)에 인덱스가 기본적으로 존재
- EMP에서 이미 row 수가 크게 줄었기 때문에
드라이빙 테이블의 row가 적고, 조인 대상이 PK 인덱스를 가질 때 최적
→ 이 조건에 딱 들어맞는다!
STEP 3 - SALGRADE + FILTER + 최종 SELECT
노드 8 : SALGRADE TABLE FULL SCAN
- SALGRADE는 로우 수가 매우 적기 때문에 Full Scan 하는 경우가 많음
- BETWEEN (losal ~ hisal) 조건을 만족하는 등급 찾기
노드 1 : FILTER
- SALGRADE와 매칭한 후
- WHERE 조건 같은 추가 필터링 수행
노드 0 : SELECT STATEMENT
- 최종 결과 반환
→ 이 박스는 “조인의 마지막 단계 + 필터링 + 결과 출력”을 의미함.
💡 왜 SALGRADE는 Full Scan으로 선택되었는가? (Optimizer Reason)
- SALGRADE는 극히 작은 정적 테이블(5~6행)
- 인덱스 탐색보다 Full Scan이 오히려 빠름
- 조건이 BETWEEN 범위 매칭
- 이런 조건은 인덱스의 선택도가 낮다.
4.4 실행계획 확인 방법(오라클)
방법은 3가지다:
- AutoTrace
- SQL 실행 + 실행계획 + 통계를 터미널에서 즉시 확인
- 가장 간단한 방식
- SQL Trace + tkprof
- 대기 이벤트, 바인드 변수, 실제 elapsed time까지 확인
- 가장 강력한 성능 분석 도구
- EXPLAIN PLAN / dbms_xplan.display / display_cursor
- PLAN_TABLE 기반으로 실행계획 확인
- display_cursor는 “실제 실행된 계획”을 볼 수 있음
