2024-06-14

안녕하세요 ,,,,,,
다시 또 인후염 도져서 골병 앓다가
돌아온 강대입니다 ,,,
다들 덥다고 가습기를 멀리하지 마십시오
저처럼 목 건조해서 인후염 도집니다 😶🌫️
♾️ 선형회귀 실습
독립변수 1개, 종속변수 1개로 이뤄진
단순 선형 회귀의 코드를 보여드릴게요 !!
weights = [87, 81, 82, 92, 90, 61, 86, 66, 69, 69]
heights = [187, 174, 179, 192, 188, 160, 179, 168, 168, 174]
print(len(weights))
print(len(heights))간단히
키와 몸무게의 상관관계를 파악하고
선형회귀 모델을 만들어볼게요
sns.scatterplot( data = body_df, x = 'weight', y = 'height')
plt.title('Weight vs Height')
plt.xlabel('weight(kg)') # 독립변수
plt.ylabel('Height (cm)') # 종속변수
plt.show()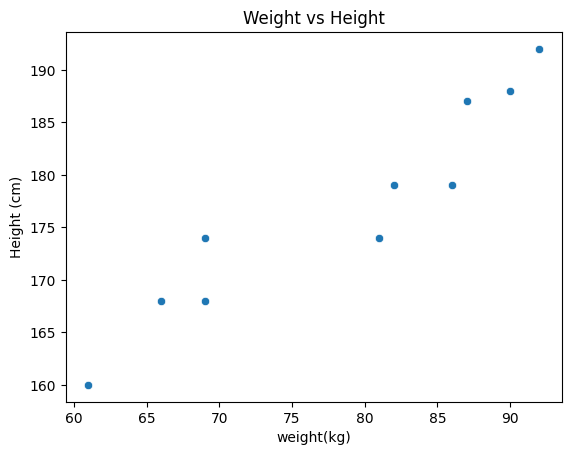
이렇게 산점도를 출력해보면
직선을 그리는 형태로 선형회귀 그래프를 만들어볼게요 !!
## 모델설계도 가져오기
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
type(model_lr)
## x,y축 설정
X = body_df[['weight']]
y = body_df[['height']]
# 선형회귀 모델 학습시키기
model_lr.fit(X = X, y = y)
# 가중치, 회귀계수(w1)
print(model_lr.coef_)
# 편향(w0)
print(model_lr.intercept_)
w1 = model_lr.coef_[0][0]
w0 = model_lr.intercept_[0]
## 선형방정식
print('y = {}x + {}'.format(w1.round(2),w0.round(2)))
>> 결과 : y = 0.86x + 109.37위 결과는
몸무게 1kg 증가할 때 키가 0.86cm 증가한다는 걸 알 수 있습니다
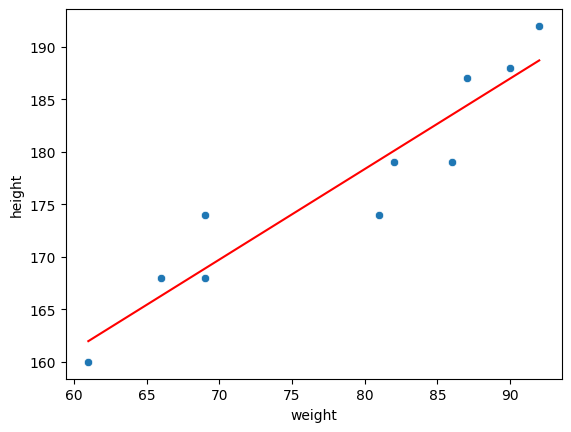
sns.scatterplot(data = body_df, x = 'weight', y = 'height')
sns.lineplot(data = body_df, x = 'weight', y = 'pred', color = 'red')위처럼 시본의 라인플랏을 데려오면
손쉽게 선형이 포함된 선형회귀 그래프를 그릴 수 있습니다 !!
그치만 여기서 끝이 아닙니다
저희는 이 선형회귀 그래프가 모델이 적합한지
평가해줘야합니다 😇
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
# 평가함수는 공통적으로 정답(실제 true), 예측값(pred)
y_true = body_df['height']
y_pred = body_df['pred']
mean_squared_error(y_true, y_pred)
r2_score(y_true, y_pred)
>> 결과 : 0.8899887415172141
y_pred2 = model_lr.predict(body_df[['weight']])
y_pred2
mean_squared_error(y_true,y_pred2)
>> 결과 : 10.152939045376318
MSE 값 : 10.15..
R Square 값 : 0.88.. (0이면 제일 낮음, 1일수록 높음)
일반적으로 MSE가 낮고,
R Square가 높을수록 모델의 성능이 좋다고
평가됩니다 !
위에선 단순 선형회귀로 연습해보았는데요
이번엔 다중 선형회귀로 진행해볼게요 !!
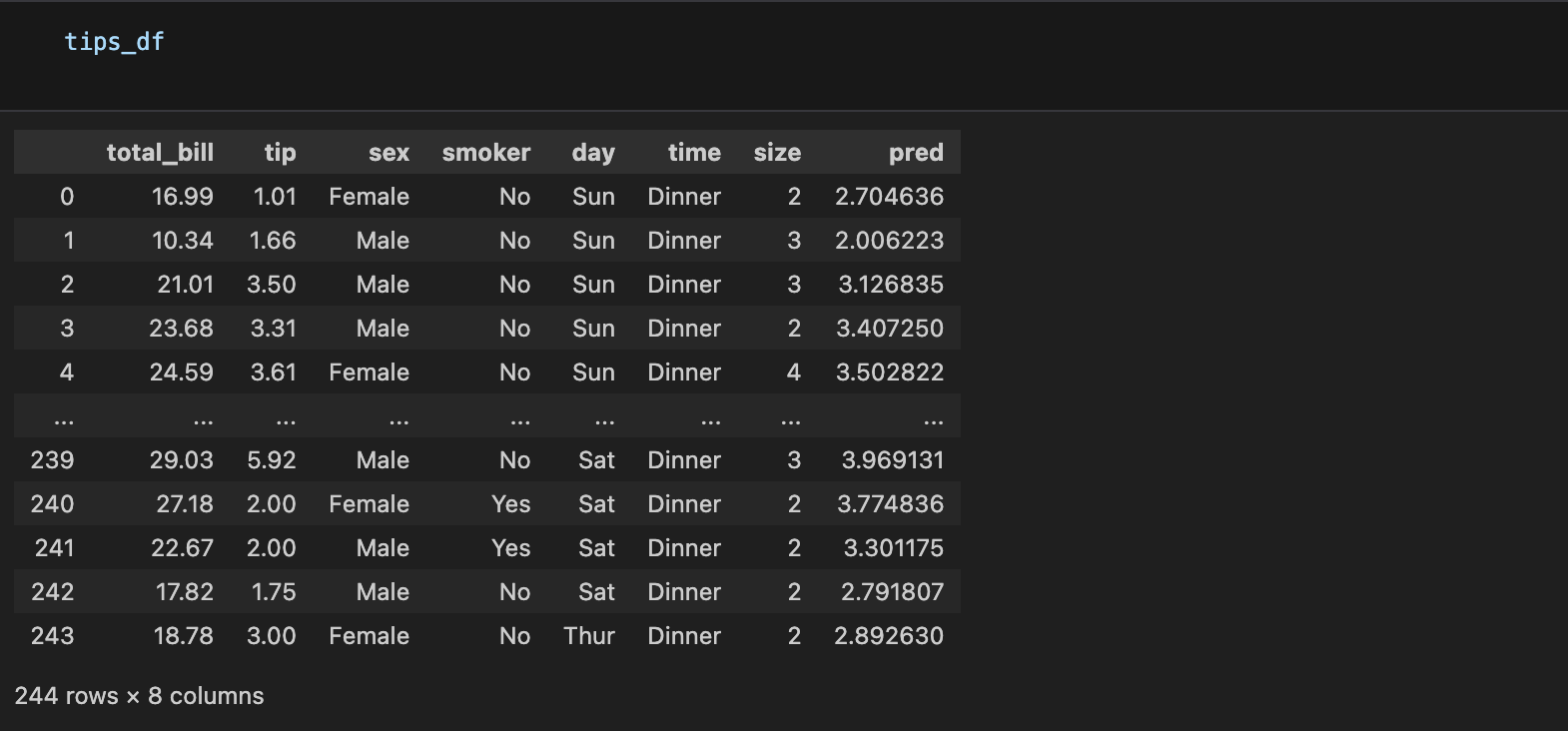
시본 라이브러리에 있는 tips 데이터를 사용해줬습니다
# 범주형 데이터 전환 / Female 0, Male 1
def get_sex(x):
if x == 'Female':
return 0
else:
return 1
tips_df['sex_ec'] = tips_df['sex'].apply(get_sex)
# 모델설계도 가져오기
modellr3 = LinearRegression()
X = tips_df[['total_bill','sex_ec']]
Y = tips_df[['tip']]
# 학습 확인
modellr3.fit(X,Y)
# 예측 확인
y_pred3 = modellr3.predict(X)
print('다중선형회귀', mean_squared_error(y_true_tip, y_pred3))
print('다중선형회귀', r2_score(y_true_tip, y_pred3))
결과 >>
다중선형회귀 MSE 값 : 1.0358604137213616
다중선형회귀 R-Square 값 : 0.45669999534149963위는 팁에 관한 데이터로
주문 금액과 팁에 대한 상관관계에 이어서
주문금액 + 성별에 따라 남성일 경우에 팁을 많이 줄 것이다
라는 가설을 세워봤는데요
R-Square 값을 보니 낮은 수치에 불과하는 편이라
주문금액과 성별에 따른 팁을 주는 금액이 커진다는 가설은 기각되네요 !!
♾️ 로지스틱회귀 실습
다중 로지스틱회귀의 경우는
titanic 데이터를 사용해줬습니다 !!
## 성별 전처리
def get_sex(x):
if x == 'female':
return 0
else:
return 1
titaninc_df['Sex_en'] = titaninc_df['Sex'].apply(get_sex)
## 독립변수, 종속변수 정하기 / 데이터 학습
x_2 = titaninc_df[['Pclass', 'Sex_en', 'Fare']]
y_true = titaninc_df[['Survived']]
model_logic2 = LogisticRegression()
model_logic2.fit(x_2, y_true)
## 모델 확인
get_att(model_logic2)
>> 결과 :
클래스 종류 [0 1]
독립변수 개수 3
들어간 독립변수 이름 ['Pclass' 'Sex_en' 'Fare']
가중치 [[-8.88331324e-01 -2.53993425e+00 1.64019087e-03]]
바이어스 [3.02004403]
y_pred33 = model_logic2.predict(x_2)
y_pred33[:10]
## 예측값 확인
get_metrics(y_true, y_pred33)
결과 :
정확도 0.7867564534231201
f1_score 0.7121212121212122정확도 : 모델이 전체 데이터의 약 78.7%를 정확하게 예측
F1 스코어 : 약 71.2%로 모델이 정밀도와 재현율 간의 균형이 잘 맞음
실제로 통계학 강의하면서
너무 이론이 방대해서 이해하기 정말 어려웠는데요 ,,
다행히도 머신러닝 실습 코드를 따라해보니까
어찌저찌 코드도 잘 출력되고
순서가 이해가 되고 있어서 다행이에요 😇😇😇
그리고 다들 정말 컨디션 관리 잘하세요 ,,,
주말엔 정말 푹 쉬시구요 ,,
저도 주말엔 잘 쉬고 다음주부턴 프로젝트 주차라 두렵지만 .. 🥵
다들 오늘도 고생 많으셨어요 🍀🍀🍀🍀
