Liquid Warping GAN: A Unified Framework for Human Motion Imitation,
Appearance Transfer and Novel View Synthesis
Abstract
- 우리는 human motion imitation, appearance transfer, 그리고 view synthesis를 다 할수 있는 프레임워크를 만들었다.
- 한번 트레이닝 하면 위 3가지 태스크를 다 수행할수 있다는 뜻.
- 기존의 방법들은 주로 2D 키포인트 방식을 사용한다.
- 우리는 3D body mesh recovery module을 사용한다.
- 포즈와 shape을 구분하고 중복된 location과 rotation 문제 뿐만 아니라 personalized body shape까지 다룰수 있다.
- 소스의 정보(텍스처, 스타일, 컬러, face identity)를 유지하기 위해서 우리는 Liquid Warping GAN을 만들었다.
- Liquid Warping Block(LWB)를 사용해서 소스의 정보를 이미지와 피처 스페이스에 전파하고 레퍼런스와 비슷한 이미지를 합성한다.
- 특히, 소스의 피처들은 denoising conv auto-encoder를 사용해서 추출한다.
- 소스의 아이덴티티 특성을 잘 살리기 위해
- 게다가 이 방법은 multiple 소스로 부터의 warping도 지원 가능하다.
- 새로운 데이터셋도 만들었다.
- 이름은 Impersonator dataset(iPER)
- human motion transfer, appearance transfer, 그리고 novel view synthesis를 평가하기 위해
- 실험 결과 우리의 방법은 robustness in occlusion, face identity의 유지, shape consistency와 cloths detail에서 좋은 효과를 보여준다.
1. Introduction
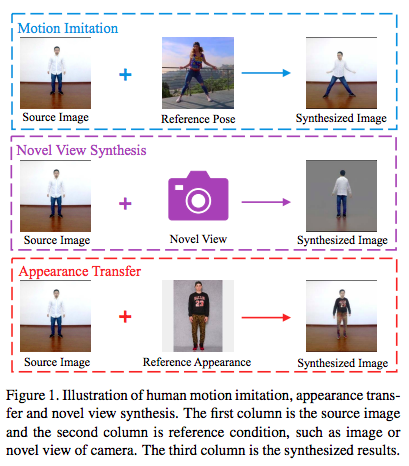
- Motion Imitation
- 소스 사람의 텍스처 + 레퍼런스 사람의 포즈로 이미지를 생성하는 것
- Novel View Synthesis
- 다른 뷰포인트의 새로운 이미지를 생성하는 것.
- Appearance Transfer
- 레퍼런스의 아이덴티티와 옷을 유지한채 새로운 이미지를 생성하는 것.
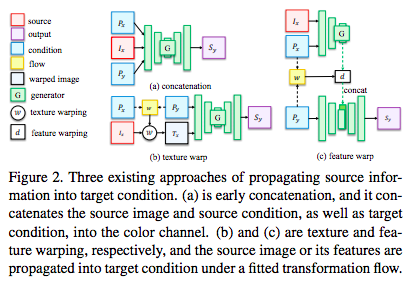
- 소스 정보를 타겟 컨디션에 전파하는 3가지 어프로치
- Concatenation
- 소스 이미지와 타겟 포즈 컨디션을 concatenate 한 뒤 GAN의 입력으로 넣는다.
- direct concatenation은 spatial layout을 고려하지 않고, 이미지 생성시 정확한 위치에 생성하지 못하는 단점이 있다.
- 그래서 결과가 흐리거나 소스의 아이덴티티를 잃어 버린다.
- Texture Warp
- Spatial Transformer Networks(STN)으로 부터 영향을 받았다.
- It firstly fits a rough affine transfomation matrix from source and reference poses.
- STN을 사용하여 소스 이미지를 레퍼런스 포즈로 warp 한다.
- 이 warped 이미지를 가지고 최종 결과를 생성한다.
- 하지만 texture warping이 소스의 정보(컬러, 스타일, 얼굴 아이덴티티)를 잘 유지하지 못한다.
- 왜냐하면 생성자가 몇번의 다운 샘플링 연산을 통해 소스의 정보를 drop out 시키기 때문이다.
- Feature Warp
- 소스의 deep feature를 타겟 포즈에 warp한다.
- 그러나 인코더를 통한 feature extract가 소스의 정확한 특성을 뽑아내지 못할 수도 있다.
- 그 결과 흐리거나 low fidelity 이미지가 생성될 수도 있다.
- 기존의 방법들은 비현실적인 이미지를 생성해내는 한계를 보이는데 이는 세가지 이유가 있다.
- 의상의 다양성과 high-structure face identity는 기존의 아키첵처로는 유지하기 힘들다
- 바디의 형태가 변형되거나 위치가 변하는 경우
- multiple source input을 처리하지 못한다.
- 이 논문에서 소스의 정보(의상의 디테일, face identity)를 유지하기 위해 우리는 Liquid Warping Block(LWB)를 만들었다.
- denoising conv autoencoder를 사용해 피처를 추출해서 소스의 유용한 정보들(텍스처, 컬러, 스타일, face identity)을 유지시켰다.
- 각 로컬 파트의 소스 피처들은 LWB에 의해 글로벌 피처 스트림에 블렌딩 되어 소스 디테일을 유지 시킨다.
- 멀티소스 워핑을 지원한다.
- 기존의 어프로치들은 2D 포즈나 DensePose, body parsing을 사용했다.
- 이 방법은 개인의 형태나 limbs rotations들을 무시하는 한계가 있다.
- 이 한계를 극복하기 위해 우리는 SMPL(parametric statistical human body model) 이라는 방법을 사용했다.
- output이 3D mesh(without clothes)
- keypoints 방식보다 더 정확하고 misalignments가 적다.
- SMPL 모델과 Liquid Warping Block으로 인해 우리의 방식은 다른 task에 확장 가능하다.
- 예를 들어 human appearance transfer, novel view synthesis
- Summary
- 소스 정보의 손실을 줄이기 위해 LWB를 제안했다.
- LWB와 3D parametric model의 장점을 살려 우리는 unified framework을 만들었다.(다양한 task를 수행 가능하다.)
- 특히 human motion imitation in video에 적합한 데이터셋을 만들었다.
3. Method
- Liquid Warping GAN은 세가지 단계로 나뉜다.
- Body mesh recovery
- Flow composition
- GAN module with Liquid Warping Block
- 먼저 body mesh recovery 모듈이 소스 이미지와 레퍼런스 이미지의 3D mesh와 연관 맵을 만들어낸다.
- 그 다음 flow composition 모듈에서 연관 맵을 통해 transformation flow를 계산하고 이미지 공간에 mesh를 프로젝션 한다.
- 소스 이미지는 프론트와 백그라운드로 분리한다.
- 그리고 transformation flow에 기반해서 새로운 이미지를 생성한다.
- 마지막 GAN 모듈에서는 백그라운드 이미지, 재구성된 소스 이미지, reference 컨디션 기반의 이미지를 각각 생성해낸다.
- 소스 이미지의 디테일을 살리기 위해 LWB를 사용한다.(소스의 피처를 전파한다.)

So interesting! 😄