알고리즘
1.[알고리즘] 그래프
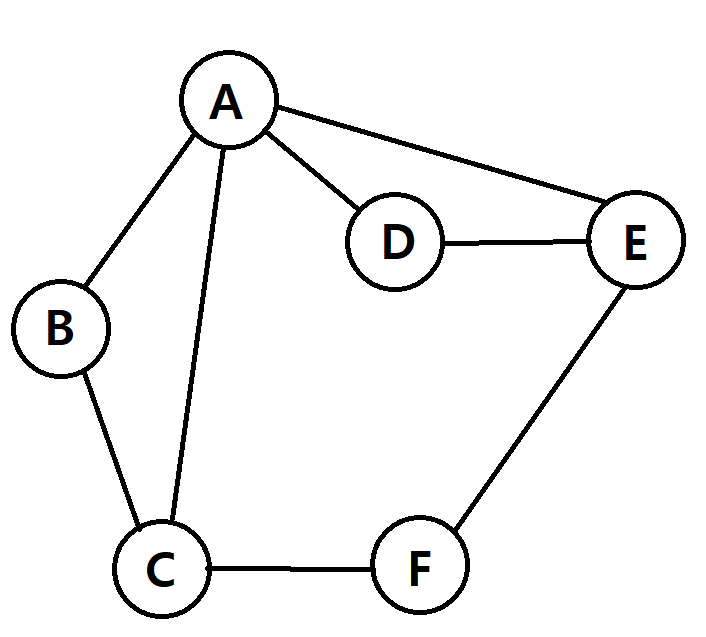
알고리즘 그래프
2.[알고리즘] 레드 블랙 트리(Red-Black Tree, 적흑나무)
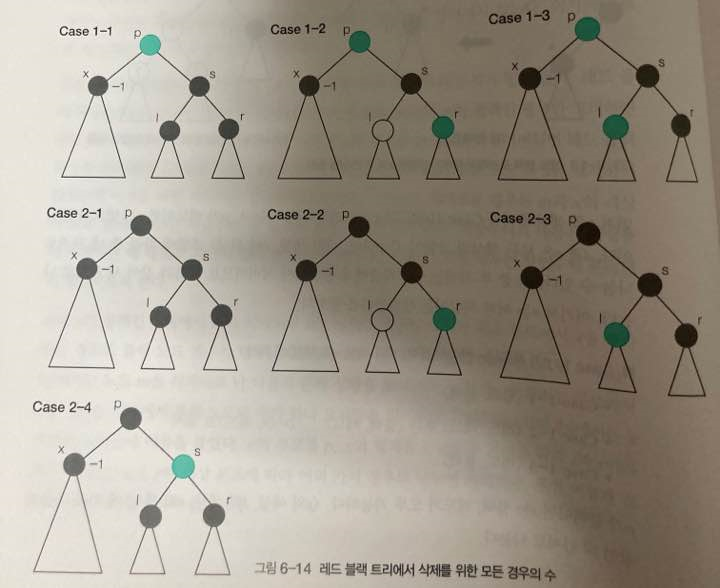
저번 수업시간에 배운 레드 블랙 트리 우리나라 말로는 적흑 나무에 대해 글을 쓰고자 한다.한국어로는 적흑나무인데 너무 없어 보여서 레드 블랙 트리라고만 명칭 하겠다.이진 검색 트리는 저장과 검색에 평균 Θ(logn) 시간이 소요되지만 운이 나쁘면 트리의 모양이 균형을
3.[알고리즘] 이진 검색 트리
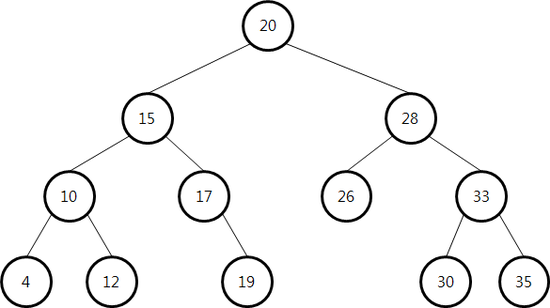
이진 검색 트리에는 3가지 특징이 있다.이진 검색 트리의 각 노드는 키 값(=노드 값)을 하나씩 갖는다. 각 노드의 키 값은 모두 달라야 한다.최상위 레벨에 루트 노드가 있고, 각 노드는 최대 두 개의 자식 노드를 갖는다.임의의 노드의 키 값은 자신의 왼쪽에 있는 모든
4.[알고리즘] 해시 테이블

해시 테이블은 (Key, Value)로 데이터를 테이블 형태로 저장하는 자료구조이다.해시 테이블은 Key값에 해시함수를 적용해 배열의 고유한 Index를 생성하고, 이 Index를 이용하여 값을 저장하거나 검색한다.실제 값이 저장되는 장소를 버킷 or 슬롯이라고 한다.
5.[알고리즘] 선택 알고리즘
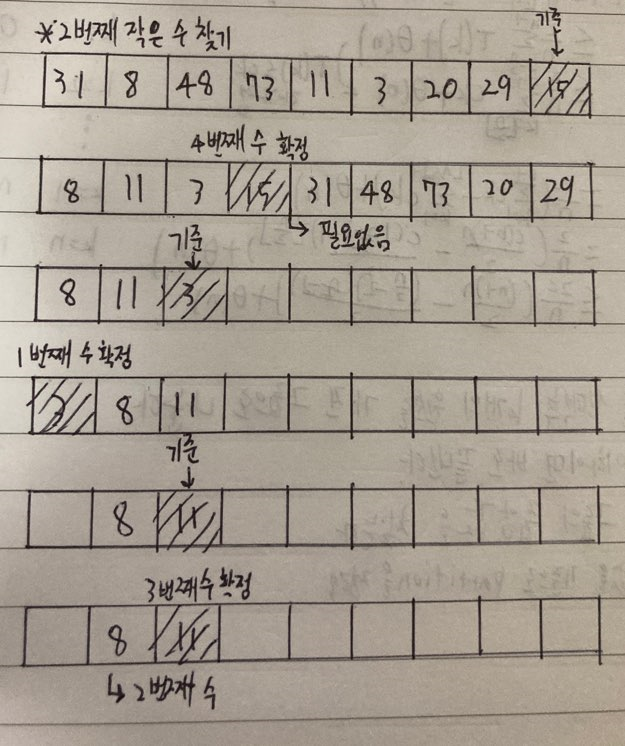
선택 알고리즘은 n번째로 작은(or 큰)원소를 찾는 알고리즘이다.선택 알고리즘은 동작 방식이 퀵정렬 알고리즘과 비슷하다.제일 우측값을 pivot으로 정하고 pivot보다 큰 값, 작은 값의 배열을 하나 만든다.pivot값을 그 가운데에 대입한다.(이로써 pivot의 I
6.[알고리즘] 힙 정렬
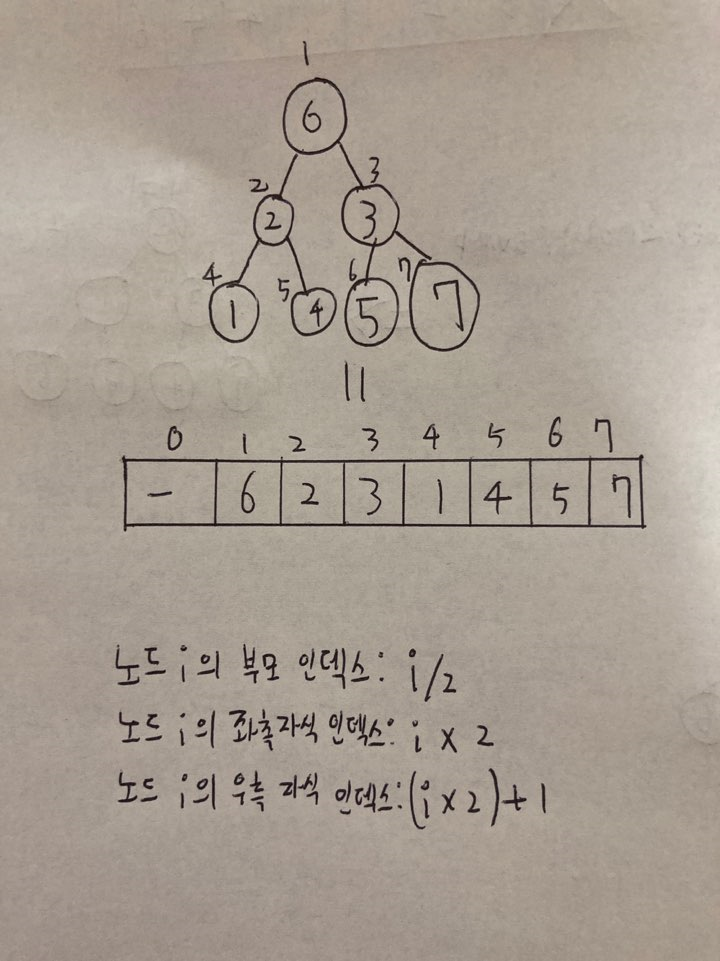
힙 정렬은 힙이라는 특수한 자료구조 그 중에서도 이진완전트리를 사용한다.힙에는 2가지 종류가 있는데 하나는 최대힙과 최소힙이다. 이는 값의 방향성의 차이지 큰 차이는 없다.최대힙 : 부모 노드가 자식 노드보다 큰 값을 가지는 힙최소힙 : 부모 노드가 자식 노드보다 작은
7.[알고리즘] 합병 정렬, 퀵 정렬
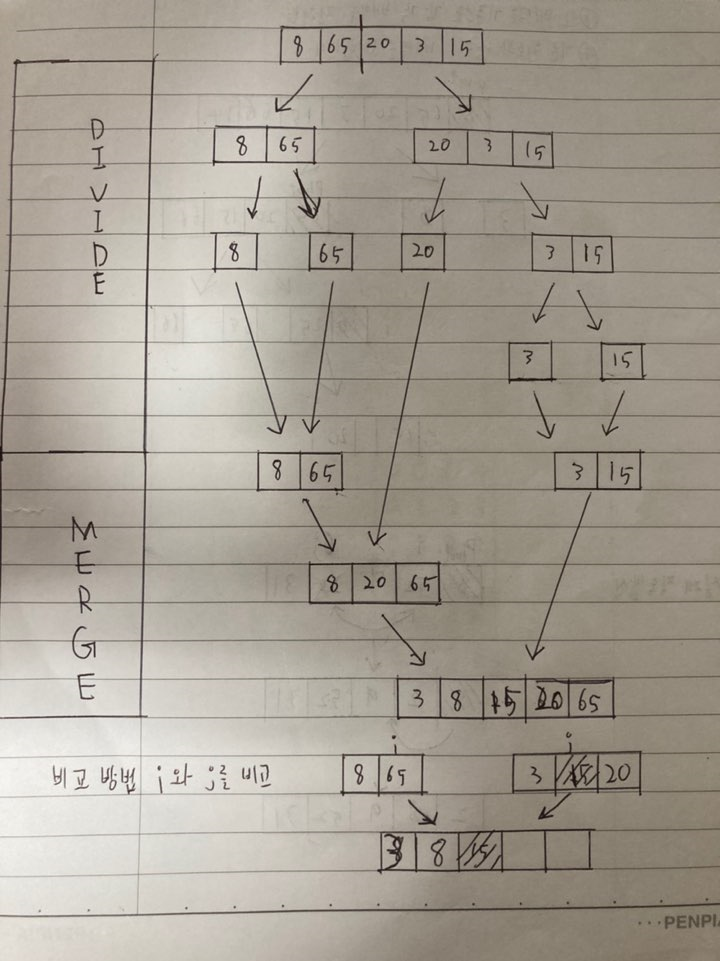
지난번에 포스팅한 정렬들은 통상적으로 Θ(n\*\*2)의 복잡도를 가지는 정렬이였다면이번에 포스팅할 정렬들은 쉽게말해 더 고급(?)정렬이라 볼 수 있다.여기서부터는 재귀 개념이 사용된다.책에서는 합병이 아닌 병합이라 표현하지만 통상적으로 합병이라 많이 쓰기 때문에 표현
8.[알고리즘] 선택정렬, 버블정렬, 삽입정렬
원소들을 번호순이나 사전 순서와 같이 일정한 순서대로 열거하는 것을 정렬 알고리즘이라고 한다.즉 쉽게 말해서 말그대로 순서대로 배열한다.숫자가 크거나 작은 순a~z순 같은 느낌이다.선택 정렬은 정렬 알고리즘 중에서 간단한 알고리즘 중 하나이다.배열에서 가장 작은 값을
9.[알고리즘] 점근적 표기법 (o-표기법, ω-표기법)
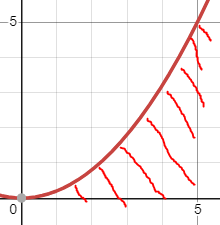
우선 앞에 설명한 개념인Big O 와 little o의 차이점을 간단하게 설명하자면O는 f(n)에 대해 >=를 만족하는 것을 표기한다면o는 f(n)에 대해 >를 만족하는 것을 의미한다.지난번 그래프를 다시한번 가져와서 비교해보자면이 그래프의 선을 f(n)라 했을 때 O
10.[알고리즘] 점근적 표기 및 시간 복잡도

오늘 정리할 개념은 점근적 표기와 시간 복잡도이다.우선 이 개념을 공부하기 이전에 우리가 알아야 하는 것이 있다.그것은 바로재귀(자기 호출)이다.재귀 호출은 컴퓨터 과학 이론의 근간을 이루는 중요한 개념으로 어떤 문제를 해결하는 과정에서 자신과 똑같지만 크기가 더 작은
11.[알고리즘] 알고리즘(Algorithm)이란?
요즘은 알고리즘이란 말을 다들 쉽게 씁니다.특히 유튜브가 대중화되면서 '유튜브 알고리즘'이라는 말에서 많이 듣는것 같습니다.하지만 많은 사람들에게 "알고리즘이란 무엇이냐?"라는 질문을 던지면 쉽게 대답을 못하기도 합니다.그렇다면 알고리즘이란 무엇일까요?우선 알고리즘을