2024-06-17

안녕하세요 ~!
또또 돌아온 월요일이네요
이번주부터 다시.. 또 시작된 프로젝트 주차라서
두렵내요 ,,.
아무튼,,
인생은 짧고..
열심히 해라,,.
♾️ 군집 분석
머신러닝에는 크게 3가지로 나뉘는데요 !
분류(Classification) - 데이터를 사전 정의된 카테고리나 클래스에 할당하는 작업
회귀(Regression) - 연속적인 값을 예측하는 작업
군집(Clustering) - 유사한 특성을 가진 데이터 포인트들을 그룹화하는 작업
이 중에서 저와 팀원들은
군집에 해당하는 Spotify 프로젝트 - 음원 클러스터링 주제를 골랐습니다 !
죽지도 않고 돌아온 스포티파이
이렇게 된 김에 군집 분석에 대해 알려드릴게요 ^~^
클러스터링이란?
데이터분석에서 피쳐( =컬럼) 유사성의 개념을 기반으로 전체데이터셋을
그룹으로 나누는 그룹핑 기법입니다
(각 그룹을 클러스터라고 칭함 )
이러한 데이터 속에서 데이터분석가는 의미있는 특징(컬럼)을 찾고, 최적의 그룹 갯수를 찾아 그룹별 인사이트를 도출해내는 역할을 수행하게 됩니다.
방대한 데이터 속,
데이터분석가는 의미있는 클러스터를 찾고, 최적의 그룹 갯수를 찾아 그룹별 인사이트를 도출해내는 역할을 수행하게 됩니다 !
📌 군집분석 프로세스
1️⃣ 기간 선정 : 클러스터링을 위한 데이터 기간을 설정합니다.
의미있는 패턴을 도출하기 위해서는 최소 3개월 이상의 데이터셋이 권장
2️⃣ 이상치 기준선정 및 제외 :
Z-Score
IQR(Interquartile Range)
Isolation Forest
DBScan 사용
3️⃣ 표준화 : 데이터의 크기가 너무 크거나, 컬럼 간 데이터 range 에 차이가 많을 때 일부 컬럼에 대해 진행합니다.
표준화는 대표적으로 minmax scale, standard scale 사용
4️⃣ 차원 축소(PCA) : 많은 컬럼으로 구성된 다차원 데이터 세트의 차원을 축소해
새로운 차원의 데이터 세트를 생성하는 것
(PCA 기법의 핵심은 가장 높은 분산을 가지는 데이터의 축을 찾아 그 축으로 차원을 축소하는 것인데, 이 축을 주성분이라 함)
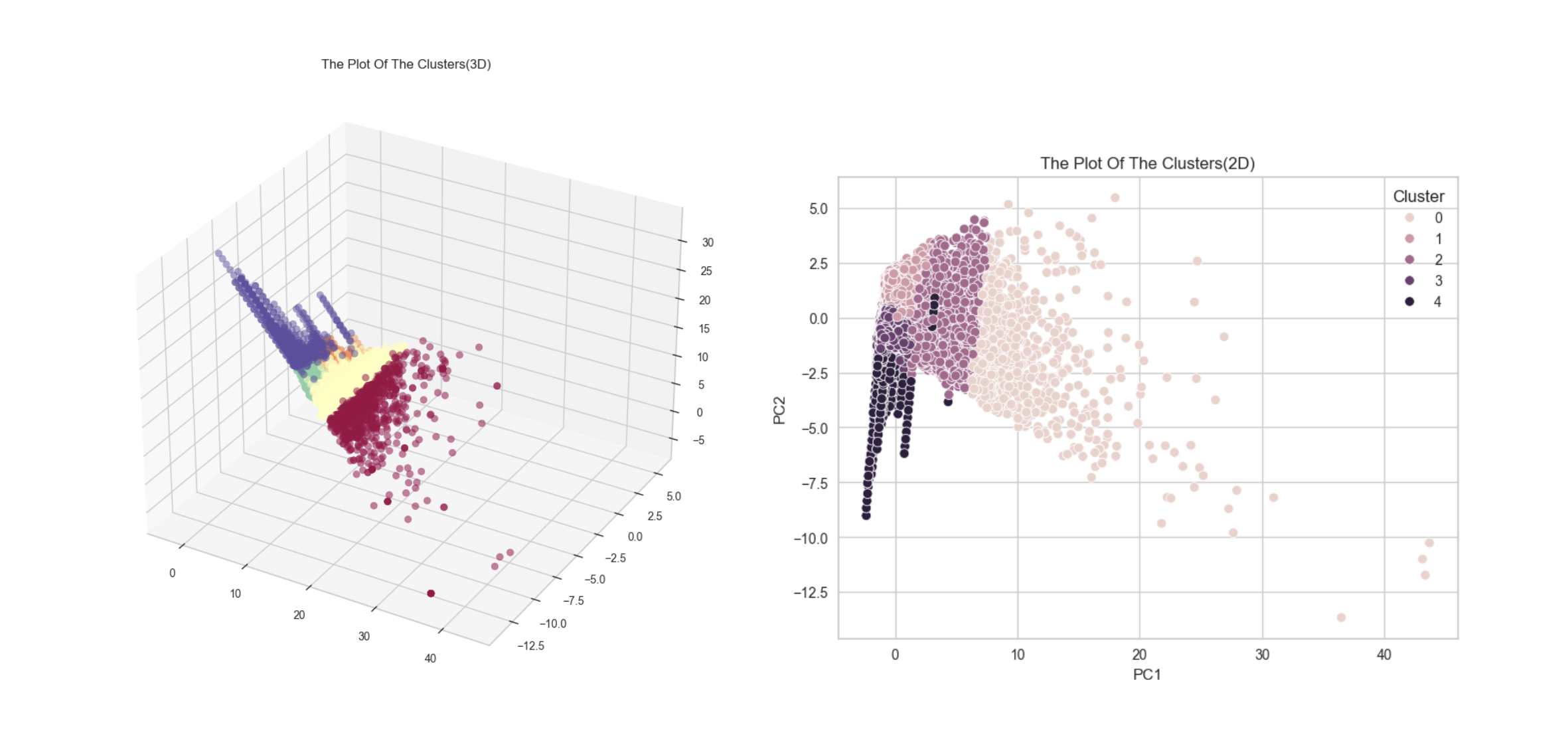
5️⃣ K값(군집갯수), 초기 컬럼(피쳐) 선정 :
Silhouette Coefficient,
elbow-point,
Distance Map 을 통해 초기 군집의 갯수를 지정합니다
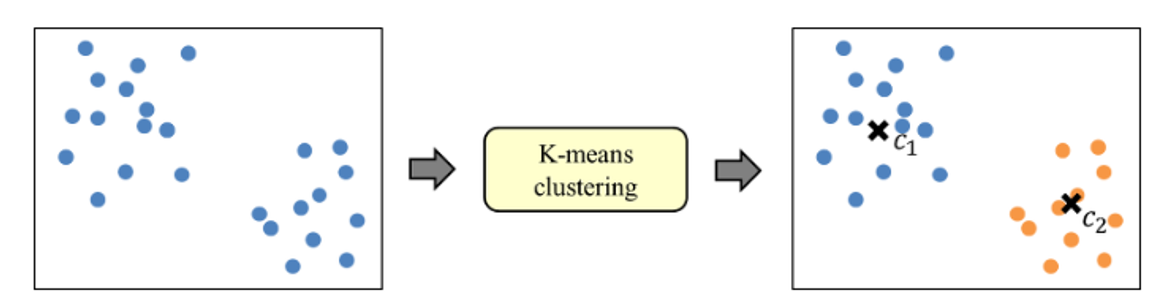
6️⃣ k-means clustering 시행 :
데이터를 거리기반 K개의 군집(클러스터)으로 묶는(클러스터링) 알고리즘
여기서 ~!!
k-means 이름이 왜 그럴까 ?!!?
K : 데이터를 k개의 클러스터로 나눈다.
여기서 k는 사용자가 미리 설정하는 클러스터의 수입니다.
= 마치라잌 우리가 9n년생이에요 이러는 바이브
물론 저는 0n년생임 ㅋㅋ
means : 각 클러스터의 중심을 해당 클러스터에 속한 데이터 포인트들의 평균값(mean)으로 계산하기 때문에 평균을 뜻하는 단어 사용
따라서, k-means는 "k개의 클러스터의 중심을 평균값을 통해 구한다"는 의미를 담고 있습니다 !!
7️⃣ 군집 분포 확인 : 데이터셋을 기반으로 데이터가 잘 나뉘었는지 확인하는 과정을 거치게 됩니다`
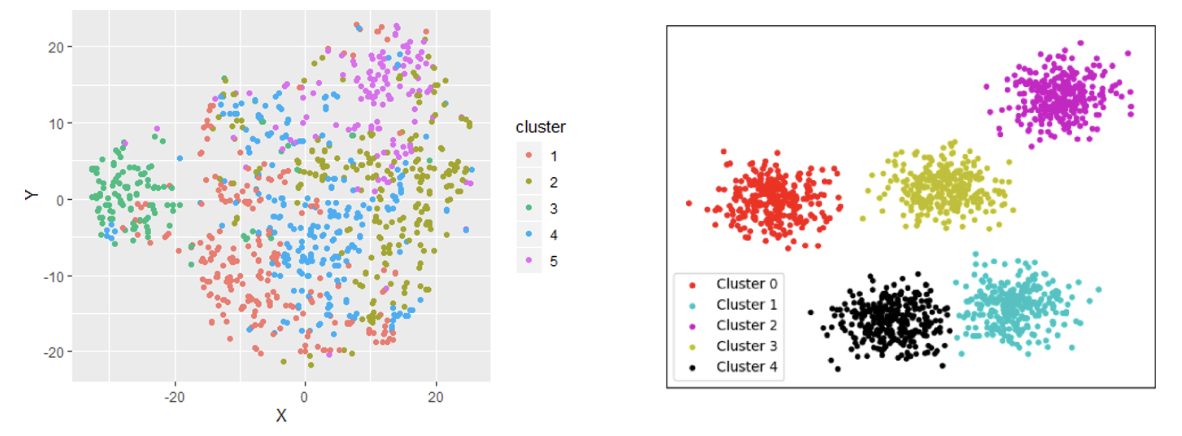
왼쪽에 보이는 scatter plot은 군집이 잘 나뉘어지지 않음
우리는 K값과 컬럼을 조정해, 오른쪽 scatter plot처럼
군집별 특성이 명확하고, 각각의 data point가 충돌하지 않도록 실험을 반복
8️⃣ 2~7번 과정을 반복하며 최적의 결과 도출
9️⃣ 모델링 : 클러스터링 결과를 가지고 이를 모델에 학습시켜줍니다.
모델은 우리가 실험한 로직을 매번 수행하지 않도록 해주는 중요한 부분 !!
🔟 데이터 적재 및 자동화 설정 : 클러스터별 나눈 데이터는 별도의 테이블로 저장하여 자동 테이블에 적재하는 것까지가 클러스터링의 최종작업
🔥(마지막) 인사이트 도출
이렇게 군집분석에 대한 이론을 다뤄보았는데요 !
내일은 스포티파이 데이터를 통해 군집분석 전처리 코드로
돌아오겠습니다
오늘도 고생 많으셨습니다 🍀🍀🍀🍀
