
사용 데이터 : fashion MNIST dataset
라이브러리 불러오기
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
tf.__version__데이터 불러오기
(X_train, y_train), (_, _) = tf.keras.datasets.fashion_mnist.load_data()
# 숫자 mnist 데이터 코드
# (X_train, y_train), (_, _) = tf.keras.datasets.mnist.load_data()데이터 확인
X_train.shape
# (60000, 28, 28) : 이미지 개수, 가로, 세로 픽셀값
28*28
# 784 (한 이미지에 있는 총 픽셀수)
y_train.shape
# (60000,) : 개수이미지 확인
i = np.random.randint(0, 60000)
#print(i)
print(y_train[i]) # 랜덤 인덱스 출력
plt.imshow(X_train[i], cmap = 'gray'); #끝에 ; 붙이면 출력값에 이미지만 깔끔하게뜸데이터(이미지) 전처리
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
# 이미지 개수, 가로, 세로, 채널값(흑백:1, 컬러:3)
X_train.shape
# (60000, 28, 28, 1)
X_train[0].min(), X_train[0].max() # 첫번째 이미지 선택
# (0.0, 255.0)
# 정규화(normalize)
X_train = (X_train - 127.5) / 127.5
X_train[0].min(), X_train[0].max()
# (-1.0, 1.0) : DCGAN 사용시에는 -1~1로 정규화해야됨.
# 다른 거 사용할 때는 0~1로 정규화하기도 함.# 미니배치 경사하강법(mini batch gradient descent algorithm)
buffer_size = 60000 # 이미지 총 개수
batch_size = 256 # 데이터셋 나눌 개수
buffer_size / batch_size # 234.375
# 배치 개수 234개, 배치 한번당 데이터 256개# 데이터 타입 확인 및 변환
type(X_train)
# numpy.ndarray
# 데이터타입=어래이 -> 신경망에 집어넣기 위해 텐서로 변환
X_train = tf.data.Dataset.from_tensor_slices(X_train).shuffle(buffer_size).batch(batch_size)
type(X_train)
# tensorflow.python.data.ops.batch_op._BatchDataset
X_train
# <_BatchDataset element_spec=TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name=None)>Generator 생성
def build_generator():
network = tf.keras.Sequential() #텐서플로우 사용 인공신경망 기본값
network.add(layers.Dense(units = 7*7*256, use_bias = False, input_shape=(100,))) # units:첫번째 레이어에서 사용할 총 뉴런 개수, generator에서는 분류 문제를 푸는게 아니라서 bias 필요없음, input_shape:인풋레이어의 뉴런 개수(default:100)
# 256은 데이터 개수인데, 왜 7*7로 설정했는지를 모르겠음.???
network.add(layers.BatchNormalization()) # 정규화 레이어
network.add(layers.LeakyReLU()) #activation layer
network.add(layers.Reshape((7,7,256)))
# 7x7x128
network.add(layers.Conv2DTranspose(filters = 128, kernel_size = (5,5), padding='same', use_bias=False)) # filters: filter detector 수, kernel_size: detector 사이즈, padding:'same'은 남는 컬럼 뒤에 0추가해서 사이즈 맞추는거/'valid'는 남는 컬럼 사용안하는거
# Conv2DTranspose : 차원값 늘리려고 사용.(7->14->28)
network.add(layers.BatchNormalization())
network.add(layers.LeakyReLU())
# 14x14x64
network.add(layers.Conv2DTranspose(filters = 64, kernel_size = (5,5), padding='same', use_bias=False, strides=(2,2)))
network.add(layers.BatchNormalization())
network.add(layers.LeakyReLU())
# 28x28x1 (원래 이미지 사이즈 가로, 세로, 채널값)
network.add(layers.Conv2DTranspose(filters = 1, kernel_size=(5,5), padding='same',use_bias=False, strides=(2,2), activation = 'tanh')) #'tanh'으로 하면 -1~1로 결과 나옴. 처음 데이터 정규화한거랑 같은 출력값이 나오게 해야함. 0~1이었으면 sigmoid 사용.
network.summary()
return network# 생성
generator = build_generator()
generator.input
# <KerasTensor: shape=(None, 100) dtype=float32 (created by layer 'dense_input')># 인풋 레이어에 들어갈 노이즈값 랜덤 설정
noise = tf.random.normal([1, 100])
noise# generator 작동하는지 테스트
generated_image = generator(noise, training = False) #지금은 학습안되게 설정
generated_image.shape
# TensorShape([1, 28, 28, 1]) : 마지막 출력되는 결과값의 shape
plt.imshow(generated_image[0, :, :, 0], cmap='gray');
# 이미지 하나만 그릴거라서 0, 차원 정보는 다 필요해서 :, 채널값도 한개라서 0 넣어줌.
# -> ?? 잘 이해안됨. 아시는 분 댓글 달아주세요..Discriminator 생성
def build_discriminator():
network = tf.keras.Sequential()
# 14x14x64
network.add(layers.Conv2D(filters = 64, strides=(2,2), kernel_size = (5,5), padding = 'same', input_shape = [28,28,1]))
# Conv2D 사용해서 사이즈 줄임 (28->14->7), strides: moving window(커널이 움직이는 정도같음)
network.add(layers.LeakyReLU())
network.add(layers.Dropout(0.3)) # Dropout: 과적합 방지용으로 0.2~0.5 정도로 사용
# 7x7x128
network.add(layers.Conv2D(filters = 128, strides=(2,2), kernel_size = (5,5), padding = 'same'))
network.add(layers.LeakyReLU())
network.add(layers.Dropout(0.3))
network.add(layers.Flatten()) # 벡터화
network.add(layers.Dense(1)) # real or fake (1 or 0) 값 하나로 출력.
# 마지막에 activation function 사용 안함.
network.summary()
return network# 생성
discriminator = build_discriminator()
discriminator.input
# discriminator.input
<KerasTensor: shape=(None, 28, 28, 1) dtype=float32 (created by layer 'conv2d_input')># discriminator 작동하는지 테스트
discriminator(generated_image, training = False)
# <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.00055447]], dtype=float32)>
# 마지막에 활성함수 지정안해서 출력값이 logit값으로 나옴(0.00055447)
tf.sigmoid(0.00356018)
# <tf.Tensor: shape=(), dtype=float32, numpy=0.5008901>
# 확률값으로 보기 위해 시그모이드 적용하면 0.5(진짠지 가짠지 반반이라는 소리)G&D 연결 (Error/Loss calculation; integration between G&D)
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits = True)
# 진짠지 가짠지 이진분류라서 binaryCrossentropy 사용, D 아웃풋이 logit값이어서 True
generator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.00001)
discriminator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.00001)
# best weights를 찾기 위한 옵션def discriminator_loss(expected_output, fake_output):
real_loss = cross_entropy(tf.ones_like(expected_output), expected_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)discriminator는 진짜 이미지와 가짜 이미지를 비교하는 작업을 위해,
- real_loss에서 전부 1인 텐서와 실제 이미지를 비교
: real_loss가 낮을수록 실제 이미지를 실제로 판별한다는 소리 같음,, - fake_loss에서 전부 0인 텐서와 가짜 이미지를 비교.
: fake_loss가 낮을수록 가짜 이미지를 가짜라고 판별 - total_loss = real_loss + fake_loss
: 결국 total_loss가 낮을수록 진짜/가짜 판별 성능이 좋은 Discriminator
generator는 가짜 이미지를 진짜로 판별되도록 만들기위해,
- 가짜 이미지를 전부 1인 텐서와 비교해서 generator_loss가 낮아지는 방향으로 진화.
*log(1)=0, log(0)=-무한
- D => V(D,G)가 최대가 되도록 진화
가짜 D(G(x))는 0, 진짜 D(x)는 1로 판별하는 Discriminator.
D(G(x))=0, log(1-D(G(x)))=0
D(x)=1, logD(x)=0
이때 D(x)는 0 아니면 1이어서, logD(x) + log(1-D(G(x))) 최대값이 0이 되는 것.- G => V(D,G)가 최소가 되도록 진화
가짜 D(G(x))가 진짜라고 판별되도록 진화하는 generator.
D(G(x))=1이 되는게 목표.
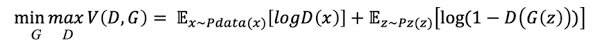
학습 (training)
위에서 했던 코드들 정리해서 한번에 쓰는 느낌
epochs = 100 # 학습횟수
noise_dim = 100 # noise dimension: 인풋값에 넣을 랜덤값 수
num_images_to_generate = 16 # 만들 이미지 수@tf.function
def train_steps(images):
noise = tf.random.normal([batch_size, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training = True)
# 가짜 이미지 = generator(노이즈 넣음, 학습 ㅇ)
expected_output = discriminator(images, training = True)
# 실제 출력값 = discriminator(실제 데이터 입력, 학습 ㅇ)
fake_output = discriminator(generated_images, training = True)
# 가짜 출력값 = discriminator(가짜 이미지 입력, 학습 ㅇ)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(expected_output, fake_output)
# weight 수정 방향 정하기
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
# optimizer 수정 방향 정하기
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))def train(dataset, epochs, test_images):
for epoch in range(epochs):
for image_batch in dataset: # 미니 배치
#print(image_batch.shape)
train_steps(image_batch)
print('Epoch: ', epoch + 1)
generated_images = generator(test_images, training=False)
fig = plt.figure(figsize = (6,6))
for i in range(generated_images.shape[0]): # 생성된 이미지 수
plt.subplot(4,4,i+1)
plt.imshow(generated_images[i, :, :, 0] * 127.5 + 127.5, cmap = 'gray')
plt.axis('off')
plt.show()test_images = tf.random.normal([num_images_to_generate, noise_dim])
# 랜덤 이미지 생성
test_images.shape
# TensorShape([16, 100])train(X_train, epochs, test_images)성능 향상을 위해 가능한 방법
- 파라미터 변경 (ex. 학습률 수정)
- D,G에 레이어 더 쌓기
다른 데이터로 DCGAN 사용해봤을때 애로사항,,
- 입출력값 shape 맞추기가 어려웠음. 사용할 데이터(이미지) 사이즈랑 모델 레이어 입출력값이랑 맞추는 작업 필요함.
- 현실적으로 가능한 에폭만큼 돌리면 화질이 그닥 좋지않아서, 만들어진 이미지를 분류모델에 사용하기에는 힘들어보임.
