[종만북]접두사/접미사 문제
방법 1 .
- 모든 접두사 → |S|개
- 에 대하여, 해당 접두사가, 접미사인지 확인하기
- cmp과정 역시 O(|S|)
총 O(|S|^2) 이 걸린다.
방법2 .
- 일단 , 문자열 S 자신 자체가 접두사이자 접미사임을 생각하자.
pi는 N[...i] 부분 문자열에서 접두사이자 접미사인 최대 길이의 “부분문자열” → 문자열 자신과 같은 거는 포함하지 않았음.
이 정보를 사용할 수는 없을까?
- 이 정보를 사용한다면 , 예를들어 S=”ababbaba” 인 경우, pi[7] = 3 이라는 정보 정도만 사용할 수 있다. ( pi 는 “부분문자열에서, 접두사이자 접미사인 최대 길이 문자열 구하는거니까, 부분문자열중, S와 같아지는 경우는 pi[S.length-1] 임 )
- 그런데 이 값은 “최대인 문자열”임.
- 문제에서는 접두사이자 접미사가 되는 모든 문자열의 길이를 알고싶어한다.
- 즉, 이 보다 작은 길이들은 어떻게 확인할까?
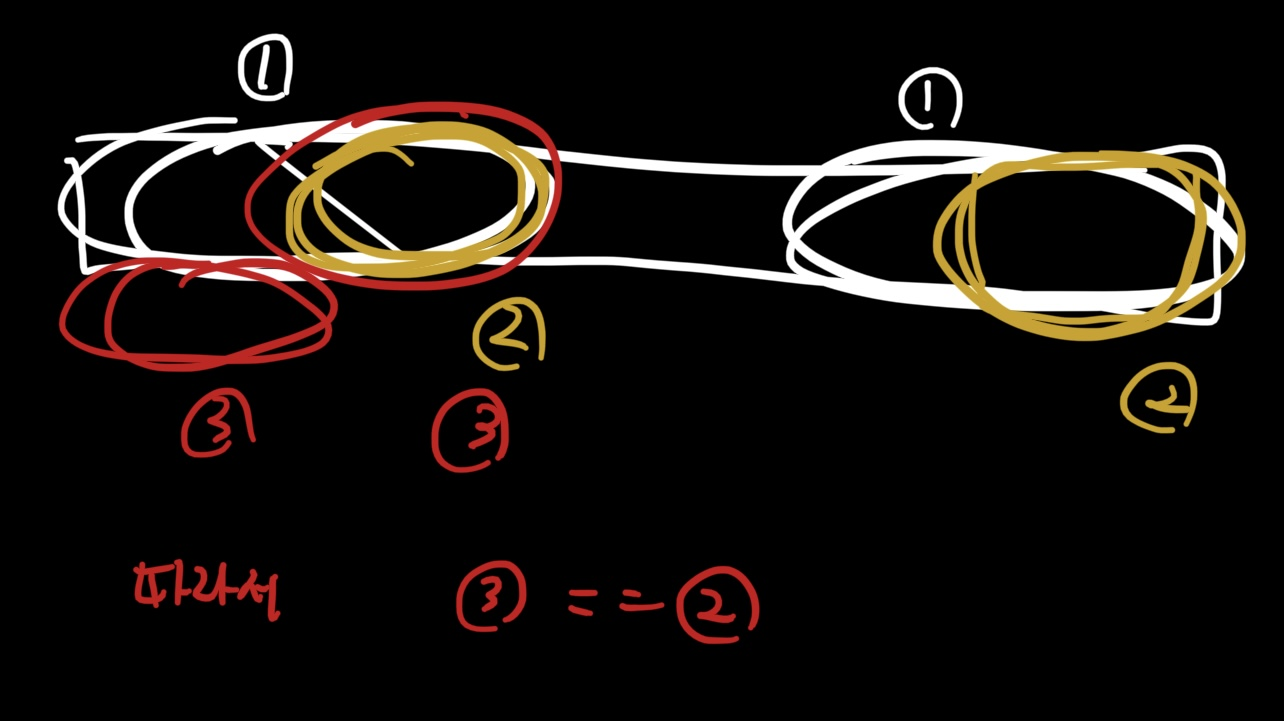
한번에 전부를 확인할 수는 없고, 이를 이용해야 한다.
- 길이가 k “이하” 인 S의 접미사는 S[ .. k-1 ]의 접미사이기도 하다. 즉 S 의 길이가 k인 접미사를 찾고 나면, pi[..k-1 ] 의
- 왜냐하면.. S의 “aba”는 S의 접미사이기도 하지만, 문자열 “aba”의 접미사이기도 함.
- S의 “a”는 S의 접미사이기도 하지만, 문자열 “a”의 접미사 이기도 하다.
즉, 이를 이해하려면 아래의 그림을 생각하면 된다.
ans = new ArrayList<>(); k = pi[s.length()-1]; // 문자열 자신은 ,자신의 접두사이자 접미사. while(k>0){ ans.add(k); k = pi[k-1]; }
- while문의 조건이 왜 k>0일까?
- 생각해보면, k는 항상 줄어들 수 밖에 없기 때문이다.