대규모 언어 모델은 잠재적으로 단계 추론을 할까?
예를 들어, The mother of the singer 'Superstition' is 를 답변하기 위해서는 두 차례의 추론이 필요하다. 첫번째는 'Supersition' 을 부른 사람을 알아내는 것이고, 두번째는 그 가수의 엄마를 알아낸 후에야 답변할 수 있다. 그렇다면 LLM은 이 과정을 내재적으로 거칠까?
만약 추론이 가능하다고 하면, LLM은 단순히 정보를 가중치에 저장하는 것이 아니라 가중치에 저장된 암묵적인 정보들을 탐색할 수 있음을 시사한다.
만약 불가능하다고 하면, 이는 어텐션 메커니즘의 한계를 나타내며, 모델을 더 잘 동작하기 위해서는 단순히 기본 사실만을 학습하는 것으로 충분하지 않다고 결론 지을 수 있다.
첫번째 hop, 즉 superstition을 부른 사람을 알아내고 기억하는지는 Entity recall score을 만들어 계산한다.

여기서 e_2는 모델이 기억해야 하는 브릿지 엔티티, 즉 Stevie Wonder이다. 여기서 e_2(0)은 Stevie Wonder의 첫번째 토큰만을 쓴 것이다.
x_l은 l번째 트랜스포머 레이어에서 2-hop prompt, 즉 'The mother of the singer 'Superstition' is' 에서 브릿지 엔티티의 마지막 토큰(singer)의 출력을 나타낸 것이다. 이 히든 스테이트는 W_u와 곱해서 벡터 공간을 표현하도록 한다. 여기서 W_u는 단순히 unembedded weight로, 모델의 어휘 공간에 투영하여 각 단어에 대한 로짓을 표현하도록 한다.
이 방법은 문장의 마지막 토큰 위치에서 구성된 표현이 해당 문장이 다루는 있는 핵심 엔티티에 대한 정보를 인코딩하는 데 중요한 역할을 한다고 보고한 이전 연구들에서 영감을 받았다.
두번째 hop, 즉 첫번째 entity에서 얻은 브릿지 엔티티를 최종 답변을 형성하는데 사용하는지는 Consistency Score를 얻어 계산한다. 여기서 Consistency score은, 두 가지 프롬프트를 주어 답변의 분포의 일관성을 계산한다.
첫번째는 1-hop prompt로, 'Who is stevie wonder's mom?" 와 같이 하나의 추론으로 해결된다. 즉 첫번째 hop에서 모델이 추론해야 하는 답이 이미 주어진다.
두번째는 2-hop prompt로, 'Who is the mom of the singer Superstition?'으로, 두가지 추론을 하여 답변을 만들어내야 한다. 즉 첫번째 추론에서 'Stevie Wonder'을 기억하고, 이것을 이용해서 답변한다. 이론대로라면 1-hop prompt와 2-hop prompt를 사용하는 것의 답변의 분포에는 차이가 없을 것이다.
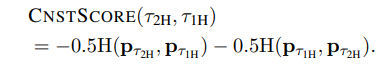
그러므로 위와 같은 식을 이용해서 두 프롬프트의 출력 확률 분포가 얼마나 유사한지 크로스 엔트로피를 통해 표현한다. 이걸 통해 모델이 브릿지 엔티티 정보를 얼마나 잘 활용하고 있는지, 그리고 멀티홉 추론의 연결성을 평가할 수 있다.
결과
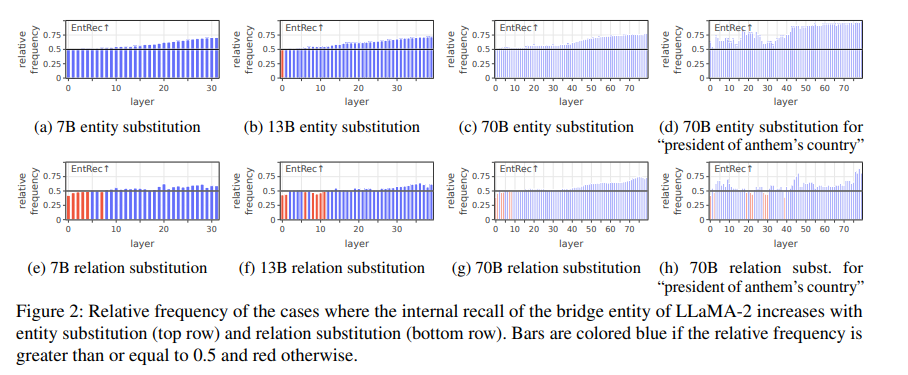
모델이 커질 수록 1-hop의 스코어는 증가했다. 이때 평가는 Who sang Superstition? 과 Stevie Wonder과 연관이 없는 Who sang Thriller? 와 같은 prompt를 주어 각 경우에 Stevie Wonder을 토큰으로 가질 확률을 계산해, 0.5보다 높으면 모델이 제대로 추론하고 있다고 보았다.
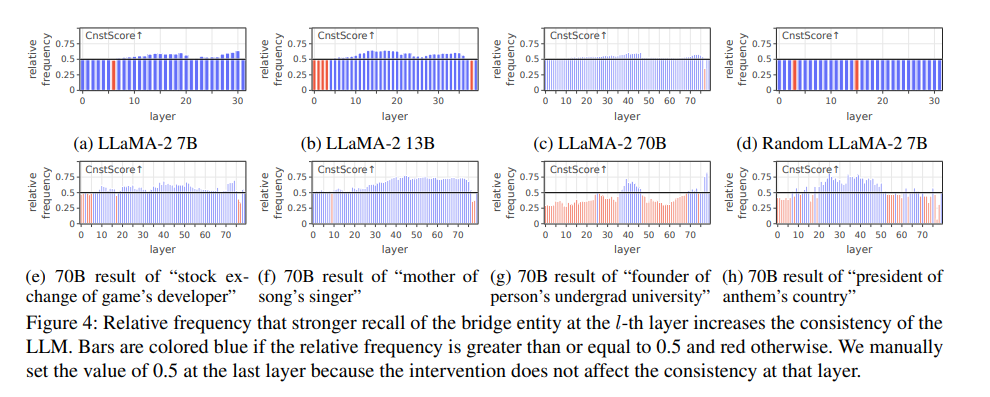
그러나 2-hop의 능력, 즉 있는 정보를 결합하여 새로운 추론을 만들어내는 능력은 모델의 크기와 큰 연관이 없었다. 이때 평가는 두번째 hop과 첫번째 hop의 연관관계이다. Entity recall score이 증가했을 때 Consistency score도 증가하는가? 둘 사이에 직접적인 함수관계는 없다. 그러나 두 점수는 모두 모델의 히든 레이어 출력(𝑥𝑙)에 의존하므로, 𝑥𝑙을 조정하면 ENTREC와 CNSTSCORE 모두에 영향을 줄 수 있다.
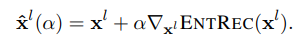
히든 스테이트를 entity recall score을 이용하여 조정하고, 이를 이용하여 CNSTSCORE을 계산하면 된다. 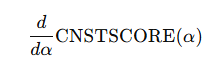
이때 미분값이 양수이면 좋은 쪽으로 바뀌고 있다는 것이고, 음수면 나쁜 쪽으로 바뀌고 있다는 증거이다.
