유튜브 보다가 내용이 좋아 간략하게 정리해본다...(ft.멀티모달 스터디)
기존 RAG의 한계
아래 세가지 형태의 멀티모달에 대한 정보 추출이 어려움
- Tabel (이걸 해결하기 위해 쿼리를 SQL 문법으로 전환시키거나,표를 Knowledge graph나 json형태로 바꾸는 방법도 있음.)
- Chart + Text
- Image + Text (위 두가지는 멀티모달로 해결해야하는 것으로 알고있음.)
이전 시도들
그러나 우리가 보는 상당 부분의 문서는 위 세가지 형태로 되어있음.. 이것을 해결하기 위해 이전에도 시도가 있었음.
표
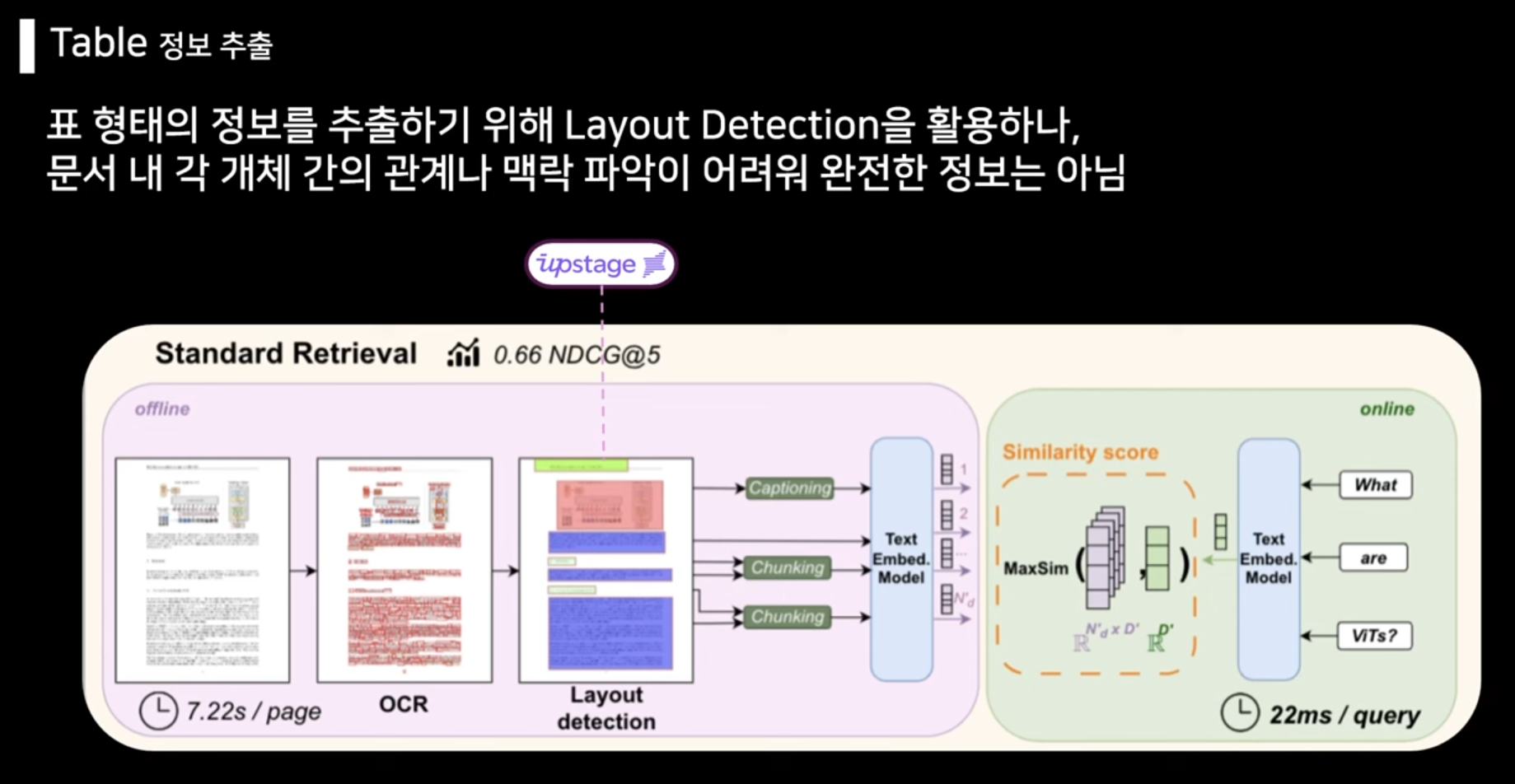
pdf -> OCR을 하여 text 추출 -> layout detection으로 어떤 레이아웃으로 구성되어 있는지 캡셔닝(설명) 하여 RAG의 임베딩 시스템에 넣으면, 사용자가 질문했을 때 좀 더 이 구조를 더 잘 이해한 답변을 생성할 수 있다.
그러나 어떤 구조인지에 대해서 힌트를 줄 뿐이지, 정확히 이 페이지를 보고 있는 것이 아니기 때문에 각 개체 간의 관계를 알기 어렵다. 그러므로 사람이 보는 것처럼 LLM이 이해하고 답변을 하는 것은 아니다.
보통 layout detection에서는 upstage껄 많이 사용함
이미지
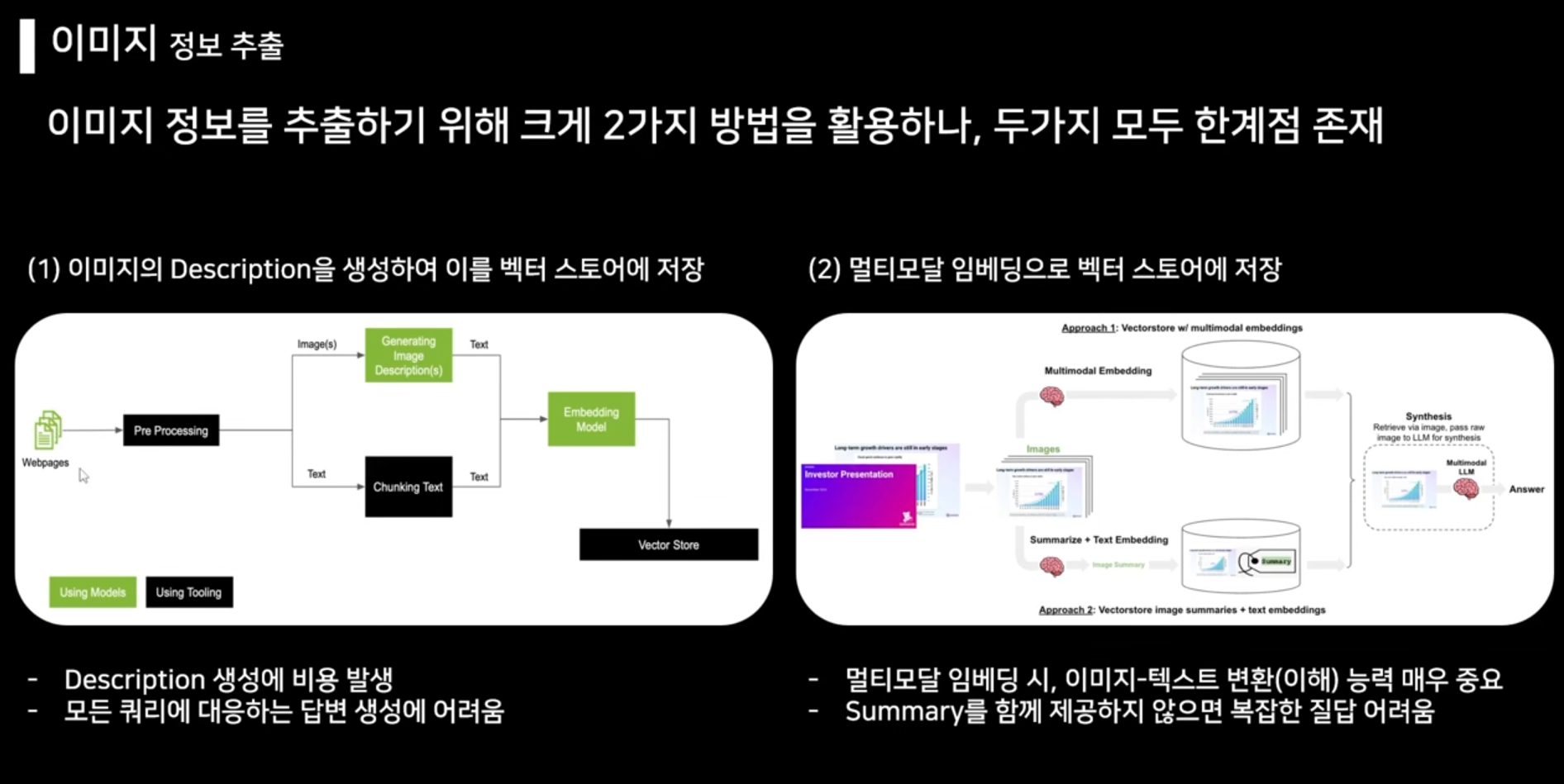
1번은 이미지 인식이 가능한 멀티모달을 활용하여 설명을 생성하는 방법인데, 기존에 이미지를 받아들일 수 없는 기존에 비해서는 더 많은 정보를 받아들이게 된다. 그러나 단점은 위 이미지에 쓰여져 있는 것과 같다. 양이 많을 수록 모델 호출비용이 많이 들고, 이미지에 대한 설명을 모두 맡기므로 조금 불완전하게 설명이 생성된다 하면은, 사용자가 얼마나 자세하게 물어봐도 설명은 모델이 생성한게 전부이니 한계가 있다.
2번은 이미지 그 자체를 저장한다. openclip이라는 텍스트와 이미지를 모두 이해할 수 있는 모델이 이미지를 임베딩한다. 완전히 이미지를 임베딩으로 한번에 바꾸니 이미지를 정말로 텍스트로 이해할 수 있는 능력이 중요하므로, openclip의 성능에 굉장히 의존하게 된다. 또한 openclip만으로 임베딩하게 되면, 이미지의 세부정보를 가져오지 못함(파이프라인보다는 모델 자체의 문제). 그러므로 표와 같은 복잡한 구조를 갖고 있는, 텍스트와 이미지를 혼합한 이미지는 제대로 이해하지 못한다. Openclip이 나온지 조금 된 모델이어서도 그렇다.
ColPali
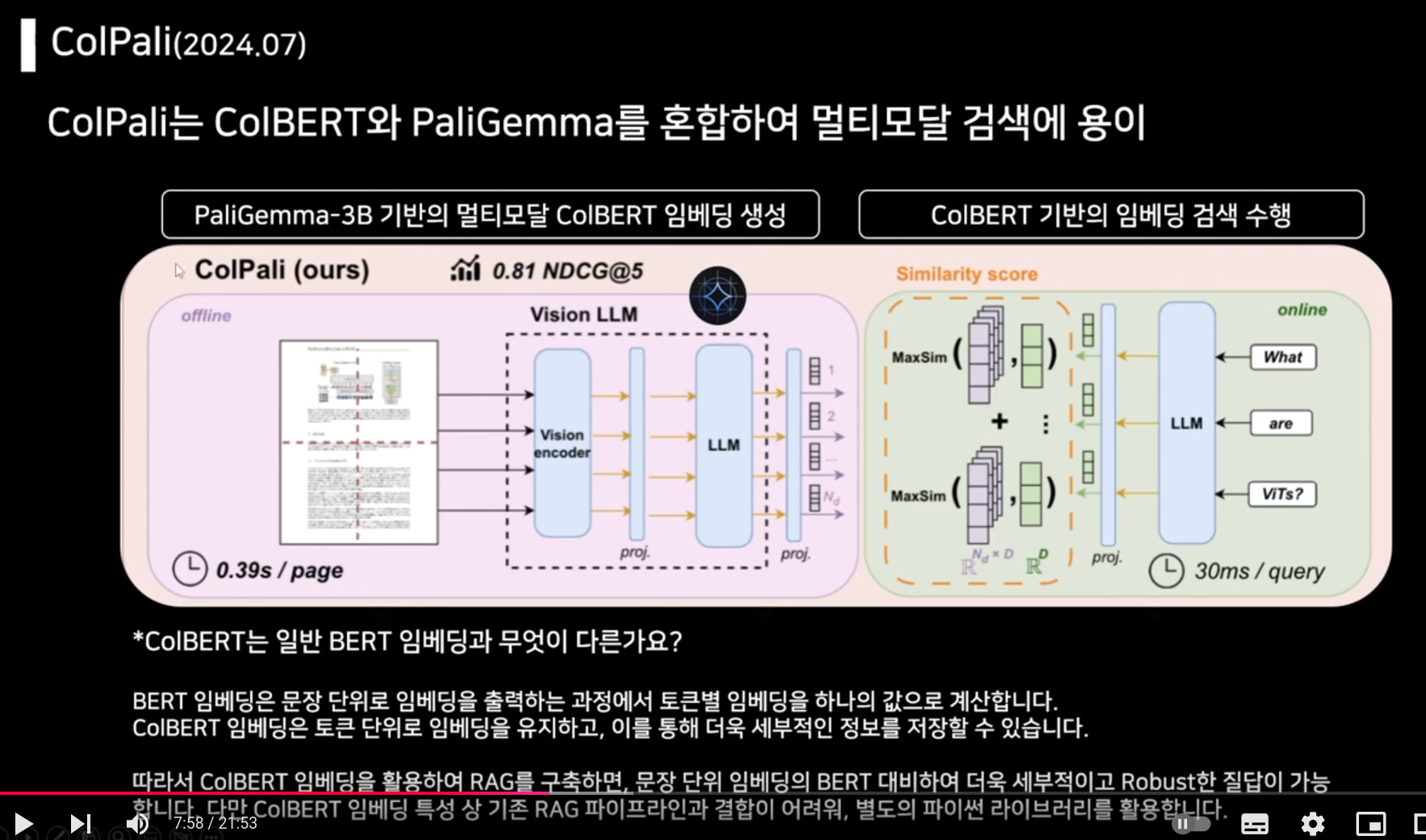
ColBERT: BERT처럼 임베딩 모델이지만, 검색에 이점을 두었다. 기존 BERT모델은 문장 단위 임베딩으로, 각각 문장을 하나의 임베딩 벡터로 만들었다. 우선 토큰 별로 임베딩 후 문장 단위로 통합하여(평균 내기) 정보의 손실이 있다. 그러나 ColBERT는 토큰 단위로 임베딩을 유지하고, 토큰을 각각 비교하는 형태이다. ColBERT은 질문이 들어오면 문장 단위가 아니라 토큰 단위로 임베딩하고, 벡터 저장소에서 토큰 별로 임베딩된 값을 쿼리 토큰 값과의 매칭되어 가장 높은 유사도를 가진 문장을 가져온다.
(추후 더 자세히 포스팅하겠다! 신기방기)
PaliGemma: 구글에서 출시한 vllm으로, 이미지를 텍스트로 이해한 결과로 내뱉는다. 여기서 이해해야 하는게,이미지 자체를 임베딩하게 되는데 그 과정에서 이미 임베딩 모델이 학습 당시 획득한 표/이미지, 텍스트 인식 능력을 바탕으로 임베딩을 하게 된다.PaliGemma 이미지를 인풋값으로 받고, vision llm으로 이미지를 텍스트로 이해한 결과를 임베딩으로 내놓게 된다. vision 인코더가 이미지를 이해한 결과를 프로젝션을 통해 llm으로 주고, llm은 이미지 인식 결과를 텍스트로 변환하여 임베딩으로 저장하게 된다.
이미지 각각을 summary로 생성하는게 아니라, vision llm 작동 방식 자체가 이미지가 들어오면 llm을 통해 텍스트로 변환가능한 형태로 생성하는 것이다.
정리하자면 우선 PaliGemma를 이용하여 pdf로 이미지를 이해하고, 벡터 저장소에 넣고, 질문이 들어오면 ColBERT를 이용하여 토큰별로 유사도를 구한다.
