2024-05-31

안녕하세요 ~!
5월의 마지막 날이네요 🥹
오늘은 통계학 강의를 모두 완강하고
이해하기 너무 어려워서 2회독하고 있었습니다
제가 이해하기 쉬우려고 좀 엉터리로 요약한 경향이 있지만 ,,
암튼 !!!
유종의 미를 거두며 오늘도 화이팅팅 🍀
♾️ 평균을 망치는 왜도와 이상치
왜도 Skewness
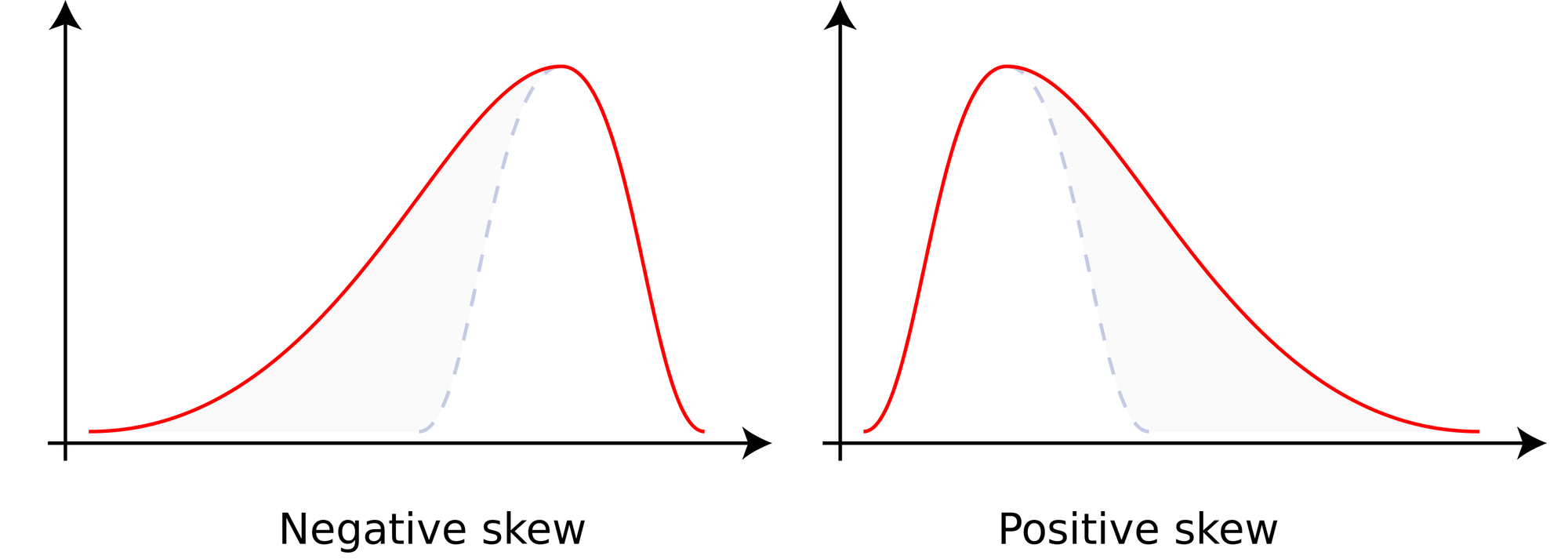
왜도는 특정한 방향으로 데이터가 쏠려있는 현상이며
왼쪽은 우측으로 쏠렸고, 오른쪽은 좌측으로 쏠린 걸 알 수 있습니다 !
이처럼 왜도현상이 일어나면 위 데이터의 평균을 대표하지 못합니다 !!
= 자격 없다는 말
♾️ 확률분포
우리가 아는 확률과 분포의 의미를 생각하시기 보단 ~!
여러 확률들을 이런 저런 케이스라고 지칭한 것
이라고 알면 될 것 같습니다
→ 베르누이 분포
둘 중에 하나
자격증 시험을 보고 합격할 확률
성공: 합격 (확률 p)
실패: 불합격 (확률 1-p)
광고를 클릭할 확률
성공: 클릭 (확률 p)
실패: 클릭하지 않음 (확률 1-p)
가능한 결과인 2개(성공, 실패)를 가지는 경우만 사용
이 분포는 단일 시행에서 성공할 확률을 나타내며, 성공과 실패 이 두 개뿐
확률 변수 = x
성공 = 1
실패 = 0
성공 확률 = p
P(X = 1) = p
P(X = 0) = 1 - p
여기서,
p는 성공 확률 (0 ≤ p ≤ 1)
1 - p는 실패 확률→ 이항 분포
시행 횟수 (n): 베르누이 시행의 총 횟수
성공 확률 (p): 각 베르누이 시행에서 성공할 확률
실패 확률 (q): 각 베르누이 시행에서 실패할 확률
성공 횟수 (k): 총 n번의 시행 중 성공한 횟수동전 던지기
상황 : 동전을 10번 던졌을 때 앞면이 6번 나올 확률
파라미터 : n = 10, p = 0.5(앞면이 나올 확률)
시험 합격
상황 : 20명의 학생이 똑같은 시험을 볼 때, 각 학생의 합격률이 0.7일 때, 15명이 합격할 확률
파라미터 : n = 20, p = 0.7(합격할 확률)
이항 분포는 독립적인 베르누이 시행을 여러 번 반복했을 때 성공 횟수를 모델링하는 데 사용된다.
이는 다양한 실제 상황에서 특정 사건이 일정한 확률로 발생하는 경우를 분석하는 데 매우 유용한 도구이다파라미터란
요리와 비유를 해보자면
레시피에는 필요한 재료와 어떻게 조리해야 하는지에 대한 설명이 있습니다.
레시피에서 "고춧가루 3숟갈"라는 지시가 있다면,
이는 요리에 필요한 고춧가루의 양을 나타내는 파라미터이다.
→ 정규 분포
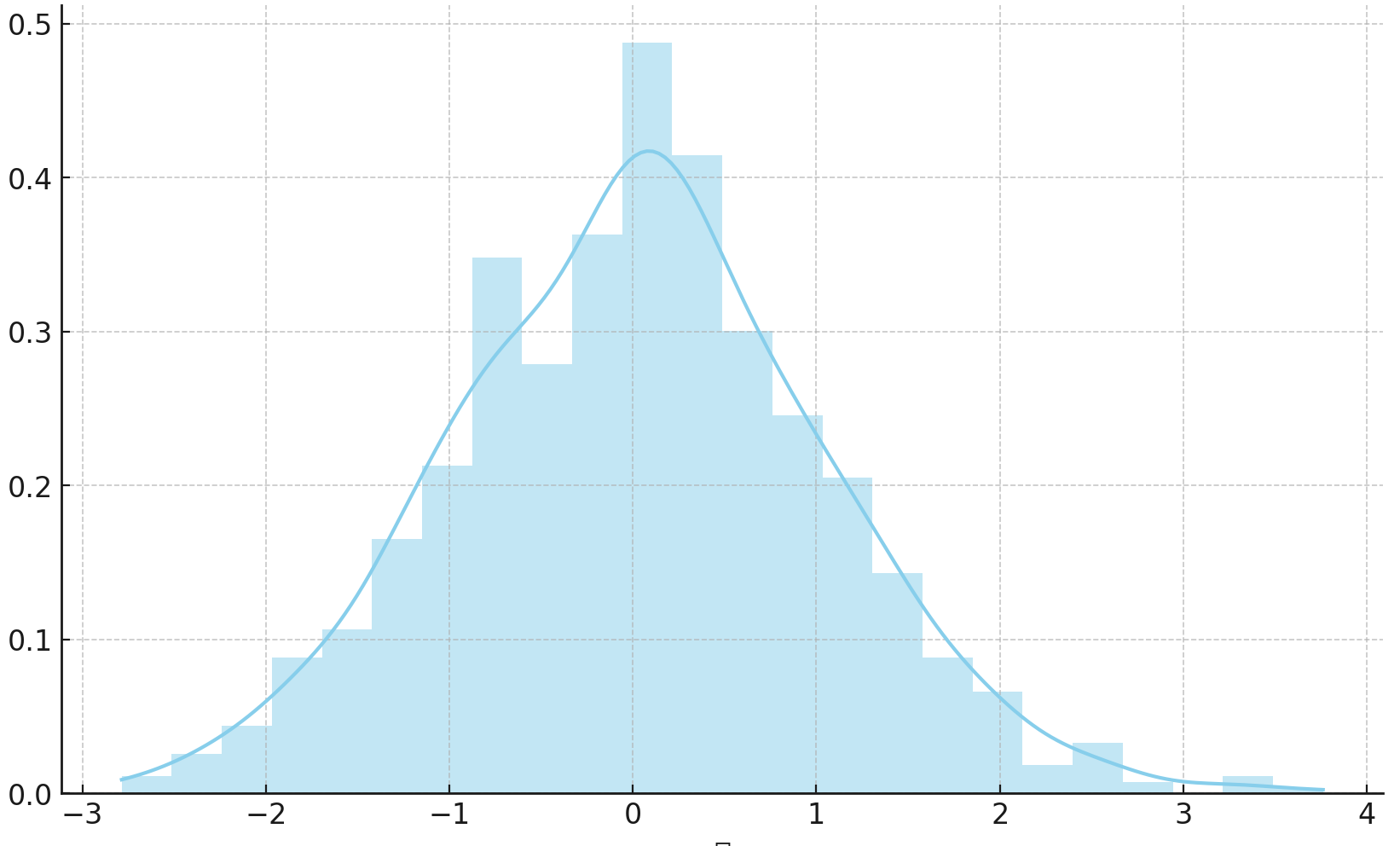
위 그래프처럼 종 모양의 곡선을 가지는 형태가 정규 분포다 !
중심을 기준으로 좌우로 대칭이고,
표준편차(std)가 작으면 곡선이 좁고 표준편차가 클수록 곡선이 넓다 !
많은 자연 현상과 데이터 분포를 설명하는 데에 사용되며, 통계 분석이나 가설 검정 등 다양한 분야에서 활용됩니다.
예시로는 고등학교 학생들의 키, 한 학년의 시험 점수
정도로 생각하면 쉽습니다 !
= 왜도가 없는 가운데로 솟은 분포
이렇게 대표적인 확률분포를 3가지 알아보았구요 !
♾️ 중심 극한 정리(Central Limit Theorem)
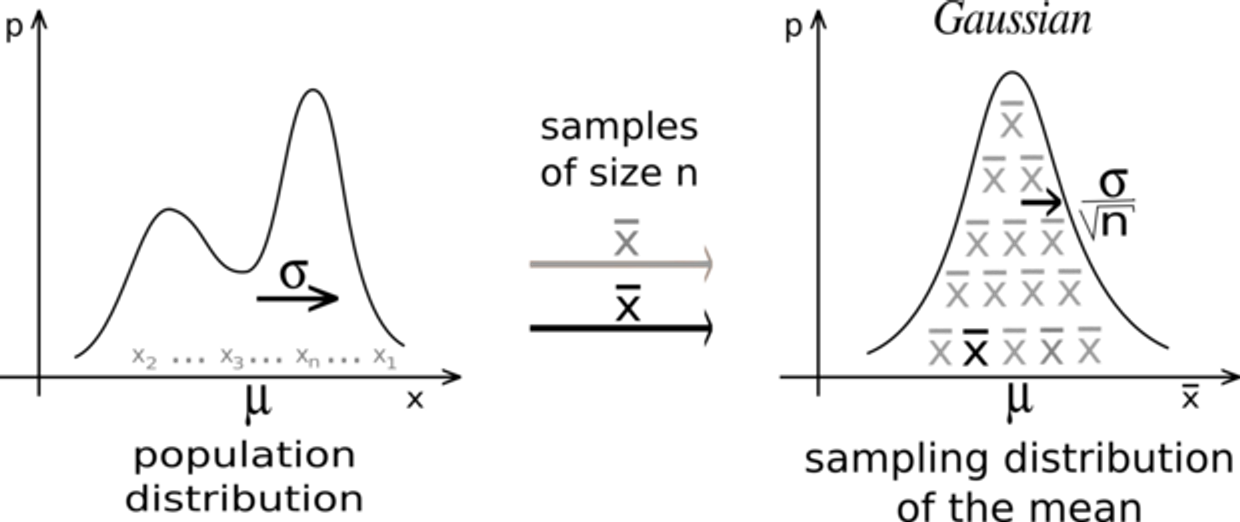
표본의 분포와 무관하게 표본 평균의 분포가 정규분포
= 원래 데이터의 분포가 뭐였든지 간에 !! 정규분포가 아니었어도 !! 표본 평균의 분포가 정규 분포 !!!!!
이런 것이 중심 극한 정리라고 합니다....
위 같은 경우는 한 마디로 데이터가 개개많이 쌓였거나
실험을 반복적으로 많이 시행했을 시에
정규분포와 같은 형태를 띈다고 보면 됩니다
동전 던지기를 하는데
만약 동전을 수 천 번 던진다면, 각각의 시행마다 나오는 앞면의 수를 모두 더한 후 전체 시행 횟수로 나눈 값들의 분포는 정규분포에 가까워집니다 !!!!
네,,, 통계를 어떻게든
이해해보려고 했던 저의 하루였구요
주말에 짬내서 더 공부해보겠습니다 !!
여러분들 중간에 꺾여도 그냥 하는 게 훨씬 낫습니다
몸 잘 챙기시고 담주에 봬요 🍀🍀🍀
