spark
1.[Apache Spark] 아파치 스파크(Apache Spark)란? 🧐

빅데이터를 통한 "통합" "컴퓨팅 엔진" 🔑 "통합" : 스파크 하나로 모든 처리를..!빅데이터 애플리케이션 개발에 필요한 통합 플랫폼의 제공이 핵심 목표데이터 읽기, SQL 처리, 스트림 처리, 머신러닝까지 다양한 작업을 같은 연산 엔진과 일관성 있는 API로 수
2.[Apache Spark] 스파크 간단히 살펴보기 🍊
컴퓨터 클러스터는 여러 컴퓨터의 자원을 모아 하나의 컴퓨터처럼 사용할 수 있게 만든다. 이 클러스터에서 작업을 조율할 수 있는 프레임워크가 바로 스파크이다. 스파크는 클러스터의 데이터 처리 작업을 관리하고 조율한다. 스파크가 연산에 사용할 클러스터는 스파크 스탠드얼론
3.[Apache Spark] 스파크 기능 둘러보기 👀

spark-submit 명령을 사용해 대화형 셸에서 개발한 프로그램을 운영용 애플리케이션으로 쉽게 전환할 수 있다.spark-submit: 애플리케이션 코드를 클러스터에 전송해 실행, 실행에 필요한 자원과 실행 방식 등 다양한 옵션 지정 가능클러스터에 제출된 애플리케이
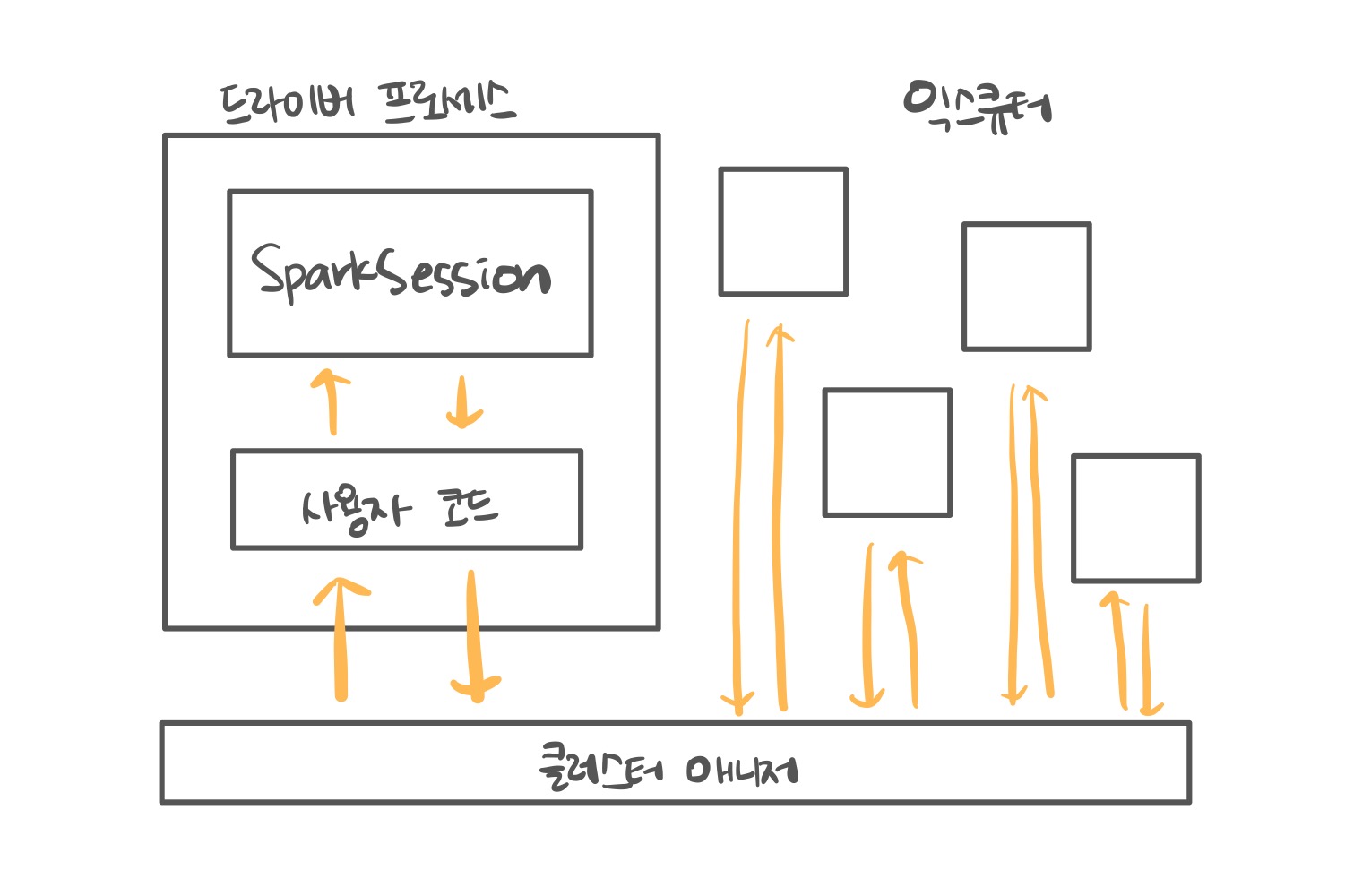
4.[Apache Spark] 스파크 작동 원리
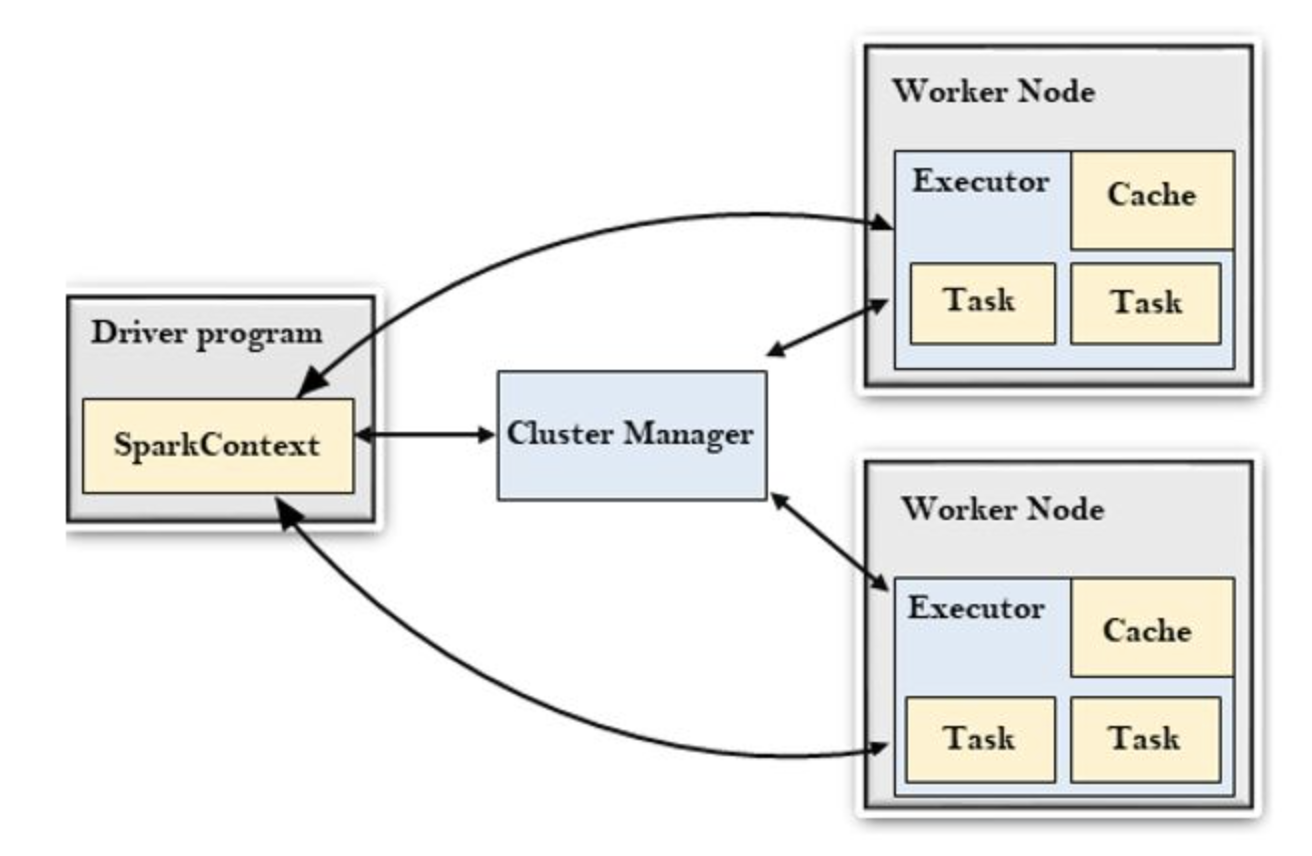
스파크는 데이터를 클러스터에 분산시켜 병렬 처리 한다.master/slave 구조를 사용한다. 하나의 드라이버 프로세스와 다수의 익스큐터 프로세스로 구성된다.spark application = driver + executors클러스터 매니저를 통해 스파크 애플리케이션이
5.[Apache Spark] 구조적 API
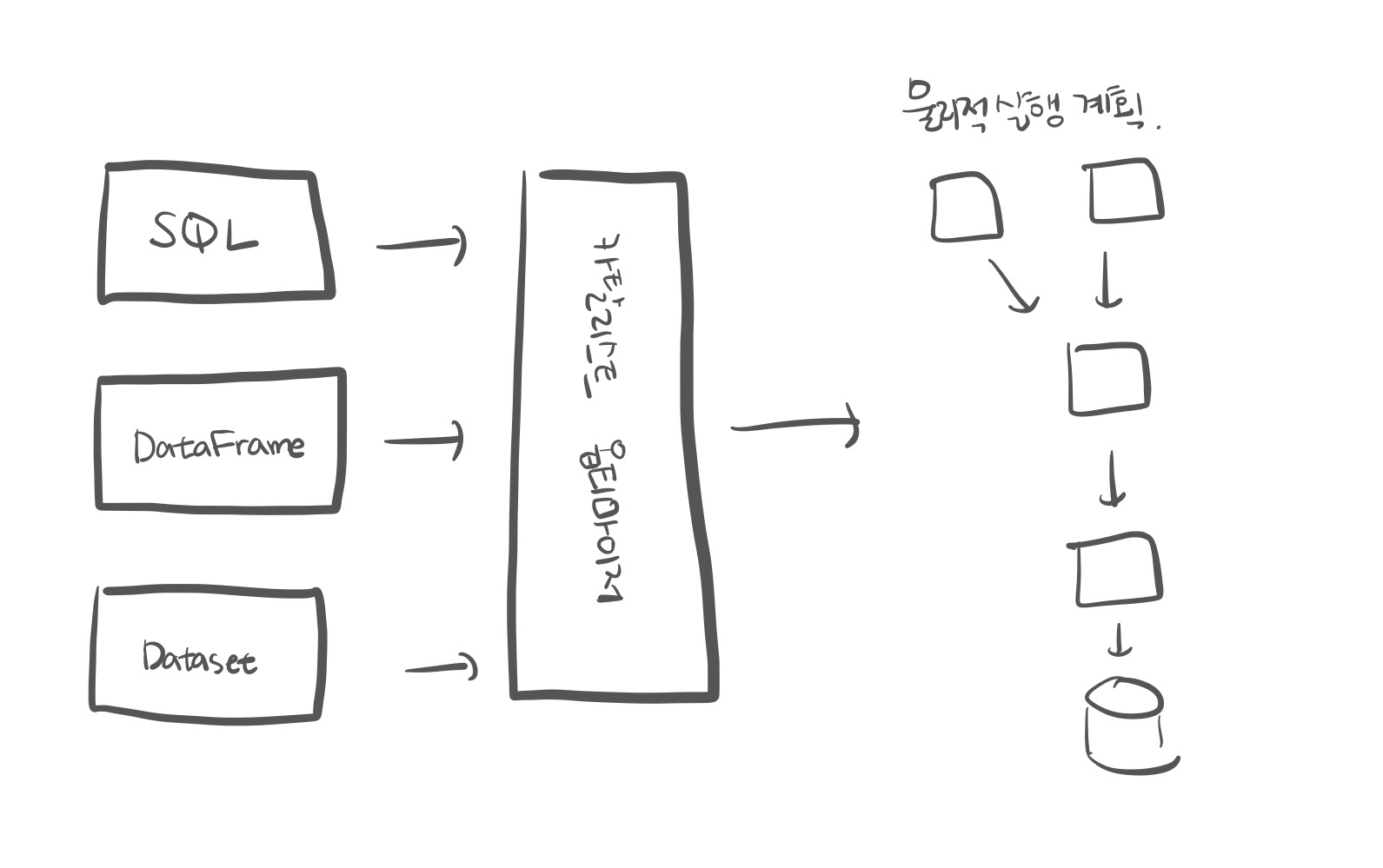
구조적 API는 비정형 로그 파일, 반정형 CSV 파일, 정형적인 파케이 파일까지 다양한 유형의 데이터를 처리할 수 있다.구조적 API에는 세 가지 분산 컬렉션 API가 있다.DatasetDataFrameSQL 테이블과 뷰배치와 스트리밍 처리에서 구조적 API를 사용할
6.[Apache Spark] 구조적 API 기본 연산
DataFrame 레코드의 여러 값에 대한 트랜스포메이션 집합expr 함수로 사용 가능컬럼은 단지 표현식일 뿐이다. expr("somCol")과 col("someCol")은 동일하다.컬럼과 컬럼의 트랜스포메이션은 파싱된 표현식과 동일한 논리적 실행 계획으로 컴파일된다.
7.[Apache Spark] 스파크 연산
스파크는 사용자 정의 함수를 지원파이썬, 스칼라, 외부 라이브러리를 사용해 사용자가 원하는 형태로 트랜스포메이션을 만들 수 있다.스칼라나 자바로 함수를 작성했다면 JVM 환경에서만 사용할 수 있다.파이썬으로 함수를 작성했다면워커 노드에 파이썬 프로세스를 실행파이썬이 이
8.[Apache Spark] 스파크 조인
내부 조인외부 조인왼쪽 외부 조인오른쪽 외부 조인왼쪽 세미 조인: 왼쪽 데이터셋의 키가 오른쪽 데이터셋에 있는 경우에는 키가 일치하는 왼쪽 데이터셋만 유지. 두 번째 DataFrame은 값이 존재하는지 확인하기 위해 값만 비교하는 용도로 사용.왼쪽 안티 조인: 왼쪽 데
9.[Apache Spark] 데이터소스
다양한 데이터소스를 읽고 쓰는 능력과 데이터소스를 커뮤니티에서 자체적으로 만들어내는 능력은 스파크를 가장 강력하게 만들어주는 힘이다! 스파크의 핵심 데이터소스CSVJSON파케이ORCJDBC/ODBC 연결일반 텍스트 파일커뮤니티에서 만든 데이터소스카산드라HBase몽고디비
10.[Apache Spark] 스파크 SQL
스파크 SQL은 스파크에서 가장 중요하고 강력한 기능 중 하나이다. 스파크 SQL은 DataFrame과의 뛰어난 호환성 덕분에 다양한 기업에서 강력한 기능으로 자리매김하였다. 스파크 SQL은 하이브 메타스토어를 사용하므로 하이브와 잘 연동할 수 있다. 스파크 SQL은
11.[Apache Spark] Dataset
Dataset은 구조적 API의 기본 데이터 타입이다. Dataset은 자바 가상 머신을 사용하는 언어인 스칼라와 자바에서만 사용할 수 있다. Dataset을 사용해 데이터셋의 각 로우를 구성하는 객체를 정의한다. DataFrame은 Row 타입의 Dataset을 의미
12.[Apache Spark] RDD
분산 데이터 처리를 위한 RDD브로드캐스트 변수와 어큐뮬레이터처럼 분산형 공유 변수를 배포하고 다루기 위한 API1️⃣ 언제 사용할까?!고수준 API에서 제공하지 않는 기능이 필요한 경우 예) 클러스터의 물리적 데이터의 배치를 세밀하게 제어해야 하는 상황 RDD를
13.[Apache Spark] RDD 고급 개념
RDD에는 데이터를 키-값 형태로 다룰 수 있는 다양한 메서드가 있다<연산명>ByKey 형태 → PairRDD 타입만 사용 가능PairRDD 타입은 RDD에 맵 연산을 수행해 키-값 구조로 만들 수 있다. 즉, 레코드에 두 개의 값이 존재한다.KeyBy: 키를 생
14.[Apache Spark] 분산형 공유 변수
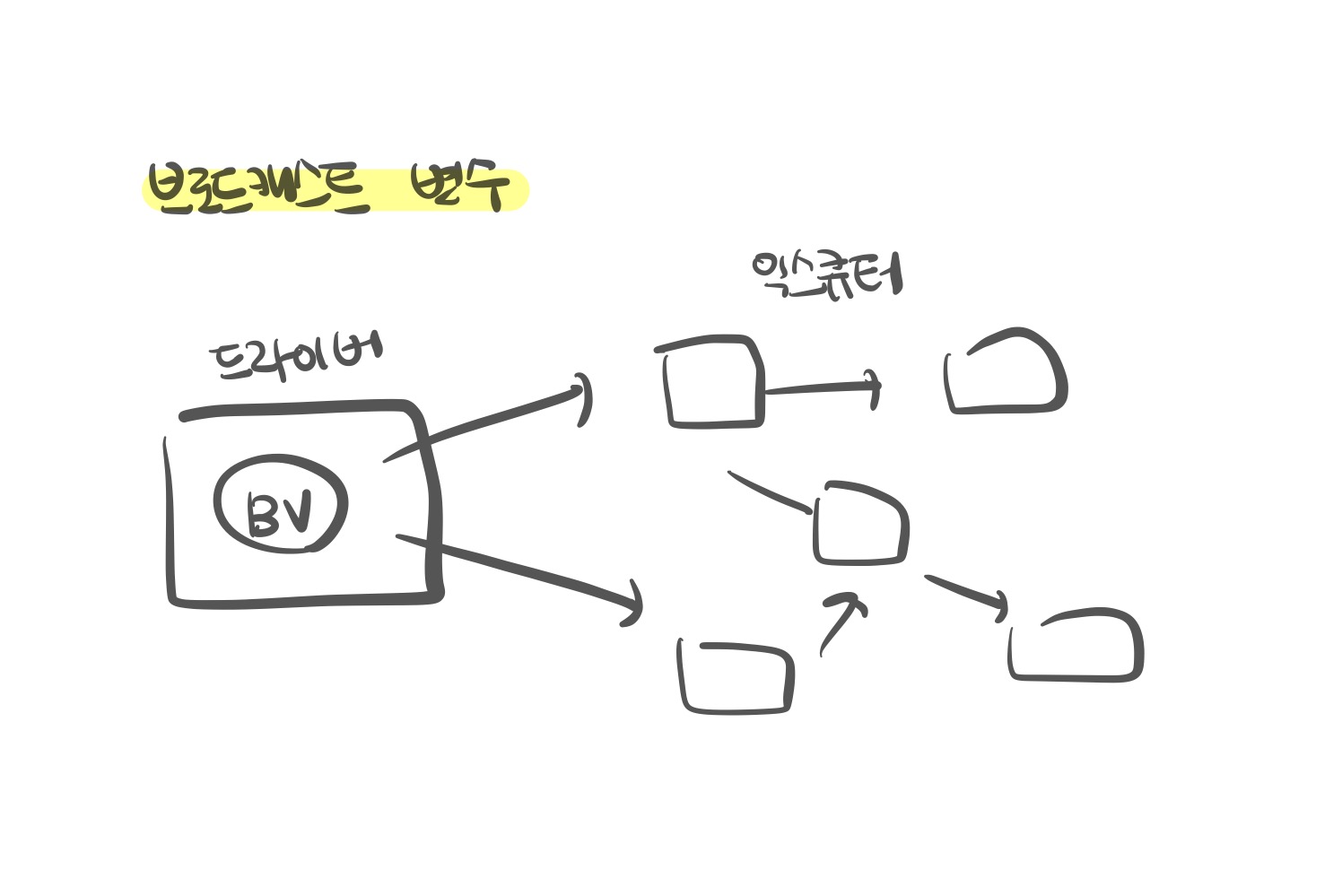
변하지 않는 값을 클로저(closure) 함수의 변수로 캡슐화하지 않고 클러스터에서 효율적으로 공유하는 방법을 제공한다.태스크에서 드라이버 노드의 변수를 사용할 때는 클로저 함수 내부에서 단순하게 참조할 수 있지만, 클로저 함수에서 변수를 사용할 때 워커 노드에서 여러
15.[Apache Spark] 클러스터에서 스파크 실행하기
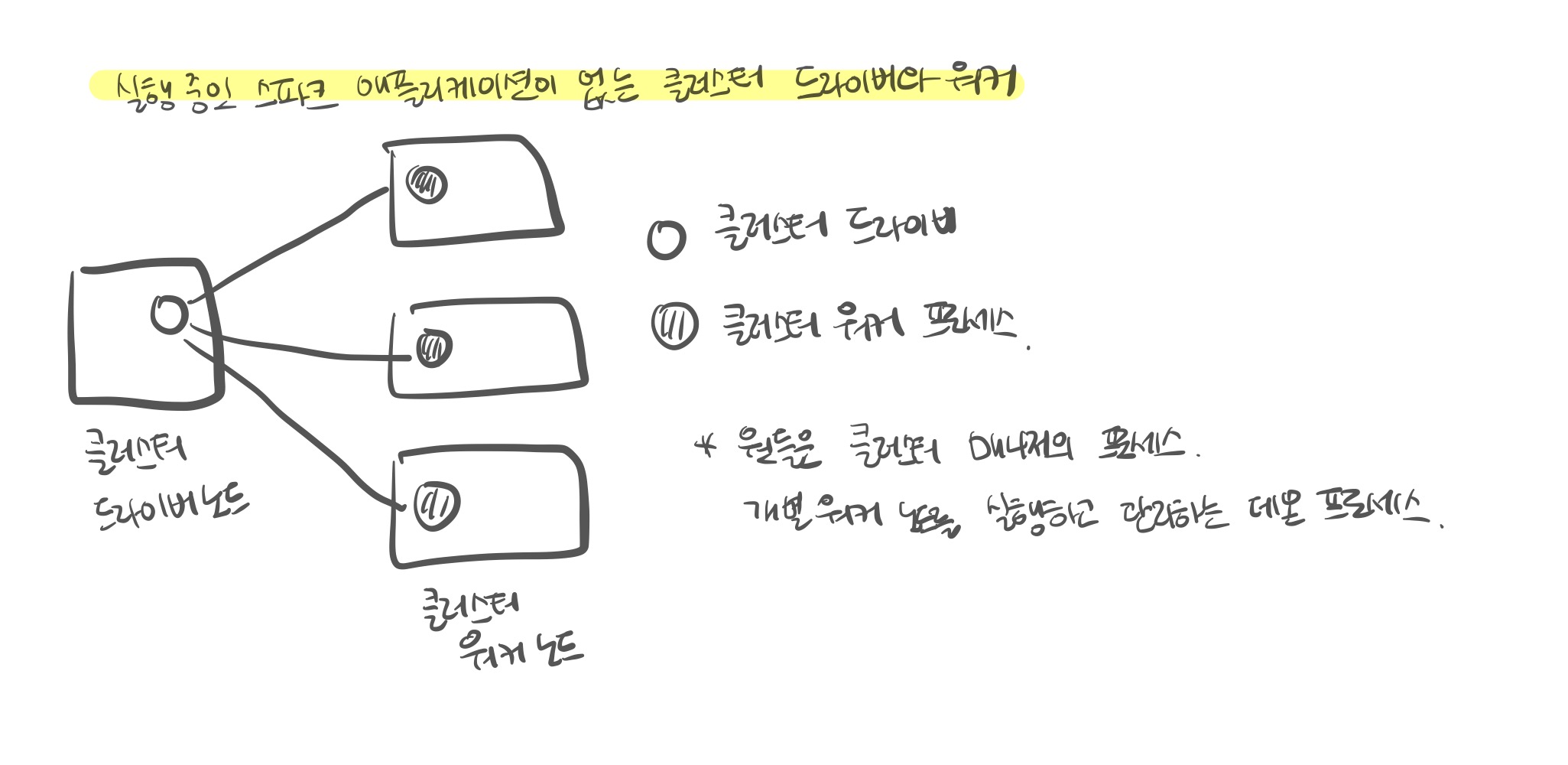
스파크 드라이버스파크 애플리케이션의 실행을 제어하고 스파크 클러스터(익스큐터의 상태와 태스크)의 모든 상태 정보를 유지한다.물리적 컴퓨팅 자원 확보와 익스큐터 실행을 위해 클러스터 매니저와 통신할 수 있어야 한다.스파크 익스큐터스파크 드라이버가 할당한 태스크를 수행하는
16.[Apache Spark] Parquet (파케이)
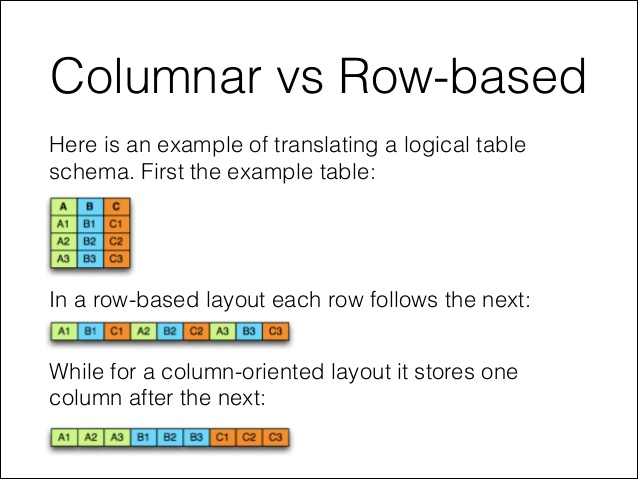
컬럼 기반 포맷같은 종류의 데이터가 모여있어 압축률이 더 높고, 일부 컬럼만 읽어 들일 수 있어 처리량을 줄일 수 있다.스파크에서는 parquet 파일을 손쉽게 읽고 쓸 수 있다.데이터를 분석하기 전 json을 읽어 parquet으로 저장해두고 이후에는 parquet에
17.[Apache Spark] RDD의 내부 동작
파티션 목록각 split을 연산(계산)하는 데에 사용되는 함수의존하는 다른 RDD 목록(optional) Key-Value RDD를 위한 파티셔너(optional) 각 split이 연산되는 데이 최적의 노드 목록 RDD는 여러 개의 파티션으로 이루어져 있고, 하나의
18.[Apache Spark] RDD 재사용을 위한 persist, cache, checkpointing
스파크는 RDD 재사용을 위해 몇 가지 옵션을 제공한다. → persistence, caching, checkpointingRDD 재사용을 통해 퍼포먼스를 향상시킬 수 있는 경우는 아래와 같다. 반복적인 연산매번 연산할 때마다 데이터 세트가 메모리 내에 존재하고 있는
19.[Apache Spark] 스파크 튜닝하기
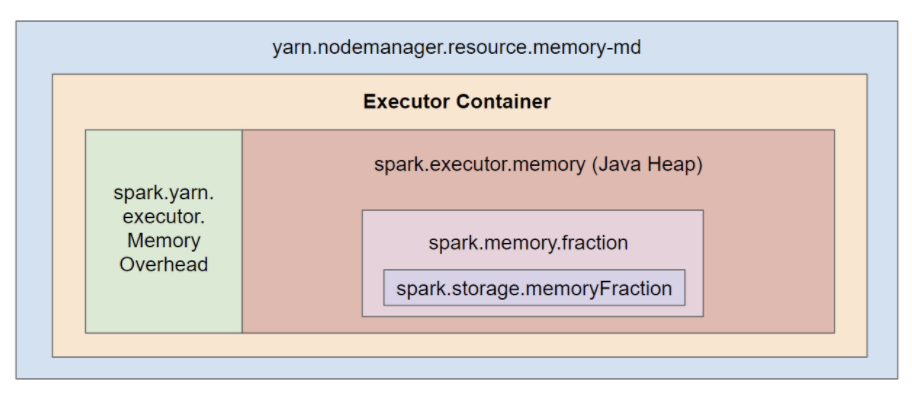
프로그램이 종료되는 많은 원인 중 하나는 Out of Memory(OOM) 에러이다. → Spark 튜닝으로 성능 최적화와 함께 OOM 에러를 해결할 수 있다. 1개의 익스큐터는 하나의 JVM을 갖는다.각각의 익스큐터는 같은 개수의 Core와 같은 크기의 Memo
20.[Apache Spark] 스파크 애플리케이션 개발하기
스파크 애플리케이션 → 스파크 클러스터 + 사용자 코드스칼라는 스파크의 '기본' 언어이기 때문에 애플리케이션을 개발하는 가장 적합한 방법으로 볼 수 있다.스파크 애플리케이션은 두 가지 자바 가상 머신 기반의 빌드 도구인 sbt나 아파치 메이븐을 이용해 빌드할 수 있다.
21.[Apache Spark] 스파크 배포 환경
장점자체 데이터센터를 운영하는 조직에 적합하다.사용 중인 하드웨어를 완전히 제어할 수 있으므로 특정 워크로드의 성능을 최적화할 수 있다.여러 종류의 저장소를 선택할 수 있다.단점설치형 클러스터의 크기가 제한적이다. (너무 작거나 너무 클 수 있음)하둡 파일 시스템(HD
22.[Apache Spark] 모니터링과 디버깅
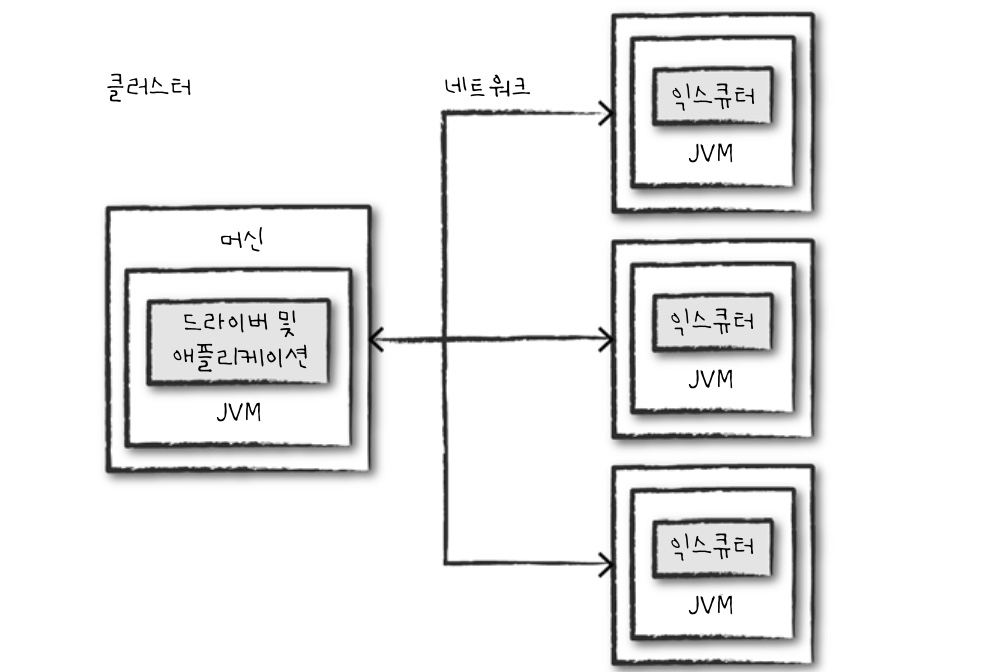
스파크 애플리케이션과 잡클러스터에서 애플리케이션이 실행되는 상황을 파악하거나 디버깅하려면 스파크 UI와 스파크 로그를 확인해야 한다.스파크 UI와 스파크 로그는 RDD와 쿼리 실행 계확과 같은 개념적 수준의 정보를 제공한다.JVM스파크는 모든 익스큐터를 개별 JVM에서
23.[Apache Spark] 성능 튜닝
잡의 실행 속도를 높이기 위한 성능 튜닝 방법을 알아보자!간접적인 성능 향상 → 전체 스파크 애플리케이션이나 스파크 잡에 영향을 미치게 된다. 직접적인 성능 향상 → 개별 스파크 잡, 스테이지, 태스크, 코드 등 특정 영역에만 영향을 주므로 전체 스파크 애플리케이
24.[Apache Spark] 에코시스템
저수준 API(특히 RDD)를 사용하는 경우 유연성을 얻는 대신 성능 저하를 감수해야 한다.파이썬 데이터를 스파크와 JVM에서 이해할 수 있도록 변환하고 그 반대로 변환하는 과정에서 큰 비용이 발생하기 때문이다. 이 과정에는 데이터 직렬화 처리 과정과 함수 처리 과정이
25.[Apache Spark] 스파크 스케줄러
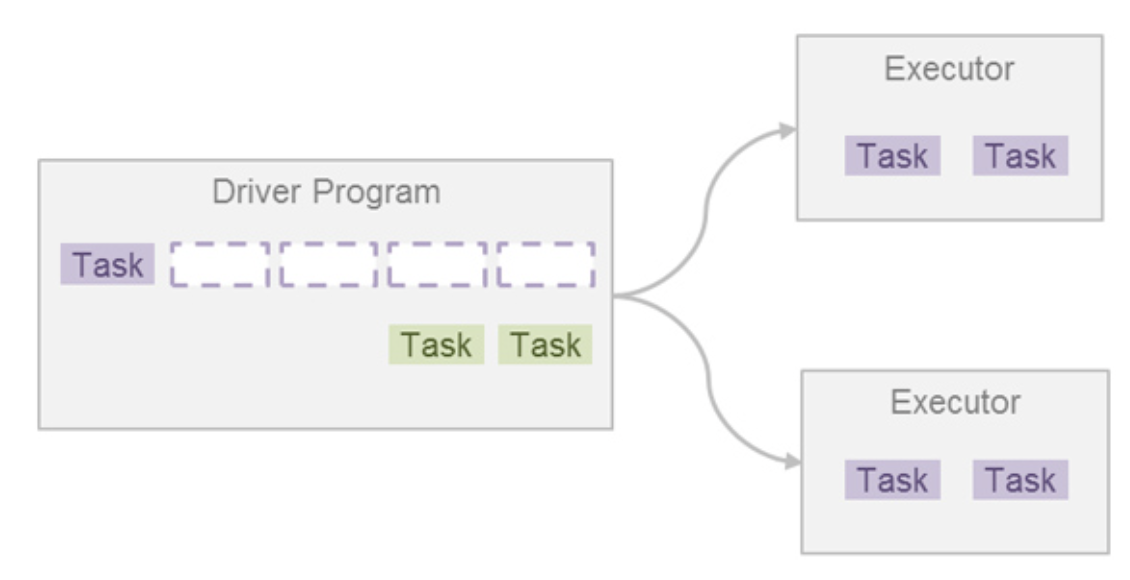
스파크 애플리케이션은 여러 잡을 실행시켜 원하는 바를 달성한다.스파크 잡은 태스크라고 하는 더 작은 실행 단위로 나뉜다.이 태스크는 여러 익스큐터에게 작업 실행을 요청함으로써 병렬 처리가 가능하다.태스크가 종료되면 결과를 받고 다른 태스크를 실행 요청하며, 잡의 모든
26.[Apache Spark] Spark SQL의 카탈리스트 옵티마이저
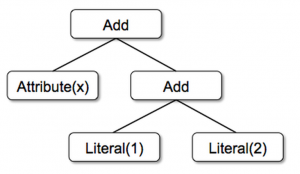
사용하는 데이터 포맷이 parquet이고, SQL만으로 처리할 수 있는 경우 schema에 매핑되는 클래스를 정의할 필요가 없다. Spark SQL에서는 Catalyst Optimizer가 최적화를 대신해준다. DataFrame은 Untyped Data인 Row를 사용