안녕하세요. 오늘 리뷰할 논문은 OpenAI에서 2021년 발표한 Learning Transferable Visual Models From Natural Language Supervision 논문입니다. CLIP으로 더 많이 알려진 이 논문은, vision과 language 사이를 연결짓는 multimodal의 발전에 큰 기여를 했습니다.
논문이 다루는 Task
CLIP는 대규모 이미지-텍스트 페어 데이터를 통해 이미지와 텍스트 간의 관계를 학습하고, 이를 바탕으로 Zero-shot learning을 수행할 수 있는 시각 모델을 제안합니다.
기존 연구의 한계
기존의 컴퓨터 비전 시스템은 주로 ImageNet과 같은 고정된 클래스 레이블에 맞춰 학습되며, 추가적인 시각 개념을 학습하기 위해서는 추가 데이터가 필요합니다.
대규모 웹 데이터를 이용해 뛰어난 성능을 보인 LLM과 달리, Computer vision쪽에서는 아직도 Hand-labeled 된 데이터에 의존하다보니 성능 차이가 날 수 밖에 없습니다.
이러한 문제를 해결하기 위해 CLIP은 모델을 훈련할 때 사람이 레이블하지 않고, 인터넷에 캡션처럼 사진에 달려있는 텍스트를 레이블로 사용합니다. Natural Language Supervision을 사용하는 것입니다.
CLIP(Contrastive Language-Image Pretraining)
Contrastive Loss
CLIP의 약자에서 볼 수 있듯이, Contrastive Learning은 CLIP의 키포인트 중 하나입니다. Natural Language Supervision에서는 "귀여운 강아지", "하얀 강아지" "앉아있는 강아지" 등등 같은 사진이어도 다양한 레이블들이 존재하고, 모두 정답입니다. 그러므로 하나의 사진이 input으로 주어졌을 때 정확한 레이블을 예측하는 것은 불가능합니다.
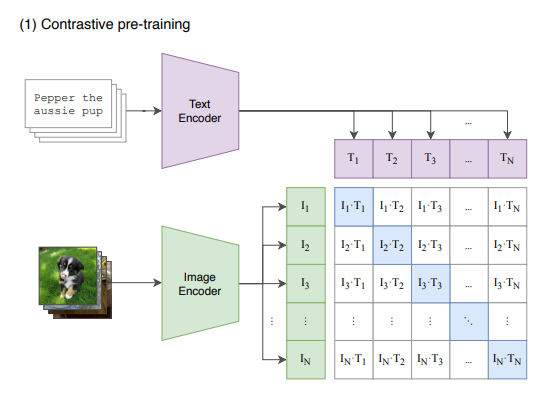
저자들이 접근한 방식은 텍스트의 정확한 단어를 예측하는 것이 아니라, 전체 텍스트가 어떤 이미지와 짝지어졌는지를 예측하는 것입니다. 즉, 텍스트의 특징과 비슷한 특징을 가진 이미지를 매칭하면 되는 task로 생각한 것입니다.
이를 위해서 맞게 매칭된 N개 쌍의 cosine similarity는 maximize, 그 외의 N^2-N개의 cosine similiarity는 minimize해야 합니다.

그러므로 similiarity score을 가지고 대칭적인 cross entropy를 적용하여 최적화합니다. 왜 대칭이어야 하나면, 이미지로부터 적합한 텍스트를 찾는 작업(loss_i)과 텍스트로부터 적합한 이미지를 찾는 작업(loss_t)을 동시에 최적화시켜야 하기 때문입니다. 그래서 이 두 개의 loss를 평균내면, 두가지 작업을 모두 고려하여 최적화할 수 있게 됩니다.
Model
이미지 encoder에는 VIT와 resnet50에 GAP 대신 attention pooling을 사용하였습니다. Resnet50에 변형을 가한 부분이 흥미롭습니다. GAP는 각 channel별 평균으로 spatial information이 모두 사라집니다. 이는 단순 분류에 효율적이지만, 레이블에 부가적인 설명이 들어가 있는 CLIP에서는 정보를 너무 없앤 것일 수 도 있습니다. (예를 들어 "해변을 뛰놀고 있는 강아지"와 같은 경우)
def forward(self, x):
x = x.flatten(start_dim=2).permute(2, 0, 1) # NCHW -> (HW)NC
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
x, _ = F.multi_head_attention_forward(
query=x[:1], key=x, value=x,
embed_dim_to_check=x.shape[-1],
num_heads=self.num_heads,
q_proj_weight=self.q_proj.weight,
k_proj_weight=self.k_proj.weight,
v_proj_weight=self.v_proj.weight,
in_proj_weight=None,
in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
bias_k=None,
bias_v=None,
add_zero_attn=False,
dropout_p=0,
out_proj_weight=self.c_proj.weight,
out_proj_bias=self.c_proj.bias,
use_separate_proj_weight=True,
training=self.training,
need_weights=False
)
return x.squeeze(0)그러므로 feature map들의 평균내어 모든 정보를 담은 global token 을 쿼리로, spatial 정보가 담긴 feature map을 키와 밸류로 설정하여 Multi Head Attention을 수행해 표현력을 높였습니다.
텍스트 encoder은 Transformer을 활용하여, 마지막 토큰에서 나온 정보를 linear projection하여 Image Feature과 차원을 맞춰주었습니다. (Non linear projection도 사용해봤으나, 큰 차이가 없었다고 합니다.)
zero-shot prediction
CLIP은 다른 vision 모델들과 달리 zero-shot prediction을 할 수 있다는 것이 큰 장점입니다.
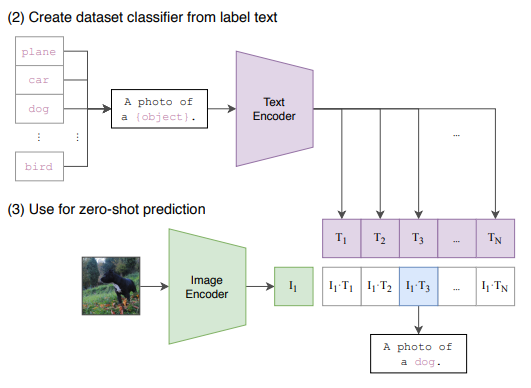
우선 학습할 때 사용된 데이터와 유사도를 높이기 위해 각 레이블에 prompt engineering을 진행하여, 그저 plane이라고만 하지 않고 A photo of plane과 같이 문장형으로 서술합니다. 서술된 레이블을 text encoder에 넣은 다음, 예측하고자 하는 이미지를 이미지 encoder에 넣어 예측을 진행합니다.
zero-shot transfer
어떻게 작동하는지 알아보았으니, 다양한 데이터셋에서도 성능이 괜찮은지 검증을 해봐야 합니다.
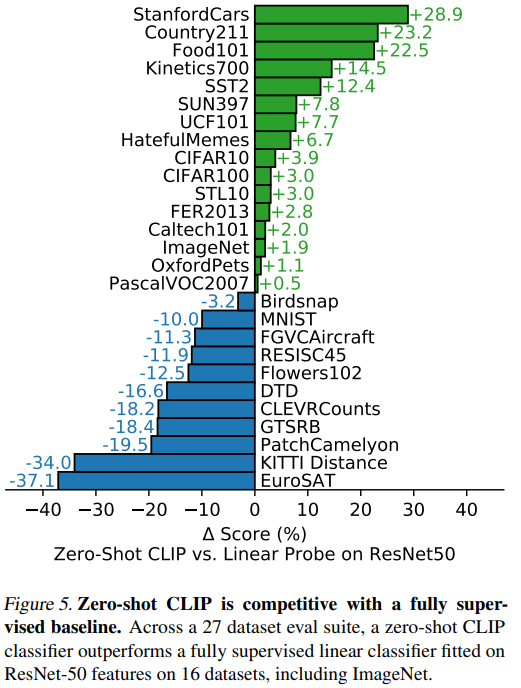
위 표는 zero-shot CLIP와 Linear Probe on Resnet50(Linear Probe는 linear classifier만 supervised learning 을 진행한 것을 말합니다.)을 비교한 결과입니다. 16개의 데이터셋에서 CLIP이 앞섰는데, 전혀 학습이 되지 않은 상태에서 이 결과는 놀랍습니다.
CLIP보다 resnet50이 앞선 부분은 대부분 전문적이거나 세부적인 판독을 요하는 데이터셋이었습니다. 이는 CLIP의 한계도 나타내는데, 다양한 범주의 웹 데이터로 학습된 만큼 대중적인 요소들은 잘 판별 가능하나 세부적이고 전문적이게 들어가면 성능이 하락한다는 것입니다.
 few-shot linear probe에서는 확실하게 성능이 앞서는 모습을 보입니다.
few-shot linear probe에서는 확실하게 성능이 앞서는 모습을 보입니다.
Represental Learning
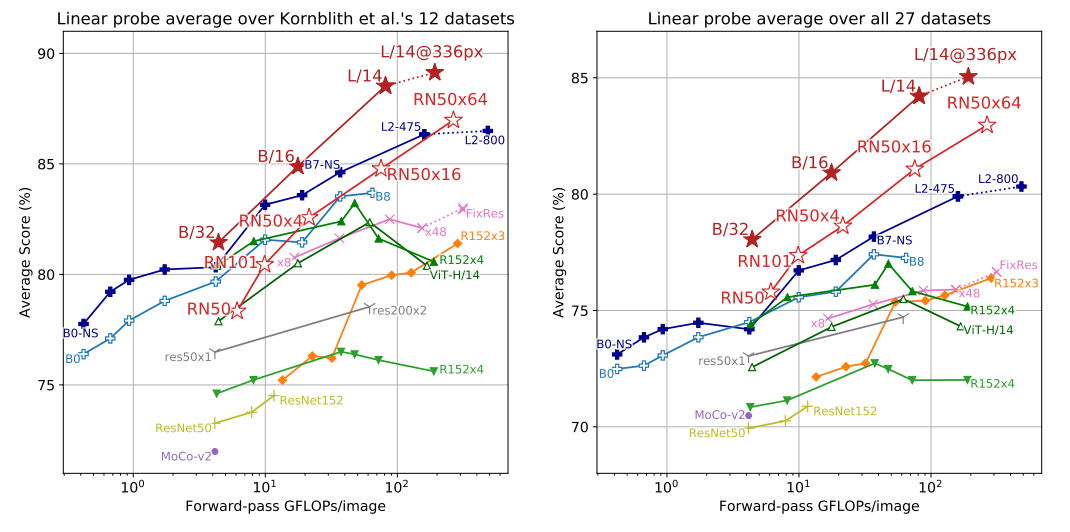
다만, 이렇게 zero-shot prediction은 CLIP에서만 존재하기 때문에 다른 CV 모델들과 명확한 비교가 안될 수도 있습니다. 정말 CLIP이 특징을 잘 추출하는지 확인하기 위해, CLIP에 linear prob를 추가해 동일한 조건으로 다른 모델들과 비교를 하였습니다. 위 표는 다양한 데이터셋에 대해, 다양한 모델들의 성능을 비교한 결과입니다. CLIP(ViT)와 CLIP(Resnet50)이 좋은 성능을 보이는 것을 확인할 수 있습니다.
Robustness
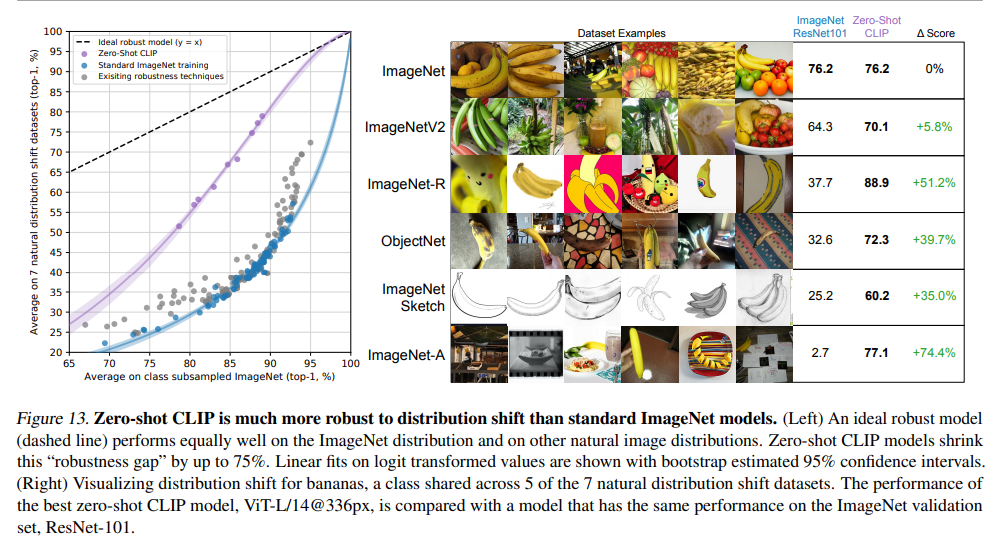
또한, ImageNet에 fully supervised training을 진행한 다른 모델들에 비해 robust한 것을 알 수 있습니다.
