2024-06-18

안녕하세요 ,,
지친 화요일입니다
그냥 바로 쓸게용 ~!
♾️ 스포티파이 데이터 클러스터링
사용한 데이터 셋 :
https://www.kaggle.com/datasets/vatsalmavani/spotify-dataset
# 데이터 로드
dod = pd.read_csv('/Desktop/머신러닝/data.csv')
# 필요한 컬럼 선택
columns_to_use = ['valence', 'acousticness', 'danceability', 'energy', 'explicit', 'instrumentalness', 'key', 'loudness', 'speechiness', 'tempo']
data_selected = dod[columns_to_use]우선 24개의 컬럼 중 범주형 데이터를 제외하고
감 잡자고 대충 만져본 거라 컬럼을 반을 날리고
(물론 저의 주관이 상당히 들어감)
(duration_ms (재생 시간) 약간 이런 거 날림)
쓸만한 컬럼만 골라서 초기 컬럼 선정해줬습니다 !
# 데이터 표준화
scaler = StandardScaler()
X = scaler.fit_transform(data_selected)
# PCA를 통해 2차원으로 축소 (시각화를 위해)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# DBSCAN 모델 적용
dbscan = DBSCAN(eps=0.5, min_samples=5)
y_dbscan = dbscan.fit_predict(X_pca)
# 이상치 탐지 및 제거
dod['DBSCAN_cluster'] = y_dbscan
outliers = dod[y_dbscan == -1]
non_outliers = dod[y_dbscan != -1]
# 2D 시각화
plt.figure(figsize=(10, 8))
plt.scatter(X_pca[non_outliers.index, 0], X_pca[non_outliers.index, 1], c=y_dbscan[non_outliers.index], cmap='viridis', marker='o', label='Clustered Points')
plt.scatter(X_pca[outliers.index, 0], X_pca[outliers.index, 1], c='red', marker='x', label='Outliers')
plt.title('DBSCAN Clustering with PCA')
plt.xlabel('PCA Feature 1')
plt.ylabel('PCA Feature 2')
plt.legend()
plt.show()이렇게 DBScan PCA까지 써봤는데요 ,,,
어 사실 이 그림이 맞는진 모르겠어요
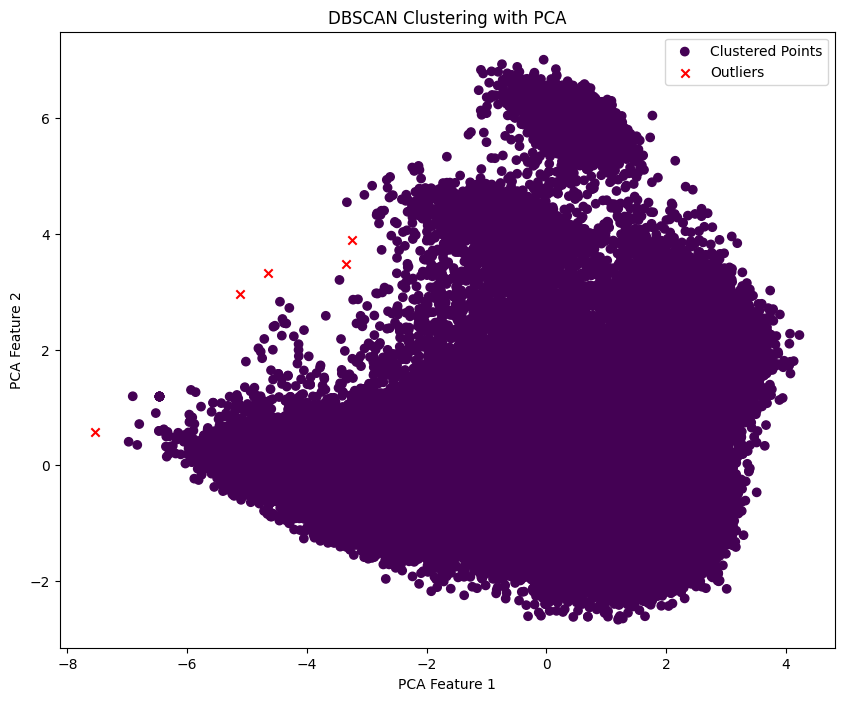
아무튼.,..
이렇게 빨간 x표시가 난 이상치들을 제거해주고
from sklearn.metrics import silhouette_score
def get_silhouette_score(clusters):
score = silhouette_score(data_selected, clusters)
return score
# 예시 데이터 (clusters 변수는 적절히 정의되어야 함)
clusters = y_dbscan
# 함수 호출 및 결과 출력
silhouette = get_silhouette_score(clusters)
print("Silhouette Score:", silhouette)
출력 >> Silhouette Score: 0.3670079091167944실루엣 계수가 못해도 0.5는 넘어야.. 그래도 설명력이 있다고 생각되는데
마치 나를 비웃듯 ,,, 0.36 ,,, 🥲
사실 저는 군집도 어렵고.. 머신러닝 자체가 걍 어렵습니다,,,
🥲🥲🥲
꺾여도 하는 마음 ,,, 중요하게 생각해서 죽이되든 밥이되든 하고 있습니다
더디지만 하는 게 어딥니까 ,,
다들 오늘도 잘 버텼습니다 !!!
내일도 열심히 해볼게요 🍀🍀🍀

걍 달려