웹의 역사에서, 우리가 아는 웹사이트 형태 (www;worldwide web)는 1990년대 만들어 졌다. (역사가 생각보다 짧았다.)
"1989: Tim Berners-Lee invents the Web with HTML"
Html, http, url을 만들었다. 이게 웹의 시작이라고 생각하면 된다.
'인터넷'이라는 개념은 이보다 앞선 1950년대 나타났는데, 물리적으로 분리된 컴퓨터
e.g. 미국, 한국 컴퓨터가 네트워크로 연결되어 데이터를 주고 받을 수 있는 시스템을 생각해 보자.
www는 단순 데이터 뿐 아니라 문서도 포함하고 있다.
HTTP(Hyper text transfer protocol)를 한국어로 그대로 해석하면
=> page끼리 hyper link를 통해 연결되어 있어 문서를 서로 주고받고 할 수 있는 것
*html은 뭐냐면 hypertext transfer protocol
-hypertext는 html이고
-transfer은 전송
-protocol은 규약, 약속이다.
url은 사람이 알기 쉬운 주소로 만들어 준것이다. 매번 html 이름을 알 순 없으니까
즉, html을 전송하기위한 하나의 규칙이다.
(왜 이게 필요하지?)

인터넷은 물리적 한계를 벗어나 데이터를 전송한다는 것을 의미하는데,
데이터가 전송된다는 것이 무슨 뜻일까?
예를들면, 내 생일인데 편지로 내 생일을 알려주려고 한다. 그럼 그 편지 내용은 '19970301'일 수 있고 '970301'일 수 있다. 정보에 상관없이 누구는 알아볼 수 있고 아닐 수 있다.
이것이 통일이 필요한 이유이다.
인터넷은 text message가 서로 전송되는데, 서로 이해할 수 있는 규격이 필요하다.
컴퓨터끼리도 이해할 수 있는 규격이 필요하다.
http는 html을 보낼 수 있는 프로토콜이다.
컴퓨터끼리 데이터를 주고 받는 것은 마법이 아니라, 글이 가는데 ‘영어’ ‘한국어’이런 것들이 가는데
html이라는 규격에 맞게 가는 것이다.
———————————————————
http에 대해 더 자세히 알아보면 크게 두가지 속성을 가진다.
1. HTTP는 Resopnse & request process이다.
2. HTPP는 Stateless protocol
Response 와 request로 나눠진다.
컴퓨터 A가 컴퓨터B에게 요청을 보내고 응답을 받는 이 과정이 http이다.
위의 사진을 보면 http가 2번 일어난다. FE-WB , BE-WB 이렇게
request와 response 한쌍이 http이다.
Request:
쉽게 생각하면 client, user가 검색 요청을 하면 WB가 BE의 API에게 요청을 한다.
response:
BE가 WB로부터 응답을 받고 이것을 rendering해서 FE에게 응답을 전해준다.
- 주의: 프론트엔드가 직접 백엔드에게 서버를 요청하는 것이 아니다.
—————————————————————
Html의 두번째 속성은
형태가 없다는 것이다. (Stateless)
예를 들어 네이버를 보면, 이런 http 요청과 응답이 굉장히 많을 것이다.
로그인, 검색, 메일, 뉴스 클릭 etc. 기능이 많으니까.
그런데 이 통신들은 독립적이다. 즉,자기 통신 이외에 다른 통신이 있다는 것을 모른다.
그러면, 이게 대체 왜 필요하지?????
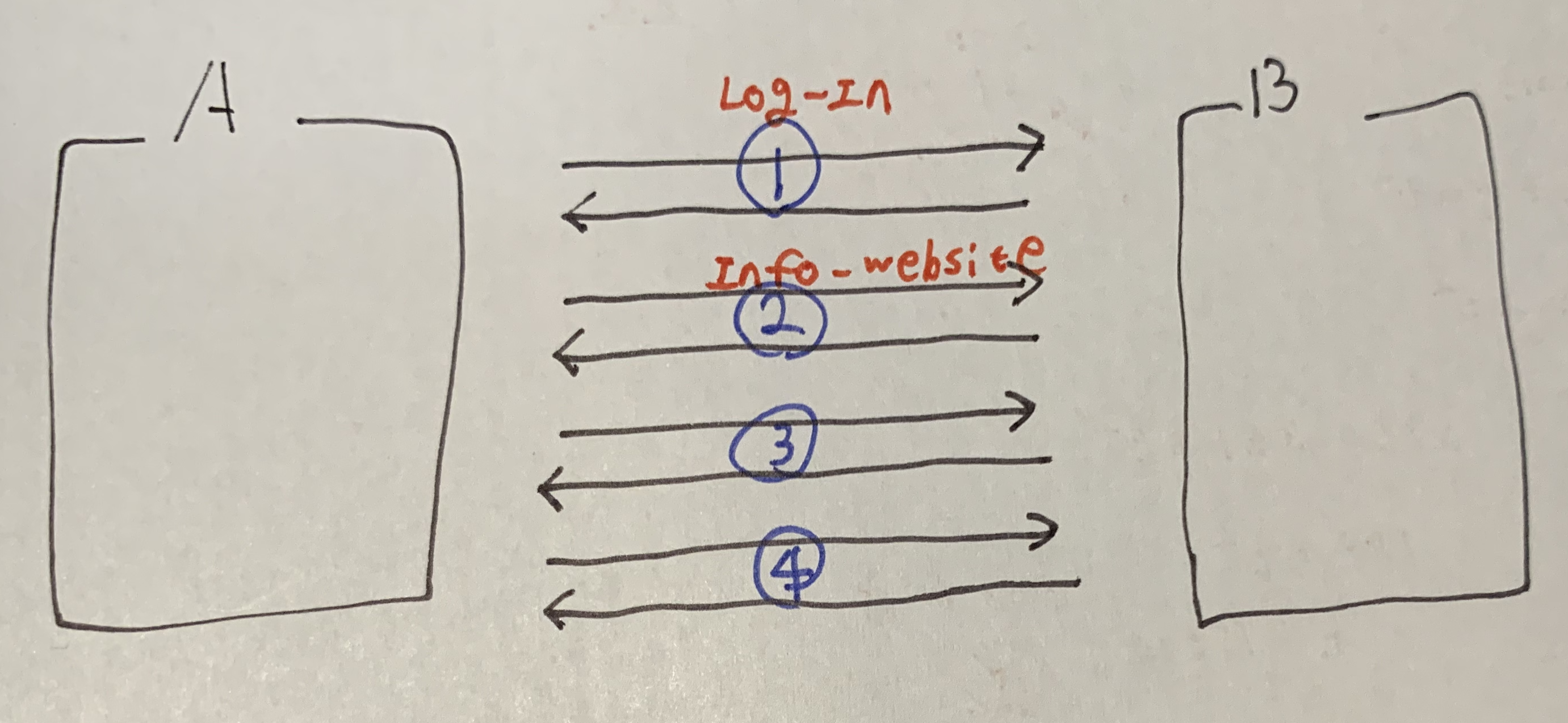
e.g. 내가 주식 정보 웹사이트에 접속한다고 하면 일단 로그인한 사람에게만 열려야 할 것이다. 그런데 주식 정보 웹사이트 접속 요청을 하면 내가 이전에 로그인 요청,응답을 받았는 지 모르기 때문에 요청만 하면 열리는 경우가 발생할 것이다. 난처하네.....
어떻게 해결할까??
그것은 웹브라우저가 주식사이트 정보를 요청할 때, 이전의 로그인 정보를 같이 보내야한다. (이따가 나오겠지만, headers에 요청 정보를 meta정보로 첨부해서 보낸다.)
- 참고로 그렇다면 요청하는 주체인 웹브라우저는 같이 보낼 로그인 정보를 저장하고 있어야 하는데, 그 저장 장치가 쿠키이다.
————————————————————————
앞서서 http가 text라고 했는데 그게 규격이 있다고 했다.
그럼 그 규격을 알아보자!!!!!
-HTPP REQUEST
http의 request 구조는 start line, headers, body로 나눠진다.
start line은 또 3가지로 나눠지는데, 아래와 같다.

GET : HTTP method
http가 요청할 때 뭘 해달라고 하는지 목적을 나타낸다.
GET, POST, DELETE가 주로 쓰이는데, GET은 정보를 달라! POST는 정보를 생성해 달라! DELETE는 정보를 삭제해 달라! 이런 목적을 가지고 보내는 편지이다.
/search : request target
api의 기능을 의미한다. 딱 보면 어려우니 예시를 들어보자.
내가 우리집에 초대를 하려고 하는데, 선문빌라만 가르쳐 주어서야 우리 집안 까지 못 들어온다. 그러니 몇 동 몇 호인지 정확히 알려줘야한다.
마찬가지로 Naver에서 제공하는 function을 이용하기 위해서는 정확히 어떤 기능을 원하는지 알아야한다. 그것이 밑에서 설명하는 것이다.
- Naver.api가 만약 api.naver.com이라면, 이 부분은 Domain이라고 부르고 /search 부분을 endpoint라고 한다.
HTTP/1.1: HTTP Version
말 그대로 현재 이용하는 HTTP의 버젼이다.
전문용어로 위의 naver 기능들을 end라고 한다. 한국어로 저쪽이니까 URL기준으로는 API쪽이 되는 것이다. 그 end 중 하나(/search)는 endpoint라고 한다.
서버와 서버가 있을 때, 상대쪽 end가 domain이고 endpoint가 domain에 있던 기능이다.
Url기준으로 url은 mypoint이다.
————————————————————
Search함수를 내 컴퓨터에서 실행하고자 하면 result =search(‘a’)를
해서 실행하면 되는데, 만약 미국에 있는 사람이 설계한 search함수를 쓰고 싶다고 하면
일단 미국에 있는 컴퓨터에 접속해야 하니까
일단 api.naver.com/search하고 a라는 parameter를 넣어주세요 하고 요청해야한다.
그러면 받는 값으로 result는 응답으로 받는다. 이렇듯 원격으로 뭔가 주고 받고 하려면
필요한 것이 api이고 http이다.
—————————————————
GET /search HTTP/1.1
request요청은 3부분으로 나눠져 있는데,
get은 받길 원한다.
/search는 search정보를 받길 원한다.
http/1.1 http버젼 1.1로 search정보를 받길 원한다.
이렇게.
=———————————————————
header는 아까 네이버 할때, 이전 로그인 정보랑 같이 주식 정보 회사로 보내야 한다고 했다.
host의 header값은 value인데 이것이 바로 domain이다.
domain과 endpoint를 합치면 완벽한 주소가 된다.
User-agent는 클라이언트의 정보 웹브라우저에 대한 정보이다. 이 정보는 수집하는 사람이
있는데, 그것은 바로 사용자가 어떤 우분투에서 보내는 정보랑, mac에서 보내는 정보랑
다르다. 이렇게 정보를 취합하면 누가 mac을 사용하는지 알 수 있다. 나중에 광고할 때
이런 사람들에게 한다.
—————————————
요청을 했으면 받아야 하는데, 그 받는 타입을 정하는 것이 accept이다.
———————————————
connection요청
Content-type은
Content-length
————————————————
Accept
Accept-encoding은 파일을 주고 받을 때, text로 보내고 받는다고 했는데, 그게 너무
크기가 크니, 압축을 해서 달라고 요청하는 것이다.
——————————————————
이제 body이다.
보내는 html의 실제 내용이 들어간다. 여러가지가 들어갈 수 있는데 주로
json의 형태로 된다.
get요청일 경우에는 달라는 거니까 내용이 없다. 내가 받을 때 내용이 딸려서 오겠지.
——————————————————————
로그인을 할 때, 내 id, pw는 header에 들어간다. 그것은 일단 meta정보인데 이 사람이 로그인이
되어있는지 아닌지 알아야 하기 때문이다.
———————————————————————
response도 3가지 구조를 가지고 있다.
처음은 Status line이다. 왜 status냐면 요청에서 했던 status에 대해 보여줘야 한다. 그래야 무슨 행동을 할 지 결정하니까.
http버젼
Status code는 응답인데, 200은 응답이 됬다. 500은 서버 오류가 났다. 이렇게 보여준다.
Status text는 응답을 영어로 보여준다.
404가 나오면 요청하는 주소가 없다는 것이다.
——————————————————
Headers에서는
server를 쓰는데 왜냐면 응답을 해주는 곳이기 때문이다.
404 not found응답 구글에서 잘못된 정보를 입력하면 깨진 로봇이 나오는데 그 응답이 웹사이트가 아니라 터미널에서 보면

이렇게 나오게 된다.
————————————————————————————————
http는 함수를 쓰는 것과 같은데
Rest = search (parameter)에서
우리는 parameter을 request라고 하고 rest는 response이다.
—————————————————————————————
get과 post method가 자주 쓰인다.
get요청은 data를 받을 때, 검색할때, 강아지 사진 클릭하면 강아지 정보를 띄우는 것
Post는 생성하고 수정할 때 쓰인다. blog나 login할 때.
put 잘 안 쓰임
delete는 데이터 삭제 요청
—————————————————
Status code를 보면 개발자가 받은 요청에 대해 확인하고 코드를 보내줘야한다.
그래서 잘 알아야한다.
uri는 request까지 들어간 ip주소라고 보자.
————————————————————————
Restful api에 대해 알아볼 것이다.
그것은 패턴이다.
endpoint주소를 결정하는 패턴이다.
예를 들면
User 라는 정보가 있으면 그것은 해당 유저의 id가 있고 name등이 있다.
회원가입을 하면 생성하는 기능 new-user 기능
특정 user정보를 읽어들이는 기능
모든 user들의 정보를 읽어들이는 기능
특정 user 정보를 지우는 기능이 있다.
우리는 이 endpoint기능에 대한 이름(id)을 정해야 한다.
/search 이것이 endpoint name이었으니까
주소에 명사를 넣는다. 동사부분은 http method로 해결한다. Target 주소에 동사 안 넣는다.
Post /user
Get/ user/1
Get/ users
delete/ user/1. id 1번의 유저 정보를 지워라
