파이썬의 자료구조
파이썬에는 다양한 자료구조가 존재한다. 각 자료구조의 특징을 알아보고 파이썬에서 어떻게 활용되는지 알아보자.
Array
array는 파이썬에 기본적으로 내장되어있지 않다. 그 이유는 "Simple is the best"라는 파이썬의 개발철학과 관련되어있다. 뒤에 설명할 list는 여러 부분에서 array보다 장점이 많다. 그래서 굳이 특별한 이유가 아니면은 array를 사용하지 않고 list를 사용한다. 그래서 파이썬은 simple하게 list만을 만들어놓았다.
하지만 굳이 특별한 이유로 array를 사용해야 하는 순간이 온다. 그때 array를 사용하기 위해서는 외부 라이브러리를 사용해야 한다. array를 사용하는 가장 대중적인 라이브러리는 numpy이다.
import numpy
var = numpy.array([1,2,'a',4])
-> ['1','2','a','4']구현
Array의 핵심은 동일한 크기의 element가 메모리상에 연속적으로 존재한다는 점이다. 메모리상에 연속적으로 존재하는 element에 메모리 주소를 이용해 쉽게 접근하기 위해 서로 크기가 같을 수밖에 없는 하나의 자료형을 이용한다.
특징
Array의 구현 핵심을 생각해보면 다음과 같은 특징이 있다는 것을 알 수 있다.
1. 하나의 자료형밖에 담을 수 없다.
2. element 삭제시 빈공간이 생겨서 메모리를 효율적으로 사용할 수 없다.
3. element로의 접근이 빠르고 따라서 array끼리의 연산이 빠르다는 장점이 있다. 이 장점이 굳이 파이썬 자체적으로 구현하지 않은 array를 외부 라이브러리를 가져오면서 사용하는 이유이다.
List
var = [1, 'a', [1, 2], 4]
var = list()파이썬의 가장 대표적인 자료구조로 array의 상위호완적인 부분이 많다. 자료구조의 이름이 list라 처음에는 파이썬의 list가 컴퓨터과학에서 다루는 list를 그대로 구현해놓아 컴퓨터과학의 list처럼 작동하는줄 알았다. 하지만 파이썬의 list는 컴퓨터과학의 list처럼 동작하지만 전혀 list답게 구현되어있지 않다. 오히려 파이썬스럽게 구현되어있다.(simple하게 구현했다는 뜻이 아니다 자세한 설명은 아래에서...)
구현

파이썬에서의 list의 핵심은 LinkedList처럼 빈공간을 허용하지 않는 동적 포인터 array라는 점이다. array가 연속적인 메모리에 데이터를 넣었던 것처럼 list는 연속적인 메모리에 포인터를 담았다. 각각의 int, float, string, list 등등 다양한 데이터를 가리킨다. list는 이런 식으로 데이터를 저장한다.
그렇다면 왜 이렇게 구현해놓았을까? 포인터 array를 담으면 어떤 장점이 있을까? 바로 여러 종류의 자료형을 담을 수 있다는 점이다. 더 정확히 말하자면 실제로는 한 종류의 자료형을 넣지만 여러 종류의 자료형을 넣은 것처럼 보일 수 있다는 점이다. 앞서 설명했듯 array는 인덱스를 이용해서 element에 접근하기 때문에 한 종류의 자료형밖에 담지 못한다. list는 element로 담을 수 있는 한 종류의 자료형으로 포인터를 넣고 각 포인터가 여러 종류의 자료형 데이터를 가리키기 함으로서 array에 다양한 종류의 자료형을 넣을 수 있다.
앞서 파이썬의 list가 파이썬스럽게 구현되었다고 했다. 파이썬에서 변수를 선언하고 변수에 데이터를 넣을 때 C언어와 달리 데이터를 직접 넣는 것이 아니라 데이터를 가리키는 포인터를 넣는다. 이런 파이썬의 변수 선언 방식이 list가 데이터를 넣는 방식과 원리가 같다.
이런 구현은 컴퓨터과학에서 배운 list의 구현방식과는 다르다. 그렇다면 왜 파이썬의 list는 list라고 불리는 것일까? 실제 구현은 동적 포인터 array로 되어있지만 동작은 list처럼 동작하도록 만들었기 때문이다.
컴퓨터 과학의 list처럼 동작하는 파이썬의 list
먼저, 컴퓨터과학의 list처럼 element간의 빈공간을 없애기 위해 element 간의 빈공간이 존재하지 않도록 만들었다. 파이썬의 list는 element 삭제시 생기는 빈공간을 자동으로 매꾸고, element 삽입시 뒤의 element를 하나씩 밀어내어 element간의 빈공간 없이 연속적으로 사용할 수 있다.
그리고 컴퓨터과학의 list의 크기가 동적인 것처럼 파이썬의 list도 element의 개수에 따라 list의 크기가 동적으로 변하는 동적 array로 구현해놓았다.
특징
List의 구현 핵심을 생각해보면 다음과 같은 특징이 있다는 것을 알 수 있다.
1. element 사이의 빈 공간이 없다. (컴퓨터과학 list의 장점)
2. 여러 종류의 자료형을 담을 수 있다. (컴퓨터과학 list의 장점)
3. 크기가 동적이다. (컴퓨터과학 list의 장점)
4. index를 이용한 element의 조회가 빠르다. (array의 장점)
5. iterable한 sequence 이다.
그렇다고 파이썬 list에 array와 컴퓨터과학 list의 장점만 있는 것이 아니다. 그 둘의 단점 또한 가지고 있다.
element 사이의 빈 공간이 없다고 해도 동적으로 크기가 변화는 과정에서 메모리 공간이 낭비될 수 있다.
그리고 element 사이의 빈 공간을 허용하지 않아 원하는 index에 element를 삽입하는 과정이 번거롭다. element를 삽입, 삭제하는 과정에서 element 사이의 빈 공간을 없애기 위해 뒤의 element를 복붙해야 하기 때문이다.
이런 단점이 있음에도 불구하고 컴퓨터과학의 list와 array의 장점을 합쳐 극대화하고 단점은 최소화하였기 때문에 파이썬의 대표적인 자료구조로써 채택된 것이라고 생각한다.
Tuple
var = (1,2,3,4)
var = ()
var = (1)
print(type(var))
#otuput : <class 'int'>구현
List를 이해하면 tuple은 쉽게 이해할 수 있다. Tuple의 핵심은 element를 변경할 수 없는 list라는 점이다.
list와 같이 포인터 array로 구현되어 있다. 하지만 tuple은 element 추가, 삭제가 불가능하기 때문에 동적이지 않고 처음 만들어질 때 element 개수에 따라 크기가 정해져있다.
특징
기본적으로는 list와 같은 특징을 가지고 있다. 하지만 다른 점은
- 수정, 삭제, 추가 등 element에 변화를 줄 수 없다.
- 자료구조의 크기가 동적이지 않고 정적이다.
Hash table
Hash table은 사실 python에서 직접적으로 사용하지 않는 자료구조이다. 하지만 뒤에 있는 dictionary와 set을 이해하기 위해서는 파이썬에서 hash table이 어떻게 구현되어있는지 알아야 하기 때문에 기록을 한다.
Hash table은 hash function과 함께 사용된다. 사실 hash table은 자료구조, hash function은 알고리즘, hash는 이 둘을 아우루는 개념으로 굳이 따지자면 hash는 자료구조가 아니지만 hash table에는 hash function이 항상 함께 따라오기 때문에 hash와 hash table을 딱히 구분하지 않고 사용하기도 한다.
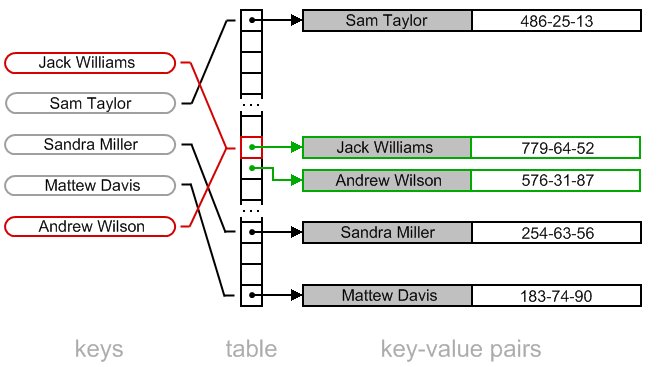
Hash는 위의 사진처럼 어떤 데이터가 있을 때 hash function을 통해 어떤 hash값을 뽑아내고 해당 hash값의 일부를 index로 활용하여 hash table에 그 데이터를 저장한다. hash 충돌이 발생할 경우 다양한 방식으로 이를 처러하는데 python에서는 open addressing의 linear probing을 이용한다. 이 방식을 사용하면 데이터의 개수만큼의 index가 필요하다.
구현
Hash table은 동적 array로 구현되어있는 것 같다. List는 아니라고 생각하는게 hash function으로 나온 hash값을 index로 활용하여 데이터를 삽입, 검색하는 hash의 특성을 고려해 봤을 때 list는 빈공간을 허용하지 않아서 index를 이용해 항상 원하는 곳에 값을 삽입할 수 없기 때문에 hash table이 list는 아닌 것 같다.
동적 array로 구현되어있기 때문에 데이터의 개수에 따라 hash table의 크기가 달라진다. Hash table이 동적으로 변하는 것에 따라 hash function도 그에 맞게 변하는 것 같다. (구체적인 구현 방식은 Cpython 코드를 열어봐야 할 것 같다.)
Hash table이 key 중복을 탐지하는 방법
Hash table은 hash table을 사용하는 dictionary, set에서 key 중복을 허용하지 않기 때문에 기본적으로 key 중복을 탐지하고 피하려고 한다. 그렇다면 hash table은 key 중복을 어떻게 탐지하는 것일까?
먼저 hash값 충돌이 발생했는지 확인한다. hash값의 일부만 index로 사용했기 때문에 hash값 충돌이 발생했다고 key 값이 항상 중복인 것은 아니다. 하지만 만약 key 값이 같다면 hash값 충돌이 발생했을 것이다. 2단계로 만약 hash값 충돌이 발생했다면 실제로 key값을 비교해본다.
특징
- 검색, 삽입, 삭제 등의 작업이 O(1) 시간 복잡도를 가진다.
- key의 중복을 허용하지 않는다.
- hash 값에 따라 index가 달라지므로 데이터의 순서를 보장하지 않는다.
Dictionary
var = {"apple": 0, "banana": 1, "orange": 2}
var = dict()Dictionary는 key와 value쌍을 저장하는 자료구조이다. 컴퓨터 과학의 map을 구현한 것이다.
Dictionary를 사용하는 이유는 어떤 key가 들어있는지 확인하고 + 그 key에 해당하는 value를 찾기 위해서이다.
구현
Dictionary의 핵심은 hash table로 구현되어있다는 점이다.
hash bucket에 hash값과 별개로 key와 value가 저장되어있다.
특징
기본적으로 hash table의 특징을 가지고있다. 하지만 dictionary만의 특징이라고 하면
- key:value 쌍을 저장하고 있다.
Set
var = {1, 2, 3}
var = {1}
var = set()
var = {}
print(type(var))
# output : <class 'dict'>수학의 집합, 컴퓨터 과학의 set을 구현한 자료구조이다.
Set은 dictionary와 매우 비슷하다. 유일한 차이점이라고 한다면 key:value쌍이 아니라 key만 저장한다는 점이다. 따라서 set을 사용하는 이유는 단순히 어떤 key가 들어있는지 확인하기 위해서이다.
구현
Set의 핵심은 key만 저장하는 dictionary라는 점이다.
Set은 dictionary와 똑같이 hash table로 구현되어있다. 유일한 차이점이라면 hash bucket에 key:value 쌍이 아니라 key만 저장하고 있다.
특징
기본적으로 hash table의 특징을 가지고있다. 하지만 set만의 특징이라고 하면
- key를 저장하고 있다.
- 빈 set을 만들려고 var = {} 빈 중괄호를 사용하면 dictionary가 만들어진다.
Hash가 key:value 쌍을 가지고 있으니까 key:value를 가지고 있는 dictionary가 기본값인가보다.
