
WGAN (Wasserstein GAN)
-
2017년 등장 (cf. GAN 2014, DCGAN 2015)
-
Wasserstein loss 사용 (학습시킬때 안정성 좋음)
대부분의 GAN에서는 Jensen-Shannon divergence를 사용하는데, 이건 Wasserstein distance를 사용한다. Wasserstein loss로 Wasserstein distance(분포를 실제와 비슷하게 맞추는지) 측정.
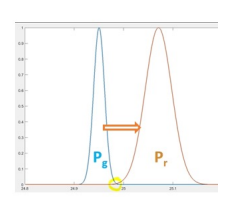
-
GAN 문제점 해결 가능
- 모드 붕괴 (mode collapse)
- 기울기 소실 (vanishing gradients)
-
'critic' = 'discriminator' 판별자
-
가중치 클리핑 (weight clipping) 사용 (Lipschitz Constraint)
Mode Collapse
GAN이 여러 다른 클래스의 이미지를 생성할 수 없음을 정의. (여러 종류의 개 품종을 학습시켜도 특정 종만 생성할 수 있음)
생성자가 특정 종만 만들어내니까, 판별자도 그 특정 종을 제외하고는 학습될 수가 없다. 결국 생성자는 계속 비슷한 결과만 만들어낼뿐.
Vanishing Gradients
판별자 성능이 너무 뛰어나면, 생성자 학습이 실패로 돌아가는 결과를 보인 경우가 있음.
gradient = 알고리즘에 다음 weight값을 어떻게 업데이트할지 알려줌
weight 값의 변화가 아주 미세해서 결과에 영향을 주지 않음. (0.0000013 -> 0.0000111로 바뀌는 것처럼)
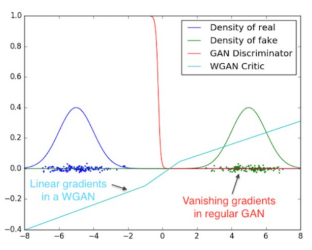
Wasserstein loss
기울기 소실(vanishing gradients) 문제 해결을 위해 개발됨.
판별자가 vanishing gradients 문제 걱정 없이 학습될수있어서 mode collapse까지 완화시키는 결과를 가져왔다.
기존 GAN은 loss가 판별자가 잘 속는지 정도를 측정했다. 이미지의 퀄리티는 측정x. 따라서 우리가 보고 퀄리티 평가를 해야했음. 하지만 WGAN의 loss function은 퀄리티를 반영한다.
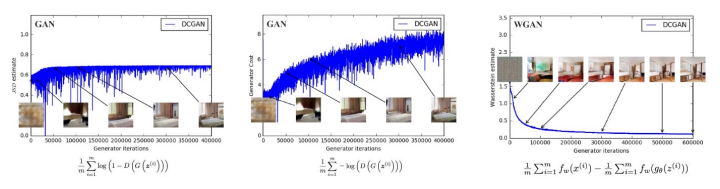
3번째가 WGAN인데, 전통적인 신경망 학습과 비슷한 loss 그래프 형태를 보인다. loss가 줄어들수록 이미지 퀄리티가 좋아짐.
Wasserstein distance
GAN 목표 : 생성 이미지의 분포를 실제 이미지 분포에 근접하도록.
그렇다면 두 분포 사이의 거리는 어떻게 측정할건인지?
1) KL(kullback-lelbler) divergence
2) JS(Jensen-Shannon) divergence : most used, 하지만 gradients 문제가 있음.
3) Wasserstein distance
WGAN은 Wasserstein distance로, 기존 DCGAN에서 loss function 하나만 바꿨는데 결과가 훨씬 좋아짐.

WGAN 문제점
1. 립시츠 제약 (Lipschitz Constraint)
Wasserstein 거리 계산을 위해 사용하는 가중치 클리핑(weight clipping). 하이퍼파리미터의 c가 알맞게 정해지지 않으면 여전히 낮은 퀄리티의 이미지가 만들어지는데, vanishing gradients의 반대 문제인 exploding gradients(기울기 폭발)가 생기는 것.
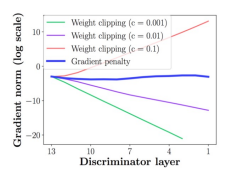
이 문제 해결을 위해 -> 경사 패널티 (gradient penalty) 사용. (WGAN-GP)
2. Model Capacity
WGAN의 contour plot은 단순함.(1행)
2행은 WGAN-GP의 등고선도. 더 복잡한 것을 확인할 수 있다. 이게 더 좋은 퀄리티의 이미지를 생성함.
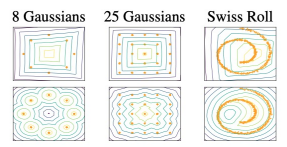
WGAN-GP
경사 패널티 (gradient penalty)
: 가중치 클리핑(weight clipping) 대신에 판별자 인풋을 고려해 gradient norm에 패널티 부과
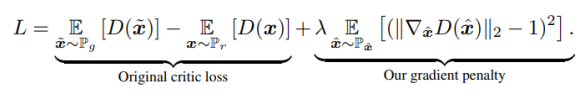
예제 코드
사용 데이터 : mnist
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import os
import time
from IPython import display
from tensorflow import keras
from tensorflow.keras import layers
tf.__version__ #2.12.0데이터 불러오기
(X_train, y_train), (_, _) = tf.keras.datasets.mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
# -1 ~ 1로 정규화
X_train = (X_train - 127.5) / 127.5
buffer_size = 60000
batch_size = 256
# 텐서플로우 형태로 변환, 배치 형태로 변환
X_train = tf.data.Dataset.from_tensor_slices(X_train).shuffle(buffer_size).batch(batch_size)생성자 만들기
# 생성자 함수 정의
def build_generator():
network = tf.keras.Sequential()
network.add(layers.Dense(units = 7*7*256, use_bias = False, input_shape=(100,)))
network.add(layers.BatchNormalization())
network.add(layers.LeakyReLU())
network.add(layers.Reshape((7,7,256)))
# 7x7x128
network.add(layers.Conv2DTranspose(filters = 128, kernel_size = (5,5), padding = 'same', use_bias = False))
network.add(layers.BatchNormalization())
network.add(layers.LeakyReLU())
# 14x14x64
network.add(layers.Conv2DTranspose(filters = 64, kernel_size = (5,5), padding = 'same', strides = (2,2), use_bias = False))
network.add(layers.BatchNormalization())
network.add(layers.LeakyReLU())
# 28x28x1
network.add(layers.Conv2DTranspose(filters = 1, kernel_size = (5,5), padding = 'same', strides = (2,2), use_bias=True, activation='tanh'))
network.summary()
return network# 생성자 설정
generator = build_generator()
noise = tf.random.normal([1, 100])
#이미지 생성 test
generated_image = generator(noise, training = False)
plt.imshow(generated_image[0, :,:,0], cmap='gray');판별자 만들기
#판별자 생성 함수
def build_discriminator():
network = tf.keras.Sequential()
# 14x14x64
network.add(layers.Conv2D(filters = 64, strides = (2,2), kernel_size = (5,5), padding = 'same', input_shape = [28,28,1]))
network.add(layers.LeakyReLU())
network.add(layers.Dropout(0.3))
# 7x7x128
network.add(layers.Conv2D(filters = 128, strides = (2,2), kernel_size = (5,5), padding = 'same'))
network.add(layers.LeakyReLU())
network.add(layers.Dropout(0.3))
network.add(layers.Flatten())
network.add(layers.Dense(1))
network.summary()
return network# 판별자 설정
discriminator = build_discriminator()
# 판별자 test
discriminator(generated_image, training = False) # logits
#numpy=array([[-0.00030457]]
tf.sigmoid(-0.00030457)
#numpy=0.49992383 (49.9%)Wasserstein Loss 계산 함수
*loss : 실제 이미지를 넣었을 때 판별자에서 나오는 결과값이랑 가짜 이미지를 넣었을 때 결과값의 차이
DCGAN과 차이가 있는 부분
: DCGAN은 전부 1/0인 벡터와 비교해서 cross-entrophy 계산을 했는데, WGAN은 전체 출력값의 평균을 이용한다. 판별자loss함수에서는 그라디언트 패널티 값이 추가됨.
def loss_generator(fake_output):
g_loss = -1. * tf.math.reduce_mean(fake_output)
return g_loss
# 생성자는 loss를 작게 만든는게 목표def loss_discriminator(real_output, fake_output, gradient_penalty):
c_lambda = 10
d_loss = tf.math.reduce_mean(fake_output) - tf.math.reduce_mean(real_output) + c_lambda * gradient_penalty
return d_lossgradient_penalty
@tf.function
def gradient_penalty(real, fake, epsilon):
interpolated_images = real * epsilon + fake * (1 - epsilon)
# 각 이미지가 얼마나 사용될건지 epsilon으로 정해줌 (%와 비슷)
with tf.GradientTape() as tape:
tape.watch(interpolated_images)
scores = discriminator(interpolated_images)[0]
# 생성자로 만든 이미지가 아니라 진짜와 가짜가 섞인 interpolated_images 사용
gradient = tape.gradient(scores, interpolated_images)[0]
gradient_norm = tf.norm(gradient)
gp = tf.math.reduce_mean((gradient_norm - 1)**2)
return gpgenerator_optimizer = tf.keras.optimizers.Adam(learning_rate = 0.0002, beta_1 = 0.5, beta_2 = 0.9)
discriminator_optimizer = tf.keras.optimizers.Adam(learning_rate = 0.0002, beta_1 = 0.5, beta_2 = 0.9)checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, 'checkpoints')
#print(checkpoint_prefix)
checkpoint = tf.train.Checkpoint(generator_optimizer = generator_optimizer,
discriminator_optimizer = discriminator_optimizer,
generator = generator,
discriminator = discriminator)학습
epochs = 30
noise_dim = 100
number_of_images = 16
seed = tf.random.normal([number_of_images, noise_dim])# 학습 함수 정의
def training_step(images):
noise = tf.random.normal([batch_size, noise_dim])
discriminator_extra_steps = 3
# 판별자 학습
# WGAN은 생성자보다 판별자 학습 횟수가 많아야함 (원래 논문에서는 5회지만, 학습시간을 줄이기위해 3회만 실시)
for i in range(discriminator_extra_steps):
with tf.GradientTape() as d_tape:
generated_images = generator(noise, training = True)
real_output = discriminator(images, training = True)
fake_output = discriminator(generated_images, training = True)
epsilon = tf.random.normal([batch_size, 1, 1, 1], 0.0, 1.0)
gp = gradient_penalty(images, generated_images, epsilon)
d_loss = loss_discriminator(real_output, fake_output, gp)
discriminator_gradients = d_tape.gradient(d_loss, discriminator.trainable_variables)
discriminator_optimizer.apply_gradients(zip(discriminator_gradients, discriminator.trainable_variables))
# 생성자 학습
with tf.GradientTape() as g_tape:
generated_images = generator(noise, training = True)
fake_output = discriminator(generated_images, training = True)
g_loss = loss_generator(fake_output)
generator_gradients = g_tape.gradient(g_loss, generator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients, generator.trainable_variables))# 이미지 생성, 저장 함수
def create_and_save_images(model, epoch, test_input):
preds = model(test_input, training = False)
fig = plt.figure(figsize = (4,4))
for i in range(preds.shape[0]):
plt.subplot(4,4,i+1)
plt.imshow(preds[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('img_epoch_{:04d}'.format(epoch))
plt.show()# 최종 학습 함수
def train(dataset, epochs):
for epoch in range(epochs):
initial = time.time()
for img_batch in dataset:
if len(img_batch) == batch_size:
training_step(img_batch)
#display.clear_output(wait = True)
create_and_save_images(generator, epoch + 1, seed)
if (epoch + 1) % 10 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print('Time taken to process epoch {} was {} seconds'.format(epoch + 1, time.time() - initial))
#display.clear_output(wait = True)
create_and_save_images(generator, epochs, seed)
generator.save('generator.h5')# 학습하기
train(X_train, epochs)# 체크포인트 저장
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))seed_input = tf.random.normal([number_of_images, noise_dim])
preds = generator(seed_input, training = False)
fig = plt.figure(figsize = (4,4))
for i in range(preds.shape[0]):
plt.subplot(4,4,i+1)
plt.imshow(preds[i, :, :, 0] * 127.5 + 127.5, cmap = 'gray')
plt.axis('off')