출처(source) 및 참고
Index의 개념
들어가기에 앞서 개인적으로 닮고 싶은 개발자 중 한 분께서 인덱스를 설명하기 위해 사용하셨던 예제를 똑같이 사용해 보고자 한다.
지금 한 권의 프로그래밍 언어 참고서를 가져와보자.
그리고 책 안에서 목차 없이 배열을 설명하고 있는 페이지를 찾아가야 한다고 생각해 보자. 어떻게 할 수 있겠는가?
아마 우리는 배열을 찾기 위해 책의 앞장부터 한 장 한 장 살펴보아야 할 것이다.
하지만 책에는 목차가 있다. 우리는 책의 목차를 가볍게 살펴보는 것만으로 우리가 원하는 정보를 설명하고 있는 페이지를 바로 찾아갈 수 있다.
이게 바로 인덱스다.
즉, 인덱스란 책에서의 목차 또는 맨 뒷장의 찾아보기 페이지와 같이 특정한 정보의 위치를 미리 기록해두고 빠르게 찾아갈 수 있도록 하는 것이다.
Index의 적용
인덱스는 데이터베이스 테이블의 특정 컬럼(Column)에 적용되어진다.
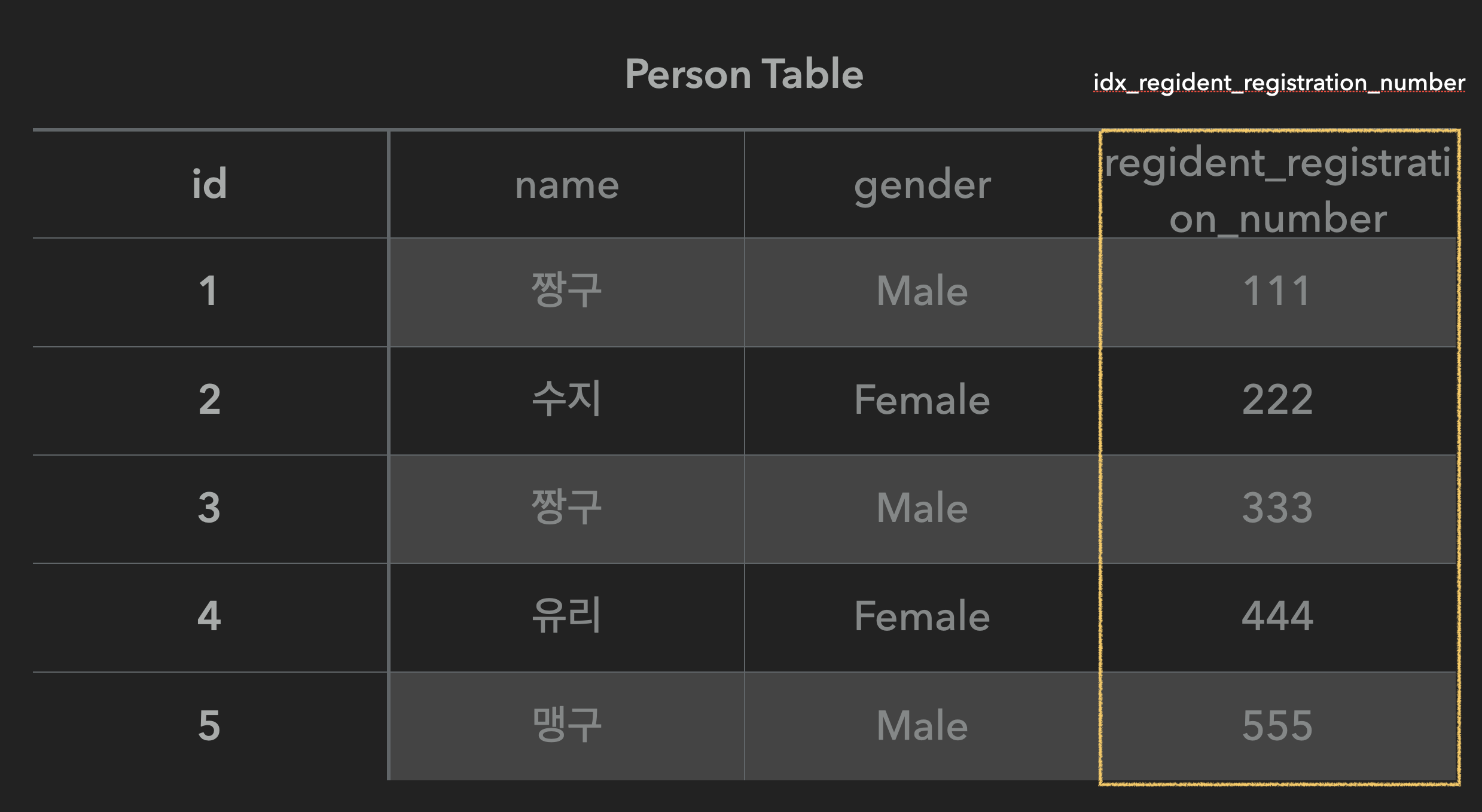
예를 들어 위와 같은 Person Table 이 존재한다고 했을 때 현재 Person Table 의 'regident_registration_number' 컬럼(Column)에 인덱스가 적용되어져있다.
즉, 이와 같이 인덱스는 id, name, gender, regident_registration_number 와 같은 컬럼을 기준으로 적용되어진다.
그리고 예제에서는 하나의 컬럼에 대해 인덱스를 적용했는데
- id와 name
- name 과 gender
- id, name, gener
등 여러가지 조합으로 N개의 컬럼을 묶어 인덱스를 적용할 수도 있다.
Index의 장점
인덱스를 사용하면 우리는 특정한 정보를 빠르게 찾아낼 수 있다.
왜냐하면 특정한 정보의 위치를 미리 기록해두었기 때문에 인덱스를 참조하여 해당 데이터가 존재하는 곳으로 빠른 시간 내에 이동할 수 있기 때문이다.
즉, 인덱스를 사용함으로써 우리는 데이터를 탐색하는데 소요되는 시간을 굉장히 줄일 수 있다.
Index의 단점
우리가 한 권의 데이터베이스 책을 가지고 있다고 해보자.
그리고 "데이터베이스"라는 단어를 인덱스로 선택했다고 가정해보자.
"데이터베이스"라는 단어가 들어간 모든 페이지를 찾아간다고 했을 때 이 인덱스는 과연 의미가 있을까?
아마 그렇지 못할 것이다. 데이터베이스를 설명하는 책의 첫 장부터 끝장까지 얼마나 많은 "데이터베이스"라는 단어가 등장하겠는가...
어쩌면 매번 인덱스를 참고한 뒤 페이지를 찾아가는 과정을 반복하기 보다는 차라리 앞장부터 천천히 살펴보면서 데이터베이스가 나올 때마다 밑줄을 긋는게 훨씬 빠를 수도 있다.
즉, 우리는 인덱스를 적용할 테이블의 컬럼 선택시 데이터의 카디널리티(Cardinality) 가 높은 것을 우선시 해야한다.
우리는 "데이터베이스" 인덱스를 만들어야하기에 책의 내용과 더불어 인덱스를 위한 페이지도 만들어내야한다.
즉, 위의 경우 의미없는 인덱스로 인해 책의 페이지 수(저장 공간)만 늘어나게 된다.
우리가 또 한가지 생각해보아야할 것은 데이터의 추가, 수정, 삭제에 대한 것이다.
만약 인덱스가 없었더라면 원하는 부분에 대해서만 추가, 수정, 삭제 작업을 진행하면 된다.
하지만 인덱스가 존재함으로 인덱스의 추가, 수정, 삭제 작업 또한 함께 진행되어야한다.
즉, 인덱스를 생성함으로써 데이터의 추가, 수정, 삭제시에는 어느 정도 성능이 느려질 수도 있다는 것이다.
따라서 우리는 인덱스를 마구잡이로 생성해서는 안된다.
정리
-
인덱스란 특정한 정보의 위치를 미리 기록해두고 빠르게 찾아갈 수 있도록 하는 것이다.
-
인덱스를 사용함으로써 우리는 데이터 검색 속도를 향상시킬 수 있다.
-
인덱스는 데이터베이스 테이블의 컬럼(Column) 을 기준으로 적용된다.
-
인덱스를 적용할 컬럼 선택시 카디널리티(Cardinality)가 높은 것을 우선적으로 선택해야한다.
-
인덱스를 사용하게 되면 인덱스를 위한 추가적인 공간이 필요해진다.
-
인덱스를 생성하는 시간이 많이 소요될 수 있다.
-
데이터의 변경이(CUD) 자주 일어날 경우에는 오히려 성능이 안좋아질 수도 있다.
-
인덱스는 조회(Select) 의 성능을 높이는 대신 Insert, Update, Delete 의 성능을 희생하는 것이다.
참고
- 카디널리티(Cardinality)
- 데이터의 중복도를 나타내는 것이다.
- Example
- 성별 : 중복도가 높다. 따라서 "카디널리티가 낮다."라고 표현한다.
- 주민등록번호 : 중복도가 낮다. 따라서 "카디널리티가 높다."라고 표현한다.
