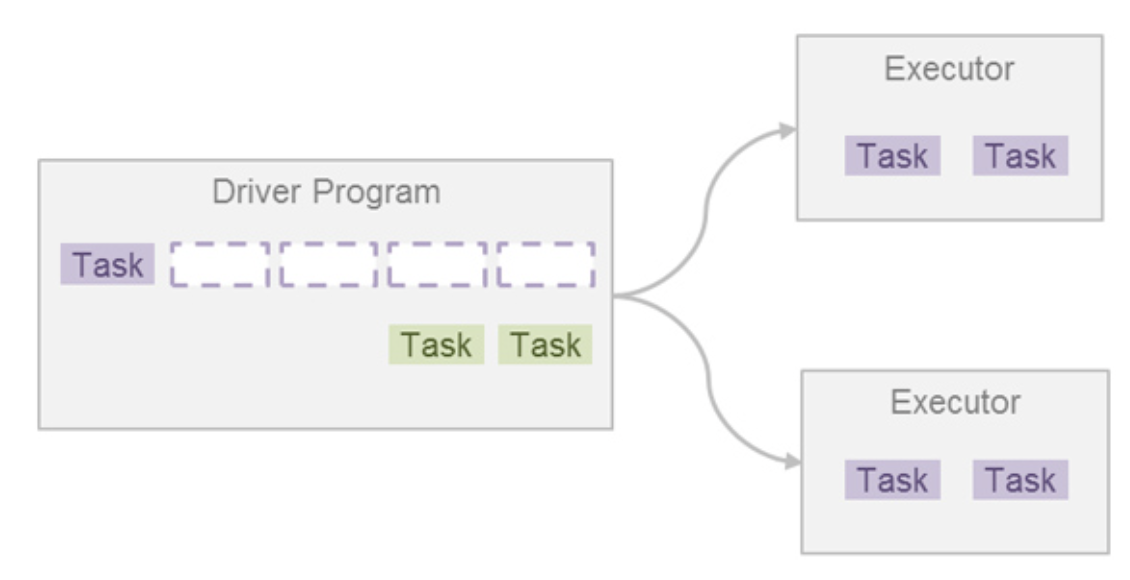
🧚 Fair Scheduler
- 스파크 애플리케이션은 여러 잡을 실행시켜 원하는 바를 달성한다.
- 스파크 잡은 태스크라고 하는 더 작은 실행 단위로 나뉜다.
- 이 태스크는 여러 익스큐터에게 작업 실행을 요청함으로써 병렬 처리가 가능하다.
- 태스크가 종료되면 결과를 받고 다른 태스크를 실행 요청하며, 잡의 모든 태스크가 완료될 때까지 작업 요청을 진행하게 된다.
- 잡의 모든 태스크가 종료되면 다음 잡을 실행할 수 있다.
- 즉, FIFO 구조이다.
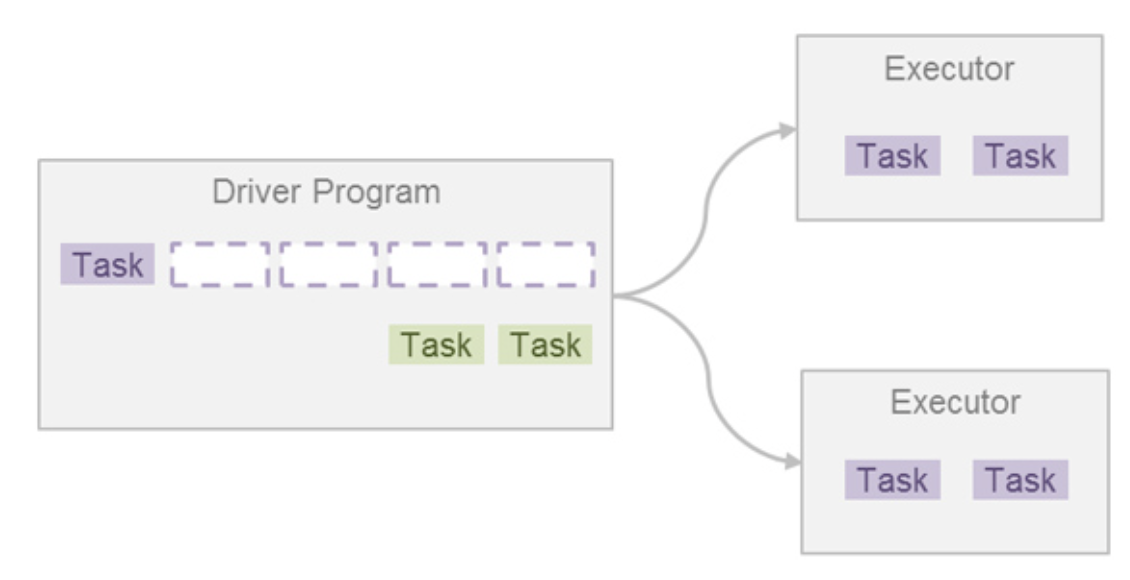
🚨 하나의 잡에서 실행해야 할 태스크가 엄청 많다면?!
- 뒤에 들어오는 잡의 태스크 수가 아무리 적어도 앞선 태스크가 끝나지 않으면 멈춰서 기다려야 한다.
- 이렇게 되면 잡의 순수 실행 시간의 총합은 동일하겠지만, 대기시간(response time)을 포함한 전체 잡의 실행시간(turnaround time)은 어떤 잡이 먼저 실행되었느냐에 따라 다를 수 있다.
💡 Fair Scheduling
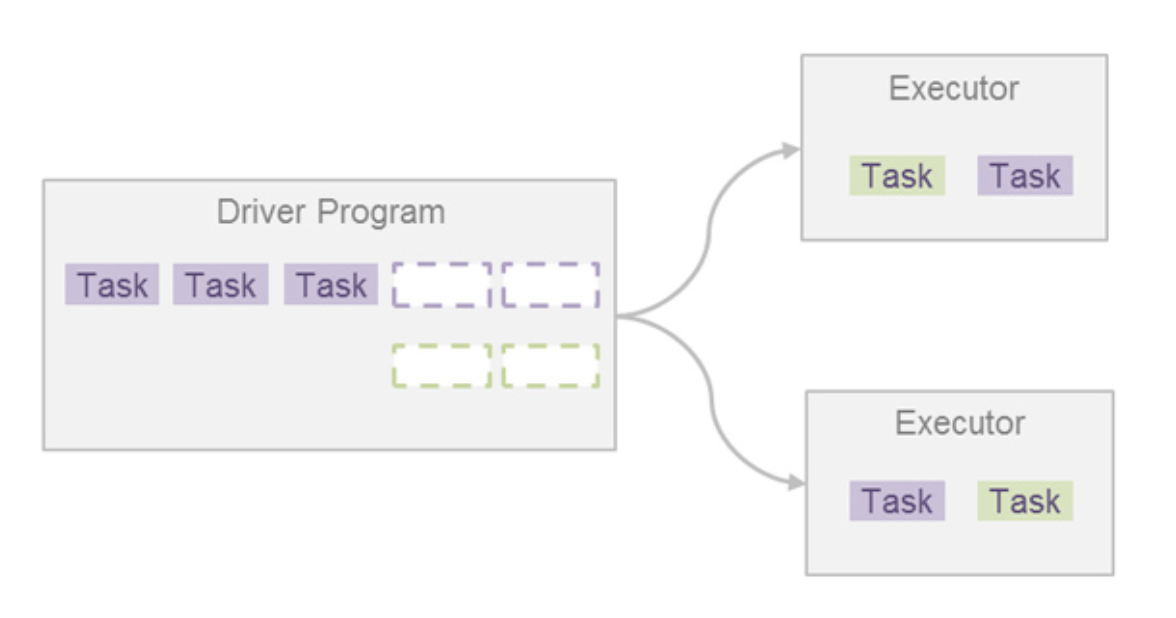
- 위의 문제를 해결하기 위해 Fair Scheduling 기능을 제공한다.
- 스파크 잡은 스파크 스케줄러의 풀(pool) 안에서 동작하게 되는데, 이 풀을 Fair로 설정하면 사용할 수 있다.
- 여러 잡이 제출될 경우 모든 잡에 대해 동일한 양의 리소스를 분배해줌으로써 동시에 여러 잡의 실행이 가능하게 한다.
- 여러 개의 풀을 구성하의 잡 간의 우선순위를 정해줄 수도 있다.
- 이렇게 여러 잡을 동시에 실행시킴으로써 애플리케이션의 총 실행 시간을 줄이고 처리량을 올릴 수도 있다.
➕ Round-Robin 방식
- 장시간 수행되는 스파크 잡이 처리되는 중에 짧게 끝난 스파크 잡이 제출된 경우 즉시 장시간 수행되는 스파크 잡의 자원을 할당 받아 처리한다.
- 사용자가 많은 환경에 적합하다.
🍭 Dynamic Resource Allocation
- 스파크 클러스터에 여러 애플리케이션이 존재할 때 발생하는 이슈를 해결하기 위한 방법
- 스파크 애플리케이션은 클러스터 매니저를 통해 애플리케이션에서 사용할 전체 리소스를 예약해두게 된다.
- 총 몇 CPU cores를 사용할지 클러스터 매니저에 전달함으로써 리소스를 할당 받는다.
- 많은 애플리케이션이 실행되다 보면 사전에 할당 받은 리소스를 사용하지 않는 상황이 발생할 수 있다. (예상보다 데이터가 작거나 애플리케이션의 작업이 상대적으로 빨리 종료되었을 때) → 클러스터에 리소스가 있지만 사용하지 못하는 상황!!
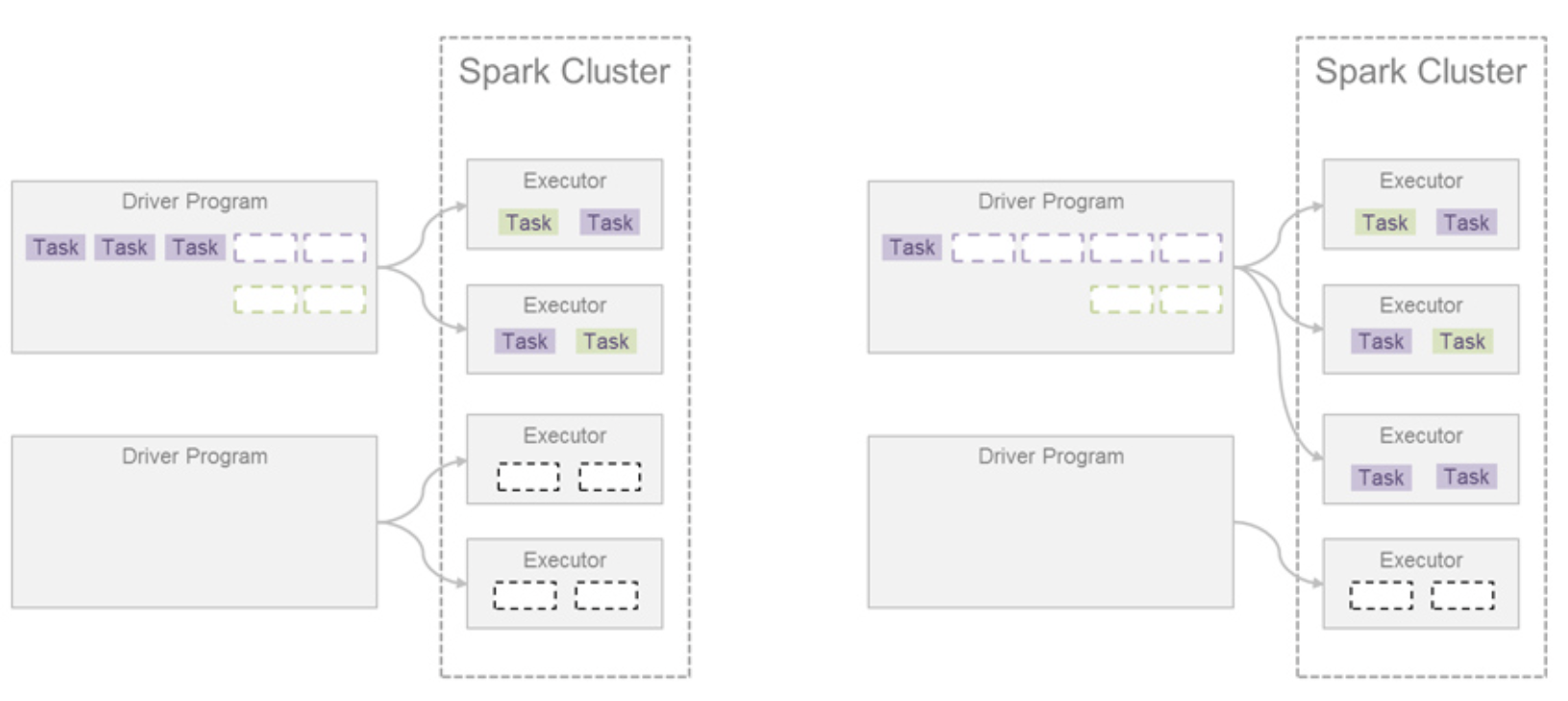
- 이러한 경우 👉동적 자원 할당 기능👈을 활용해 문제를 해결할 수 있다.
- 즉, 리소스를 많이 사용하는 애플리케이션에서 추가로 자원을 요청하는 것이다.
- (주의) 스파크 잡 스케줄러의 리소스 공유 단위는 CPU cores이지만, 동적 자원 할당의 리소스 공유 단위는 Executor이다.
- 한 애플리케이션에서 사용할 수 있는 최대/최소 익스큐터 수를 지정할 수 있는데, 한 애플리케이션에서 전체를 독점하게 되면 다른 애플리케이션이 실행할 때 즉시 대응할 수 없는 문제가 발생할 수도 있다.
⚡ Fair Scheduler를 이용해 Spark Context 내에서 이루어지는 Job들의 경합과 우선순위를 제어할 수 있고, Dynamic Resource Allocation을 통해 Spark Context 간의 효율적 리소스 재분배가 가능하다.
[출처] https://www.samsungsds.com/kr/insights/Spark-Cluster-job-server-2.html

DCDI