2024-06-03

안녕하세요 😇😇
다들 주말 잘 보내셨나요
진짜 6월이네용 ,,,,
부트캠프 진행하면서 이제 한 다음주,,? 다다음주 정도면
진짜 정신없이 보낼 것 같아요
벌써 두렵내요 🥲
♾️ f-string
f-string은 사실 그동안 데이터 시각화하면서 자주 쓰긴 했는데
정확히 어떻게 작용하는지 몰라서 알아봤습니다 !!
qwert = 'super'
tyty = 50
print(f"제 힘은 완전{qwert}쎄요. {tyty}만큼")약간 말도 안되는 걸로 가져와봤는데요
f-string은 파이썬의 문자열 포맷팅 방법으로, 변수나 표현식을 문자열에 삽입됩니다
중괄호 {} 안에 변수나 표현식을 넣고,
포맷팅 옵션을 지정하여 원하는 형식으로 값을 문자열에 기재할 수 있습니다 !

그래서 위코드처럼 입력 시
제가 쓴 코드 그대로 값이 들어가 있는 걸 볼 수 있습니다
♾️ 통계학 실습 코드
위와 똑같은 f-string을 통계학 평균 강의에서 실습 코드로 보면
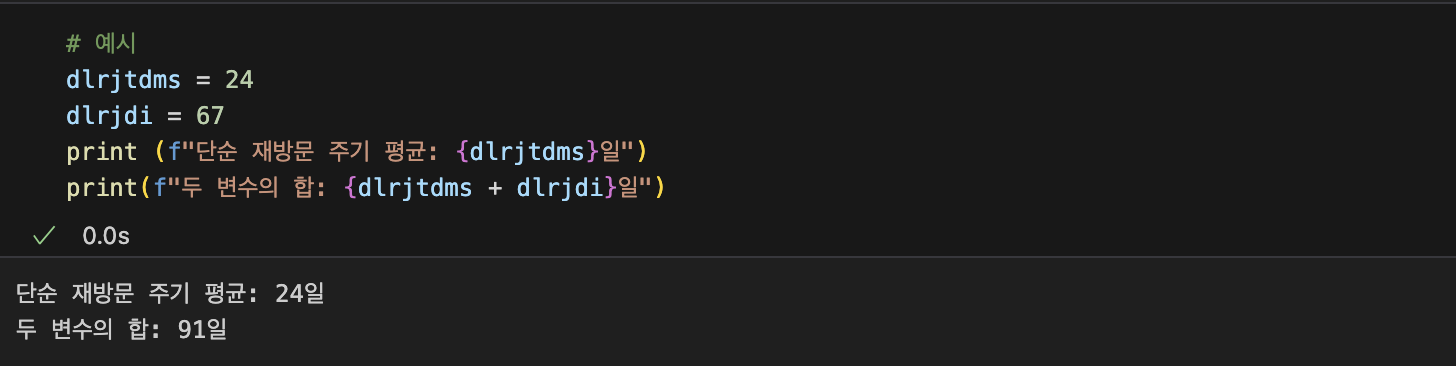
## 유저별 재방문 주기
revisit_freq_by_user = df.groupby("user_id").days_since_prior_order.mean()
revisit_freq_by_user_mean = revisit_freq_by_user.mean()
revisit_freq_by_user_median = revisit_freq_by_user.median()
print(f"단순 재방문 주기 평균: {revisit_freq_by_user_mean:.2f}일")
print(f"단순 재방문 주기 중앙값: {revisit_freq_by_user_median:.2f}일")
단순 재방문 주기 평균: 15.47일
단순 재방문 주기 중앙값: 14.69일
(실제 원본 일수)
15.469669692770578일
14.692307692307692일위 코드는 평균의 평균 및 중앙값을 구해준 셈이라
원래는 정수였지만 실수로 생성이 됩니다 !
제가 처음에 만들었던 f-string 코드와는
조금 다르죠 ?!
뭔지 알아채셨나요 ?!
출력 시 맨 처음에 f를 입력해준 다음 문자열을 입력하고 끝냈었는데
이번에는 소수점과 마지막으로 f를 넣어서 총 f가 두번 들어갔어요
.2f는 소수점 둘째 자리까지 반올림하여 부동 소수점 숫자를 포맷팅하는 옵션
revisit_freq_by_user_ 변수를 소수점 둘째 자리까지 포맷팅하여 읽기 쉽게 출력
print(f"단순 재방문 주기 평균: {revisit_freq_by_user_mean:.0f}일")
print(f"단순 재방문 주기 중앙값: {revisit_freq_by_user_median}일")
단순 재방문 주기 평균: 15일
단순 재방문 주기 중앙값: 14.692307692307692일이번엔 소수점 처리를 0으로 해봤고
소수점 포맷팅 없이 출력을 해봤어요 !
0으로 처리해주면 소수점없이 야무지게 정수로 처리해주고요
소수점 없이 포맷팅하면 ..
반올림 없이 모든 소수점까지 표기됩니다 ! 당연함
f-string으로 연산도 가능 !
당연함
♾️ 편차, 분산, 표준편차
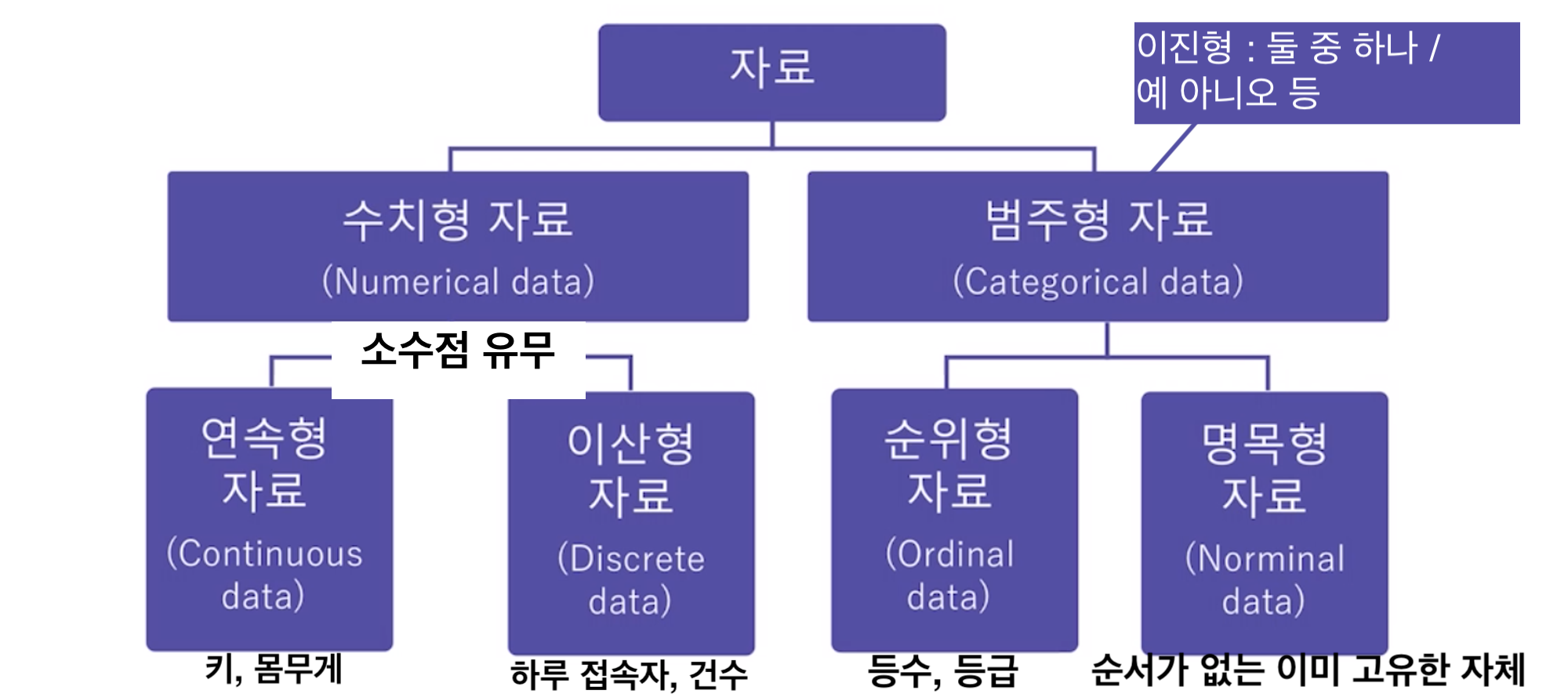
너무 허접하지만,, 이게 데이터의 종류입니다 !
냅다
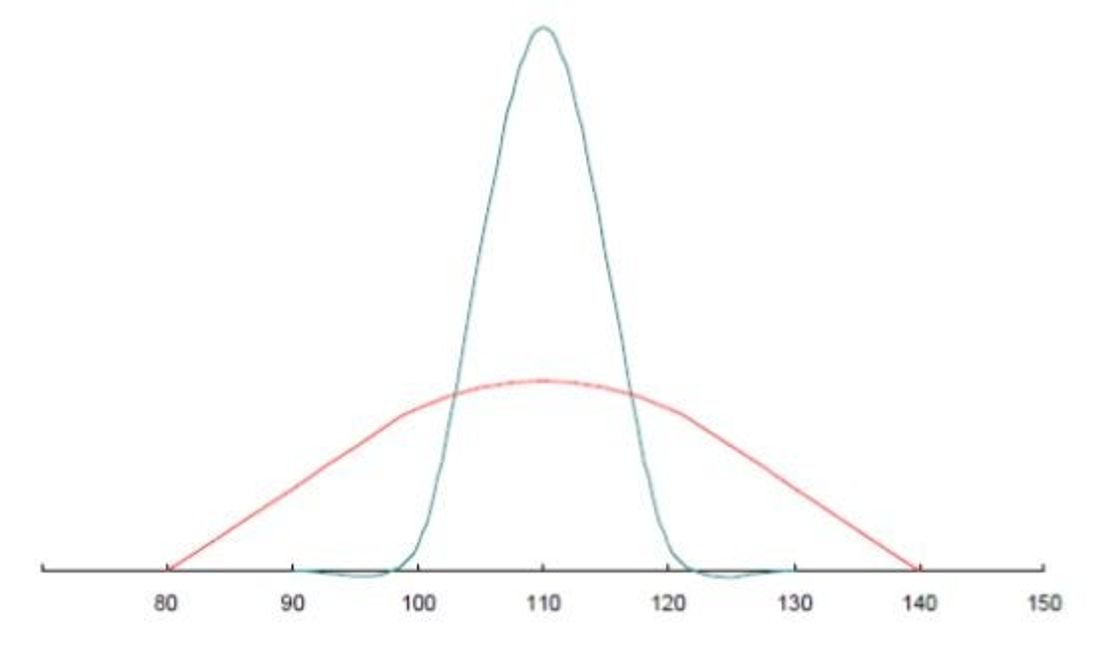
위 그래프는 둘 다 평균이 똑같습니다 !!
그치만... 뭔가,,? 다르죠?!
빨간선은 뭔가 넓은데 낮고
파란선은 짧은데 높고
근데 평균이 똑같아요
이거는
데이터가 WHERE=(어디에 존재하는가) 라고 생각됩니다
위 데이터를 가지곤 평균이 데이터의 대표가 되지 못한다고 생각되기에
저희는 분산과 편차 ‘HOW = 어떻게 존재하는가’에 대해 배우겠습니다 ~!!!
편차(deviation) : 하나의 값에서 평균을 뺀 값 = 평균으로부터 얼마나 떨어져 있는지
- A 학생의 국어점수 : 30점
- B 학생의 국어점수 : 70점
- C 학생의 국어점수 : 80점
- A, B, C 학생의 평균 국어점수 : 60점
> A 학생의 편차 : -30
> B 학생의 편차 : +10
> C 학생의 편차 : +20분산(variance)/ 편차 제곱합의 평균
: 편차의 합이 0으로 나오는 것을 방지하기 위해 생성된 개념
- A 학생의 편차 제곱 : (-30)^2 = 900 (음수와 음수를 곱하면 양수)
- B 학생의 편차 제곱 : (+10)^2 = 100
- C 학생의 편차 제곱 : (+20)^2 = 400
편차 제곱합 : 1400
편차 제곱합의 평균(분산) : 1400/3 = 466 표준편차 : 분산에 제곱근을 씌워준 값
(= 원래 단위로 되돌리기 = standard deviation(σ))
분산 : 466분산의 제곱근 = 표준편차 = 약 21.6
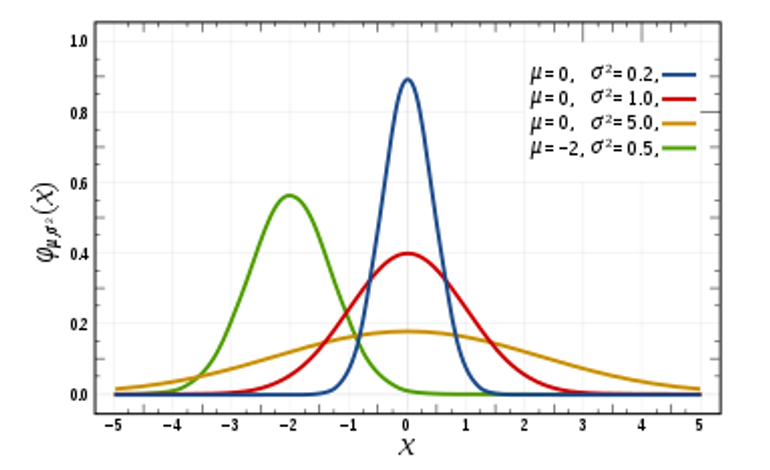
위 총 4개의 그래프는 모두 왜도가 없어 정규분포이지만
평균 0, 분산 1을 가지는 경우 이를 표준정규분포라 합니다
♾️ 신뢰구간, 신뢰수준
👩 : 언제 와?
👨 : 10-15분 정도?!
여기서 10-15분은 = 신뢰구간
12.5분은 평균일 뿐이지
정말 12.5분에 도착할 지 안 할지는 아무도 몰라 ...
또한 모든 데이터는 모집단에서 표본으로 추출됨과 동시에 !!!!
불확실성을 가지게 됩니다
신뢰구간 : 특정 범위 내에 값이 존재할것으로 예측되는 영역
😇 : 수학 점수가 10점에서 90점 사이일 것 같아요
신뢰수준 : 실제 모수를 추정하는데 몇 퍼센트의 확률로 신뢰구간이 실제 모수를 포함하게 되는 확률 (주로 95%, 99% 이용)
😇 : 수학 점수가 10점에서 90점 사이에 분포할 확률이 95% 같아요
시간을 써도 써도 부족한 통계학이었습니다 ^~^
후우 내일은 좀만 더 열심히 해볼게요
오늘도 고생하셨습니다 🍀🍀
