Reference
⚙️ HTTP란?
🔸 정의
HTTP는 TCP/IP에서 Application Layer 프로토콜 중 하나로, 클라이언트-서버 간 주고받는 요청/응답에 대한 프로토콜입니다. HTTP는 클라이언트와 서버의 역할을 명확하게 구별하고 있습니다. HTTP를 사용하여 두 컴퓨터가 통신할 때, 반드시 어느 한 쪽은 클라이언트, 반대쪽은 서버가 되며 경우에 따라 역할이 서로 바뀔 수 있습니다
🔸 요청/응답 방식으로 동작
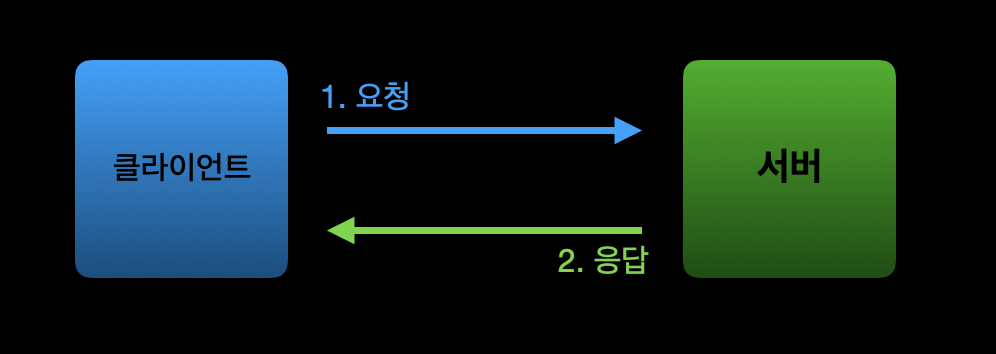
HTTP는 클라이언트가 요청(Request)을 서버에게 보내고, 서버가 응답(Response)을 클라이언트에게 보내는 방식으로 통신합니다. 그래서 반드시 클라이언트측의 요청으로부터 통신이 시작되며, 서버 측은 클라이언트의 Request 없이는 Response 하지 않습니다.
🔸 HTTP는 Stateless 프로토콜
HTTP는 이전에 보냈던 요청/응답에 대해서 전혀 기억하지 않습니다. 과거의 문맥을 고려하지 않으므로, 클라이언트가 요청을 보낼 때마다 새로운 응답이 생성되는 구조입니다
하지만, 로그인처럼 과거를 기억하는게 반드시 필요한 경우가 있는데 이 때는 "쿠키" 기술을 사용하여 관리합니다
🔸 요청 URI(URL)로 리소스를 식별
HTTP는 인터넷 상의 리소스를 지정하여 호출할 수 있습니다
클라이언트 요청에 URL을 명시하는 방법에는 여러 종류가 있습니다
//모든 URL을 한 줄에
GET http://naver.com/index.html HTTP/1.1
//일부는 Host 헤더 필드에
GET /index.html HTTP/1.1
Host: http://naver.com
//특정 리소스가 아닌 서버 자체를 지정 : "*"
OPTIONS * HTTP/1.1🔸 HTTP 메서드를 통해 서버에게 명령
클라이언트 요청 URL로 지정한 리소스에 대해, 어떠한 행동을 하길 원하는지 메서드를 명시할 수 있습니다
대표적인 예시는 아래와 같으며 메서드는 별도의 섹션에서 다룹니다
▪️ GET : 리소스 취득
▪️ POST : 엔티티 바디 전송
▪️ DELETE : 파일 삭제
🔸 지속연결
HTTP 초기에는 한 번 통신할 때마다 TCP 연결/종료를 해주어야 했습니다. 이런 불필요한 연결종료 문제를 해결하기 위해 HTTP/1.1과 일부 HTTP/1.0에서 지속연결이라는 방식이 고안되었습니다. 이는 한 번 연결되면 어느 한 쪽이 명시적으로 연결을 종료하지 않는 이상 TCP 연결을 유지하는 방식입니다
이런 지속연결 방식으로 인해 가능해진 것이 HTTP 파이프라이닝입니다. 원래는 요청A를 보내면 응답A가 올 때까지 다음 요청B를 보낼 수 없었는데, 지속연결 방식을 사용하면 응답을 당장 기다리지 않고 여러 요청을 병행해서 보낼 수 있습니다
🔸 쿠키
HTTP는 stateless 프로토콜이므로 과거의 이력을 기억해야 하는 로그인/인증 등의 기능을 유지할 수 없었습니다. 이런 문제를 해결하기 위해 쿠키라는 시스템이 도입되었습니다
서버 응답의 Set-Cookie 헤더 필드에 적힌 내용은 클라이언트의 쿠키에 저장/보존됩니다. 저장된 쿠키는 다음 클라이언트 요청에 자동으로 포함되어 서버가 어느 클라이언트가 요청한 것인지를 식별할 수 있습니다
⚙️ HTTP 메시지
🔸 메시지란?
HTTP 메시지는 HTTP 통신의 기본 단위로 요청 메시지와 응답 메시지가 있습니다. ASCII로 인코딩된 텍스트 정보이며 여러 줄로 구성되어 있습니다
🔸 메시지 구조
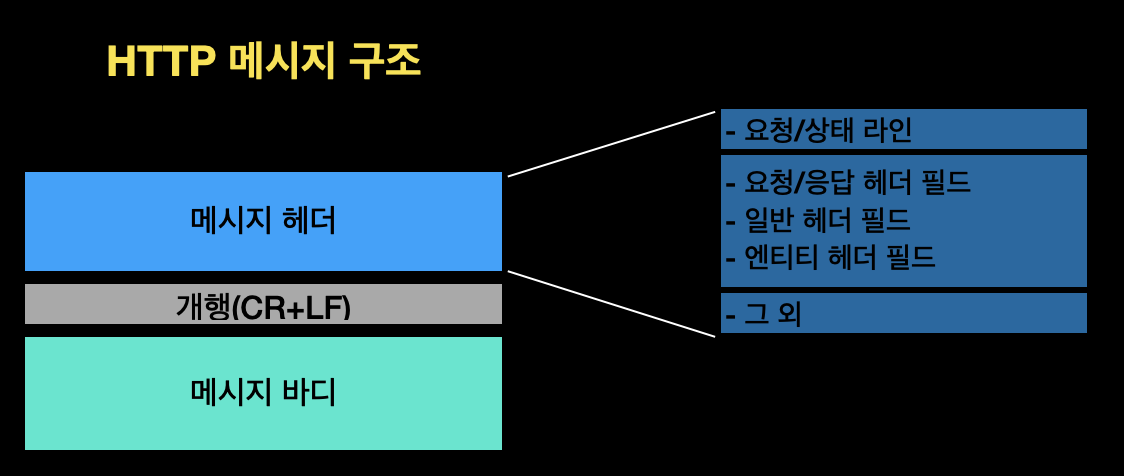
▪️ 요청 라인 : 요청에 사용하는 메서드 / URL / HTTP버전
▪️ 상태 라인 : 응답 결과를 나타내는 status code / 설명 / HTTP버전
▪️ 헤더 : Request 조건, 속성 등을 나타내는 각종 헤더 필드
▪️ 그 외 : RFC에 없는 헤더 필드(쿠키 등)가 포함되는 경우
🔸 데이터 인코딩
HTTP로 데이터를 전송할 경우 그대로 전송할 수도 있지만 인코딩하여 전송효율을 높일 수 있습니다. 보내는 쪽은 인코딩을, 받는 쪽은 디코딩 작업이 추가로 필요하게 됩니다
▪️ 압축 : 컨텐츠 코딩
엔티티 정보를 유지한 채 용량을 줄이기 위해 gzip/compress/deflate/identity 등으로 압축합니다
▪️ 분해 : 청크 전송 코딩
엔티티 바디를 청크 단위로 분해하는 것을 말합니다. 수신측은 데이터를 분할해서 조금씩 표시할 수 있게 됩니다
🔸 멀티파트 (여러 데이터 보내기)
멀티파트는 MIME의 content-type 중 하나로, 여러 다른 종류의 데이터를 하나의 메일에 수용하는 방식을 말합니다
HTTP도 MIME의 멀티파트 표준에 대응하고 있어, 하나의 메시지 바디에 여러 다른 종류의 엔티티를 포함시킬 수 있습니다
▪️ 멀티파트 메시지 바디 구성방법
1. Content-Type 헤더 필드를 사용하여 multipart 명시
2. 헤더에 boundary 값 명시
3. 각 content 시작/끝 부분에 "--{boundary}" 명시
4. 각 content마다 헤더 필드 명시
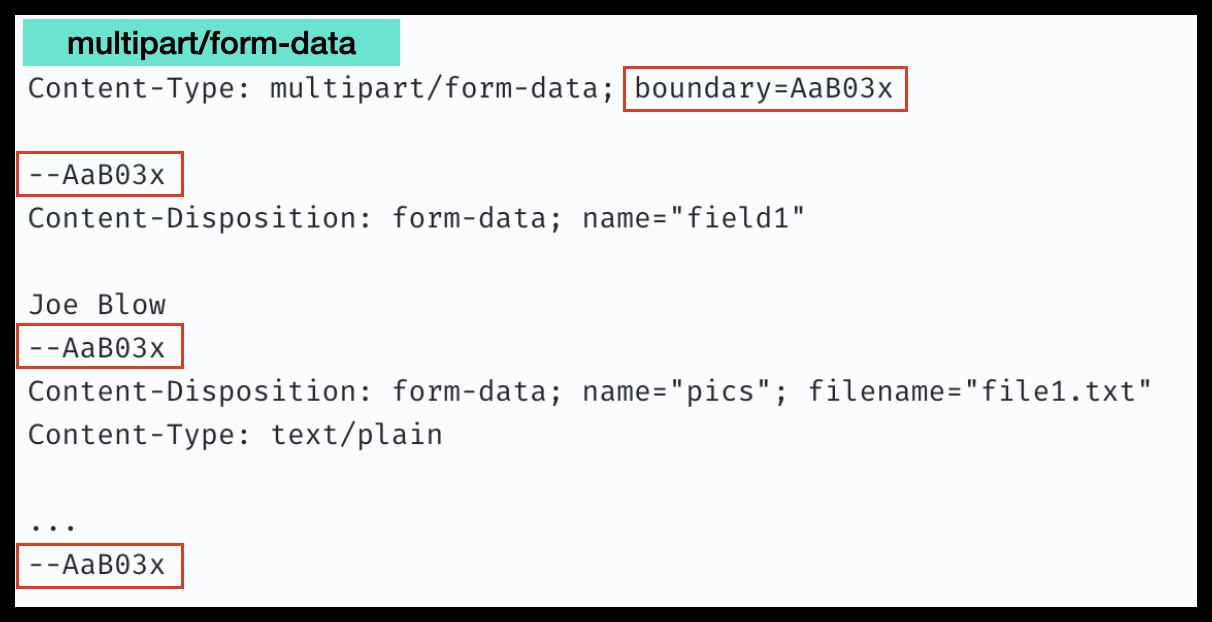
참고로, form-data는 Web의 form으로부터 파일 업로드를 할 때 사용됩니다
🔸 레인지 리퀘스트 (데이터 일부만 다운로드)
다운로드 중 연결이 끊길 경우 처음부터 다시 다운로드해야 한다는 문제를 해결하기 위해, 엔티티의 범위를 지정하여 다운로드하는 기능을 말합니다
## 전체 10000bytes 중 뒷 5000bytes만을 요청한 예시
# 요청
GET /tip.jpg HTTP/1.1
Host: www.usagidesign.jp
Range: bytes = 5001-10000
# 응답
HTTP/1.1 206 Partial Content
Data: Fri, 13 Jul 2012 04:39:17 GMT
Content-Range: bytes 5001-10000/10000
Content-Length: 5000
Content-Type: image/jpeg🔸 컨텐츠 네고시에이션 (최적의 컨텐츠를 선택)
구글 페이지를 한국에서 접속하면 한글로 나오고, 미국에서 접속하면 영어로 나옵니다. 이처럼 동일한 URL에 여러 리소스가 존재하고, 요청한 클라이언트의 정보에 따라 최적의 리소스를 선택해주는 것을 컨텐츠 네고시에이션이라 합니다
▪️ 서버 구동형 네고시에이션
서버측에서 요청 메시지의 헤더 필드를 참고하여 자동으로 처리하는 방식
- Accept
- Accept-Charset
- Accept-Encoding
- Accept-Language
- Content-Language
▪️ 에이전트 구동형 네고시에이션
클라이언트가 브라우저에서 직접 선택하는 방식
▪️ 트랜스페어런트 네고시에이션
서버 구동형과 에이전트 구동형을 혼합한 방식
⚙️ Data type
HTTP에서 클라이언트와 서버가 교환하는 Data에는 아래와 같은 형태가 있습니다
▪️ URL Parameters
Request에만 사용가능한 형태로, 실제 URL 뒤에 extra data를 붙이는 것을 말합니다. 예로, naver.com/api?data=value와 같이 보내면 naver.com/api라는 실제 URL에 value라는 data를 보내게 되는 것입니다. 이런 파라미터 양식은 서버와 미리 협의된 형태로 보내야 합니다
▪️ Form Data
웹에서 form으로 보내는 data
▪️ JSON / XML
말 그대로 JSON / XML 파일
▪️ Files
말 그대로 일반적인 파일
⚙️ Status Codes
클라이언트가 서버로 요청을 보낼 때 서버에서 그 결과가 어떻게 되었는지를 알려주는 것이 status code입니다. 클라이언트는 서버로부터 받은 응답 메시지에 명시된 status code로부터 자신의 요청이 정상적으로 처리되었는지, 에러가 발생했는지 알 수 있습니다
status code는 3자리 숫자와 설명으로 나타냅니다 (ex. 200 OK)
status code의 첫 번째 자리는 아래와 같은 정보를 나타냅니다. 나머지 2자리는 분류가 없습니다
▪️ 1xx : Information : 요청을 받아들여 처리 중
▪️ 2xx : Success : 요청이 정상적으로 처리됨
▪️ 3xx : Redirect : 요청을 완료하기 위해 추가 동작이 필요함
▪️ 4xx : Client Error : 서버가 요청을 이해할 수 없음
▪️ 5xx : Server Error : 서버가 요청 처리에 실패함
⚙️ 기타
🔸 메시지 & 엔티티
메시지가 HTTP 통신의 컨테이너라면, 엔티티는 메시지의 실질적인 화물 개념입니다
🔸 URL & URI
▪️ URI (Uniform Resource Identifier)
URI는 어떤 리소스를 특정하기 위한 식별자를 말합니다.
무엇을 식별자로 삼느냐에 따라 URL과 URN으로 구분합니다. (URL과 URN은 URI의 subset입니다)
▪️ URL (Uniform Resource Location)
리소스를 특정하기 위한 식별자를 해당 리소스의 위치(Location)로 지정한 것을 URL라고 합니다
일반적으로 사용되는 HTTP URL의 구조는 아래와 같습니다

▪️ URN (Uniform Resource Name)
URN은 리소스를 이름으로 특정하는 방식을 말합니다. (아직 거의 사용되지 않고 있으므로 여기까지만..)
🔸 HTTP 버전
아직은 대부분이 HTTP/1.1을 쓰는 듯함
▪️ HTTP/0.9
--GET만 가능
--헤더없음
--HTML 외 전송불가
--상태/에러 코드 없음
▪️ HTTP/1.0
--POST/HEAD 추가
--헤더 추가
--HTML 외에도 전송가능 (Content-Type)
--상태 코드 추가
▪️ HTTP/1.1
--OPTIONS, PUT, DELETE, TRACE 추가
--첫 번째 표준이며, 현재까지도 널리 사용됨
--기존 버전의 모호함을 명확히 하고, 성능 개선
▪️ HTTP/2
--성능개선을 주목적으로 탄생
--구글의 SPDY를 주축으로 발전
--기존의 HTTP는 텍스트 기반이나, 2버전부터 바이너리 프로토콜
🔸 MIME
전자우편(메일)을 위한 인터넷 표준 포맷. 처음 개발될 때 이메일과 함께 동봉할 파일을 텍스트 문자로 전환(인코딩)해서 이메일 시스템을 통해 전달하기 위해 개발되었기 때문에 이름에 Internet Mail Extension 입니다. 그렇지만 현재는 웹을 통해서 여러형태의 파일 전달하는데 쓰이고 있습니다
MIME 표준에는 이미지 등의 바이너리 데이터를 ASCII 문자열에 인코딩하는 방법과 데이터 종류를 나타내는 방법 등을 규정하고 있습니다
🔸 RFC 문서
RFC(Request For Comments)란 미국의 국제 인터넷 표준화기구인 IETF(Internet Engineering Task Force)에서 제공,관리하는 문서로 인터넷 개발에 있어 필요한 기술, 연구결과, 절차 등을 기술해놓은 메모를 나타낸다
