2023-06-04

안녕하세요 !
기른 손톱 다 잘라버린 강대입니다 ㅎㅎ
마음아프지만 너무 얇아서 다 찢어져나가니 그냥 다 깎아버림
오늘은 머신러닝 기초 강의를 듣기 시작했는데요
저번 통계학 강의 시작하면서 이해가 정말 안됐는데
튜터님 라이브강의도 같이 병행하니 이해가 슬슬되는 중이었는데
여기서 머신러닝을 들으니 한 10배는 더 어려운 것 같네요 ,,,,
그치만 ,,, 꺾여도 해야합니다
♾️ 통계적 가설 검정
어제 통계학 복습을 했었는데요
이어서 통계학 가설 검정 목차 좀 더 쉽게 설명해드릴게요 !!
일반적으로 저희는 데이터를 보고 통계를 내릴 때
이렇다 저렇다한 가설을 세우게 되는데요
여기서 예시를 하나 들어볼게요
ex) 공부량은 취업에 영향을 미친다 미치지 않는다.
이런 가설이 2개 있을 때
당연히 둘 중 하나는 맞겠죠?!
귀무가설(영가설) : 공부량은 취업에 영향을 미치지 않는다
대립가설(연구가설) : 공부량은 취업에 영향을 미친다
귀무가설은 HO, 대립가설은 H1이라 표기하기도 합니다
기본적으로 귀무가설은 무조건 부정으로 표현되며, 대립가설은 그와 반대로 긍정으로 표현하면 됩니다.
+통계 프로그램 상 귀무가설만 인식하기 때문에
마지막 결과를 도출할 땐
귀무가설을 채택(지지)한다(맞았다) 또는 귀무가설을 기각한다(틀렸다)
이렇게만 결론을 내릴 수 있습니다 !
또한 통계적 가설 검정의 오류도 있습니다.
1) 실제 H0인데 검정결과 H0를 채택 (올바른 경우
2) 실제 H0인데 검정결과 H0를 기각
3) 실제 H1인데 검정결과 H0를 채택
첫번째는 올바른 검증이구요
두번째와 세번째가 검증에 오류가 난 케이스입니다.
2) 경우
귀무가설이 맞는데 틀렸다고 할 경우 ) 1종 오류 / α오류 라고 칭함.
-마치 무죄인 사람을 유죄로 판결한 것과 같은 상황
3) 경우
귀무가설이 틀렸는데 맞다고 할 경우 ) 2종 오류 / β오류 라고 칭함.
-범죄자를 무죄 판결한 것과 같은 상황
일반적으로 통계학에선 1종 오류를 더 중요시하여 이를 기준으로 잡고,
2종 오류는 최소화가 목표
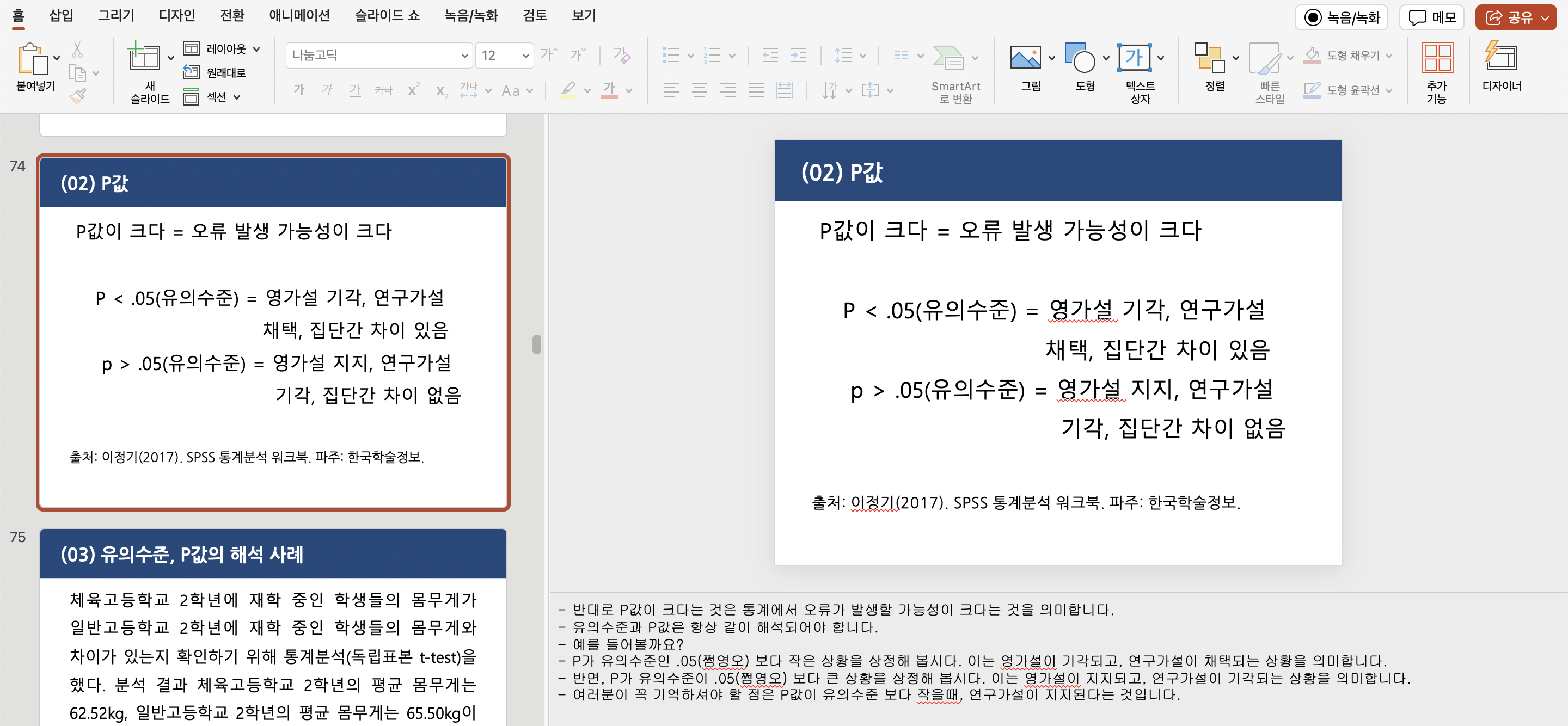
1종 오류가 발생하지 않을 가능성을 신뢰 수준(Confidence level)
= p-value ex)95%
1종 오류가 발생할 가능성을 유의 수준(Significance level)(α)
= .05
어제 설명했다시피 일반적으로는 신뢰수준은 95%, 99%를 이용하며
이를 반대로 오류가 발생할 확률(유의수준)이 5%, 1%를 의미합니다 !!
한편으로는 p=0.0501이나 p=0.0499나 거기서 거기 아니냐..
너무 절대적인 기준 같다고 직관적이지 않다는 의견도 있네요 ,,.
전공 수업 때 남아있던 PPT 자료 덕분에...
저도 통계학을 공부하기 좀 더 수월했던 것 같습니다
이정기 교수님 정말 감사합니다
♾️ 머신러닝이란(Machine Learning) ?!

머신러닝을 알기 전에
큰 개념으로는 AI → ML → DL 이렇게 포괄된 형식으로 생각해주시면 되겠습니다
AI : 인간의 지능을 요구하는 업무를 수행하는 시스템
ML : 관측된 패턴을 기반으로 의사결정을 하기 위한 알고리즘
DL : 인공신경망을 이용한 머신러닝
저도 사실 다들 머신러닝 얘기하는데
이게 대체 뭔데
뭐 어디서 쓰는 건데?!?!?!? 싶었는데 알아왔습니다
금융에선 신용평가, 대포 통장으로 의심되는 걸 찾을 수 있구요
e-커머스에선 개인화 쿠폰 전송, 상위 노출 아이템, 장바구니 분석 등
있어요 !!
이같은 머신러닝을 왜 사용하느냐 ?!?!?
과거엔 제한된 데이터에서 모집단으로 추론하며 데이터 분석을 했지만
현재는 모든 데이터를 수집한 후 최적화를 통한 패턴을 보존하게 됩니다
과거와 같은 잘못된 분석, 실수(휴먼에러)를 하지 않기 위해서
머신러닝을 통해 + 휴먼터치를 통해 좀 더 매끄러운 데이터 분석을 할 수 있습니다
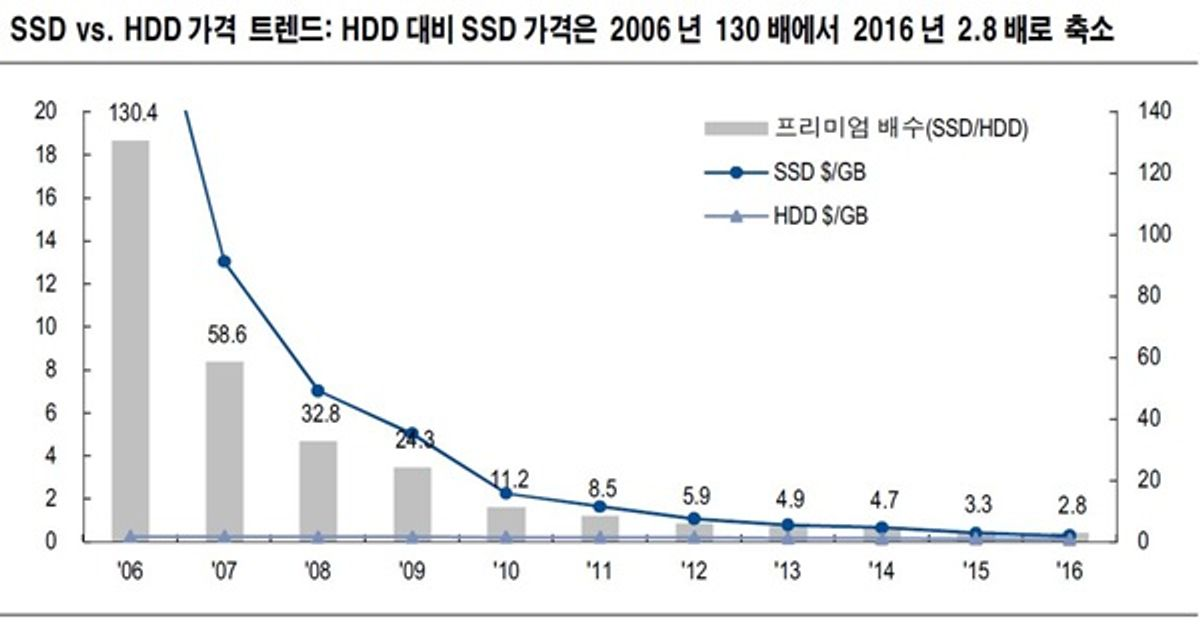
또한 저장매체의 가격이 하락하면서
그동안 저장매체가 비싸서 데이터를 제한해서 저장했지만!
시대의 흐름에 따라 저장매체가 저렴해지고
더 많은 데이터를 저장할 수 있기 때문에
인사이트 도출이 쉬워지고
(= 배경지식이 더 풍부해짐 = 데이터를 더더 수집할 수 있기에)
데이터 수집이 용이해집니다 !
아~주 쉽게 더 비유해보자면
프로젝트 팀플을 진행할 때 만약,, 자동차라는 데이터에 무지한 제가
프로젝트를 진행하면 많이 헤매겠지만
구글이라는 데이터가 풍부한 곳에 가서 이것저것 데이터를 학습해온다면
프로젝트를 좀 더 매끄럽게 진행할 수 있겠죠 ?!
뭐 이런 메타라고 합시다
기저귀를 사면 맥주를 구매한다고요? :
https://ablearn.kr/newsletter/?idx=13468198&bmode=view
머신러닝 아티클 :
https://modulabs.co.kr/blog/machine-learning/
오늘도.. 어떻게든 이해해보려 노력한 하루였습니다
좋은 잠 주무시고
내일 또 뵙겠습니다 !
고생 많으셨어요 🍀🍀🍀
