이미지 캡셔닝 모델
안녕하세요 🙂
이번 프로젝트 준비를 위해 이미지 캡셔닝과, 해당 캡션 텍스트를 원하는 말투로 생성해줄 수 있는지에 관하여 공부해야합니다. 이번주차에는 이미지 캡셔닝과 이미지 캡셔닝의 단계, 그리고 실습을 통해 이미지 캡셔닝을 이해해 보려고 합니다.
아직 실습을 진행 중 이지만 , 실습을 마친 후 추가 공부를 통해 구글에서 발표한 현재 가장 많이 사용된다는 이미지 캡셔닝 모델인 [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention] 에 대해 추가로 알아보고 글을 작성할 예정입니다. 또한 학습시킬 데이터셋으로 무엇이 적합한지 알아보고, 이것이 마땅하지 않다면 transfer하는 방법을 고려해 추가 조사 하려 합니다.
1. 이미지 캡셔닝이란?

- 이미지 캡셔닝은, 컴퓨터 비전과 자연어 처리를 결합하여 이미지에 대한 자연어 설명을 생성하는 작업
- 목표: 주어진 이미지에 대한 높은 수준의 이해와 텍스트 생성 능력을 모델에 부여
2. 이미지 캡셔닝 단계
-
이미지 입력:
- 모델의 입력으로는 이미지가 사용됨
- 이미지는 픽셀 값으로 표현(컬러 이미지는 RGB).
- 이미지는 딥 러닝 모델에 의해 symantic 정보를 추출하기 위한 feature map으로 변환됨
-
이미지 특성 추출:
- 이미지에서 symantic 정보를 추출하기 위해 딥 러닝 모델 (일반적으로 CNN)을 사용
- CNN은 이미지의 다양한 특성을 학습하고 추출하여 이를 고차원의 벡터로 변환
- 벡터는 이미지에 대한 특성을 나타냄
-
문맥 학습:
- 이미지의 특성을 기반으로 모델은 문맥을 학습
- 주로 순환 신경망 (RNN 또는 LSTM)이나 Transformer와 같은 모델이 사용
- 이 모델은 이미지 특성을 시퀀스로 변환하고, 문맥을 잘 이해할 수 있도록 함
-
자연어 설명 생성:
- 학습된 모델은 이미지의 특성과 문맥을 기반으로 이미지에 대한 자연어 설명을 생성
- 디코더라고 불리는 신경망 구조를 사용
- 디코더는 이전 단어를 입력으로 받아 다음 단어를 생성하며, 캡션을 완성
-
평가와 최적화:
- 생성된 자연어 설명은 실제 캡션과 비교되어 평가됨
- 주로 BLEU (Bilingual Evaluation Understudy) 등의 평가 지표를 사용하여 자동적으 로 캡션의 품질을 측정
- 모델은 이러한 평가를 기반으로 최적화되며, 학습 데이터를 통해 계속해서 향상됨
3. 입력 데이터
이미지 캡셔닝 모델을 학습시킬 때, 주로 사용되는 입력 데이터는 이미지와 해당 이미지에 대한 텍스트 설명(캡션)의 쌍으로 이루어진 데이터셋입니다. 이 데이터셋은 각 이미지에 대한 정답 캡션을 제공하여 모델이 이미지와 텍스트 간의 관계를 학습할 수 있도록 합니다.
3.1. 이미지 데이터
이미지는 픽셀 값으로 이루어진 행렬입니다.
- 컬러 이미지: RGB 채널
- 흑백 이미지: 단일 채널
이미지의 크기는 일반적으로 고정된 크기로 조정되어 사용됩니다.
ex) 224x224 or 299x299 픽셀
3.2. 텍스트 데이터
각 이미지에 대한 정답 캡션은 자연어로 표현되며, 문장 또는 문장의 시퀀스로 구성됩니다.
텍스트 데이터는 일반적으로 토큰으로 분할됩니다.
ex) "A black cat is sitting on a white table"라는 이미지에 대한 캡션
- 이미지 데이터: 해당 이미지의 RGB 픽셀 값
- 텍스트 데이터: ["A", "black", "cat", "is", "sitting", "on", "a",
"white", "table"]
토큰이란?
주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업을 토큰화(tokenization)라고 합니다. 토큰의 단위가 상황에 따라 다르지만, 보통 의미있는 단위로 토큰을 정의합니다. 여기서는 토큰화에 대한 발생할 수 있는 여러가지 상황에 대해서 언급하여 토큰화에 대한 개념을 이해합니다. 이어서 NLTK, KoNLPY를 통해 실습을 진행하며 토큰화를 수행합니다.
3.3 자주 사용되는 (이미지, 텍스트) 쌍의 데이터셋
-
MSCOCO 데이터셋 (Microsoft Common Objects in COntext):
- MSCOCO는 대표적인 이미지 캡셔닝 데이터셋 중 하나로, 약 80,000개의 이미지와 각 이미지에 대한 5개의 캡션으로 구성되어 있습니다.
- 이 데이터셋은 다양한 객체와 상황을 포함하고 있어 이미지 캡셔닝 모델을 학습하기에 적합합니다.
-
Flickr8k 및 Flickr30k:
- Flickr에서 수집한 이미지와 이에 대한 캡션으로 이루어진 데이터셋입니다.
- Flickr8k는 8,000개의 이미지와 각 이미지에 대한 5개의 캡션으로 구성되어 있으며, Flickr30k는 30,000개의 이미지와 5개의 캡션으로 구성되어 있습니다.
-
Visual Genome:
- Visual Genome은 객체의 풍부한 어노테이션과 함께 다양한 이미지를 제공하는 데이터셋입니다.
- 객체 위치, 속성, 관계 등에 대한 세부 정보가 포함되어 있어 더 복잡한 시나리오에 적합합니다.
-
AI2 Thor 데이터셋:
- Thor 데이터셋은 AI2에서 제공하는 3D 환경에서의 이미지 캡셔닝을 위한 데이터셋입니다.
- 이 데이터셋은 인공 지능 에이전트가 3D 환경에서 상호 작용하며 학습할 수 있는 환경을 제공합니다.
-
자체 수집 데이터:
- 특정 도메인이나 고유한 데이터셋을 위해 직접 이미지와 캡션을 수집하는 것도 가능합니다. 이 경우에는 주로 웹 크롤링, 특정 API를 통한 데이터 수집 등을 활용할 수 있습니다.
4. 자주 사용되는 이미지 캡셔닝 모델
-
Show and Tell (Google)
- 아키텍처: CNN (Convolutional Neural Network) 기반의 이미지 특성 추출기와 LSTM (Long Short-Term Memory) 기반의 시퀀스 모델
- 특징: 이미지 특성을 추출하고 이를 기반으로 문장을 생성하는 구조
- 프레임워크: TensorFlow
- 설명: 이미지의 시맨틱 정보를 효과적으로 잡아내고, LSTM을 통해 문맥을 고려하여 자연어 설명을 생성합니다.
-
NIC (Neural Image Caption)
- 아키텍처: CNN 및 LSTM
- 특징: 이미지 특성을 추출하는 CNN과 이미지 설명을 생성하는 LSTM을 결합
- 프레임워크: PyTorch, TensorFlow
- 설명: CNN을 통해 추출된 특성을 LSTM에 입력하여 시퀀스 생성을 수행하는 구조
-
Bottom-Up Top-Down (BUTD)
- 아키텍처: Faster R-CNN과 LSTM을 결합
- 특징: 객체 검출에 뛰어난 Faster R-CNN과 LSTM을 조합하여 이미지 캡션 생성
- 프레임워크: PyTorch
- 설명: 이미지 내의 다양한 객체를 검출하고, 이 정보를 활용하여 더 풍부한 캡션을 생성하는 방식
-
Transformer-based 모델 (e.g., VilBERT)
- 아키텍처: Transformer
- 특징: 이미지와 텍스트 정보를 효과적으로 통합하는 Transformer 구조 사용
- 프레임워크: PyTorch
- 설명: Transformer의 self-attention 메커니즘을 사용하여 이미지와 텍스트 간의 관계를 학습하고 캡션을 생성
-
Image-Captioning-ResNet-Attention (Microsoft)
- 아키텍처: ResNet과 어텐션 메커니즘
- 특징: ResNet을 통해 이미지 특성을 추출하고 어텐션 메커니즘을 사용하여 중요한 부분에 집중
- 프레임워크: PyTorch
- 설명: 어텐션 메커니즘을 활용하여 모델이 이미지의 중요한 부분에 더 집중하도록 하며, 이를 통해 더 정확한 캡션을 생성할 수 있습니다.
이러한 모델 중 선택은 사용 환경, 데이터셋의 특성, 모델의 성능 등 다양한 요인을 고려해야 합니다. 최근에는 Transformer 기반의 모델들이 이미지 캡셔닝 분야에서도 좋은 성능을 보이고 있습니다.
4.실습
(텐서플로우에서 제공하는 설명과 코드를 참고)
https://www.tensorflow.org/tutorials/text/image_captioning?hl=ko
위의 튜토리얼에서 사용되는 모델은 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 입니다. 여기서 2단 레이어 트랜스포머 디코더를 사용하도록 업데이트되었다고 합니다.
모델 아키텍처는 아래와 같습니다.
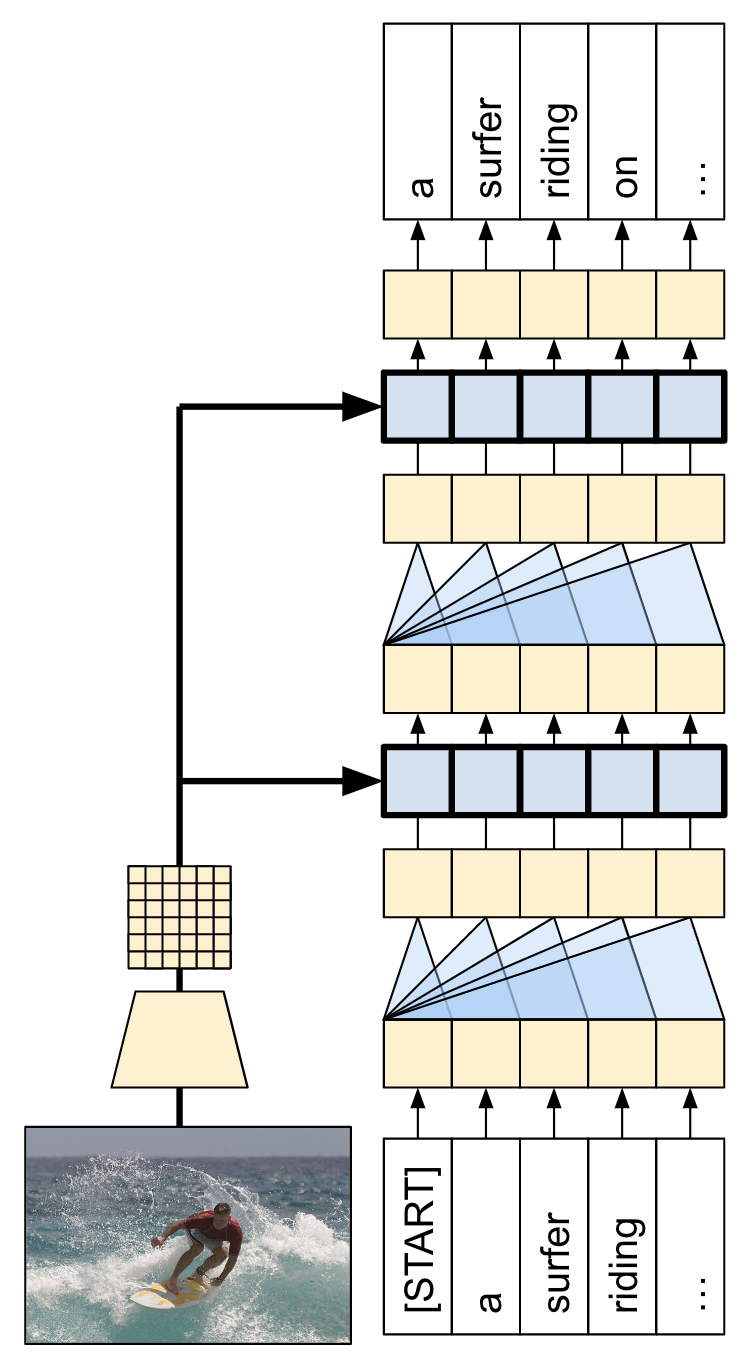
트랜스포머 디코더는 주로 어텐션 레이어에서 빌드됩니다. 이는 셀프 어텐션을 사용하여 생성되는 시퀀스를 처리하고 크로스 어텐션을 사용하여 이미지를 처리합니다.
크로스 어텐션 레이어의 어텐션 가중치를 검사하면 모델이 단어를 생성할 때 이미지의 어떤 부분을 모델이 보고 있는지 알 수 있습니다.
이 노트북은 엔드 투 엔드 예제입니다. 노트북을 실행하면 노트북은 데이터세트를 다운로드하며 이미지 특성을 추출하고 캐싱하여 디코더 모델을 훈련합니다. 그런 다음 모델을 사용하여 새로운 이미지에 캡션을 생성합니다.
