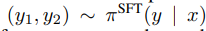
배경
LLM에 강화학습을 왜 해야할까? 모델은 코딩 실수를 이해하지만 답변할 때는 실수를 하면 안되며, 잘못된 상식이라는 것을 인식해야 되지만 답변할 때는 올바른 상식만을 얘기해야한다.
SFT는 인간이 제공한 데이터에서만 학습하기 때문에 특정 응답에 대한 세부 선호도를 반영하기 어렵다. RLHF는 인간 피드백을 사용하여, 모델이 단순히 데이터를 암기하는 것이 아니라, 상황에 적합한 선호도를 기반으로 최적의 답변을 생성하도록 조정한다.
기존 방법론
RLFT 파이프라인
- 언어 모델 STF 훈련
- 리워드 모델 학습

우선 STF 학습한 모델에게 프롬프트를 줘서 두 개의 답변을 내놓게 한다.
인간이 더 나은 것을 라벨링 한 후, Bradely-Terry 모델이 인간의 선호도를 확률로 라벨링 한다.
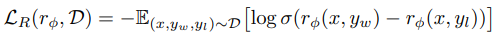
선호되는 답변 𝑦𝑤 와 덜 선호되는 답변 𝑦𝑙 간의 점수 차이를 계산하여, 클수록 모델이 더 명확히 선호도를 학습했다고 판단한다. 결론적으로 선호되는 답변 𝑦𝑤 의 점수를 𝑦𝑙보다 더 높게 만드는 𝑟𝜙(𝑥,𝑦)를 학습한다. - 언어 모델을 리워드 모델을 기반으로 강화학습을 통해 조정

모델이 리워드 모델에서 높은 점수를 받을 수 있도록 학습하는 동시에, 기존의 모델에서 크게 벗어나지 않도록 학습한다.
제시하는 방법론
따로 리워드 모델을 학습시키는 대신, 보상 모델을 특정 방식으로 파라미터화하여 RL 학습 루프 없이 최적화시키려고 한다.
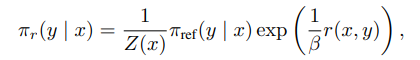
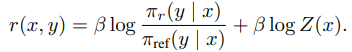
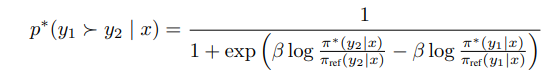

이렇게 derive하면, 최종적으로 리워드 모델없이 선호도를 학습가능하다. πθ가 우리가 학습시키려는 모델이다. y_w이 우리가 선호하는 답변, y_l이 선호하지 않는 답변이다. 식에서 볼 수 있듯 πθ이 y_w을 내뱉을 확률을 높이고 y_l의 확률을 낮추면 된다.
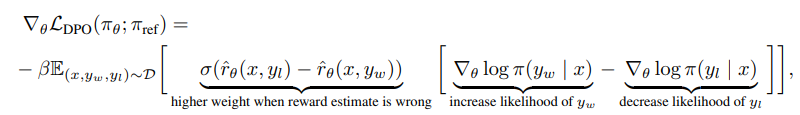
결론적으로 higher weight when reward estimate is wrong의 KL 제약 𝛽는 이러한 가중치 조정의 강도를 제어한다.
𝛽 값에 따라 모델이 참조 모델에 가까이 유지될지, 혹은 더 자유롭게 학습할지를 조정한다. 덜 선호되는 응답 𝑦𝑙에 높은 점수가 매겨졌을 경우, 이를 빠르게 수정하기 위해 해당 예제에 더 높은 가중치를 부여한다.
결과
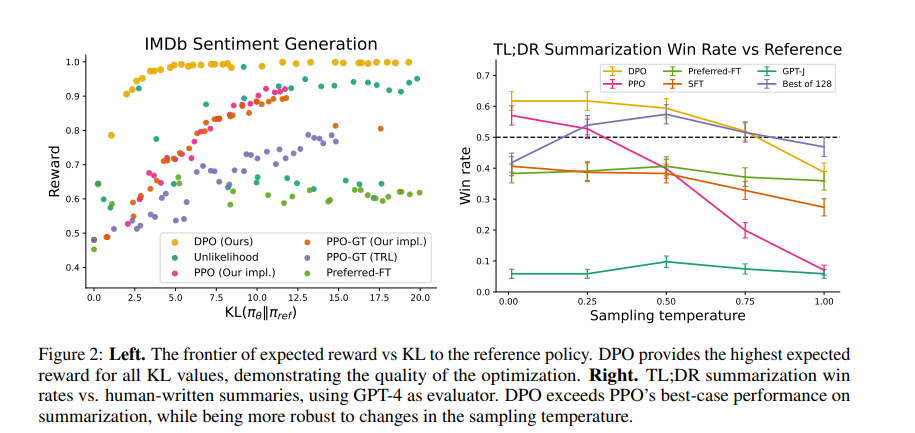
기존 모델과 크게 벗어나지 않더라도 좋은 성능을 보이며, 다양한 temperature에서도 DPO가 거의 좋다는 것을 알 수 있다. 즉 강건하게 훈련되었다
