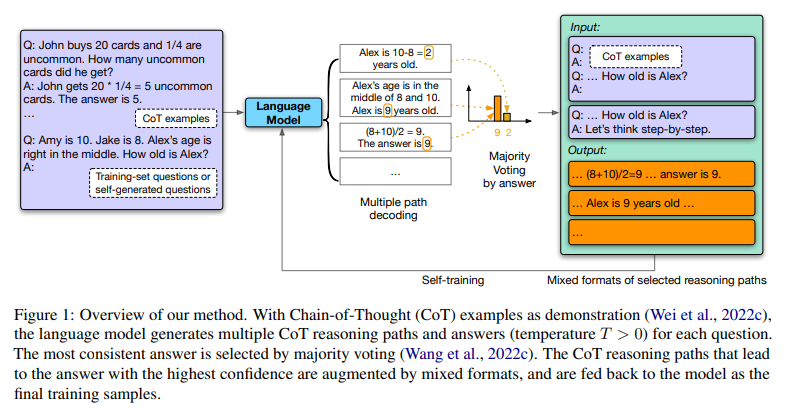
LLM이 스스로 레이블링한 데이터를 활용하여, 스스로 학습하는 것이 가능하다는 것을 보여준다.
메서드
방법은 굉장히 간단하다. 위에 그려져 있는 그래프가 방법론의 전부인데, 우선 CoT를 통해 다양한 답변들을 생성해내고 self-consistency(Majority Voting)을 통해 레이블을 만들어낸다.
그 레이블들을 활용해, 다양한 포맷의 reasoning 데이터를 만들어내 pre-train 된 모델을 fine-tuning 시킨다.

여기서 흥미롭게 본 점은 특정한 스타일이나 포맷에 모델이 오버피팅되지 않게 일부러 동일한 문제를 다양한 포맷으로 학습하였다는 점이다.
--활용 가능?
Generating Questions and Prompts
정답 레이블이 없는 경우도 있지만, 아예 모델이 학습할 질문(데이터)과 CoT example 프롬프트가 없을 수도 있다.
이와 같은 경우에 모델이 스스로 질문과 프롬프트를 생성하여 학습한다면 어떨까?
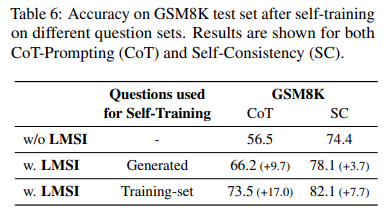
없는 것보단 낫지만, 역시 사람이 만든 데이터셋에서 더 학습을 잘한다는 것을 알 수 있다.
**CoT example 프롬프트는 인간이 만든 것과 거의 비슷한 결과 보임. 다양한 포맷으로 학습하여 영향을 덜 받는 듯?
결과
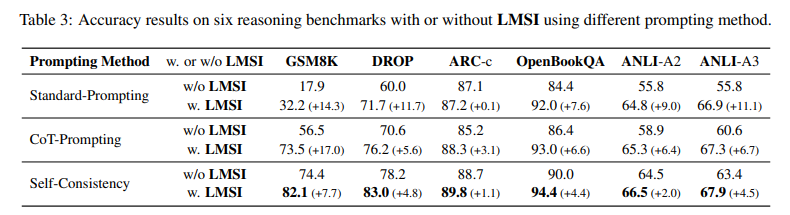
또한, LMSI를 적용한 단일 경로 CoT-Prompting의 성능은 LMSI가 적용되지 않은 모델의 Self-Consistency 보다 더 뛰어납니다. 이는 LMSI가 여러 추론 경로로부터 학습하는 데 도움이 된다는 것을 보여줍니다.
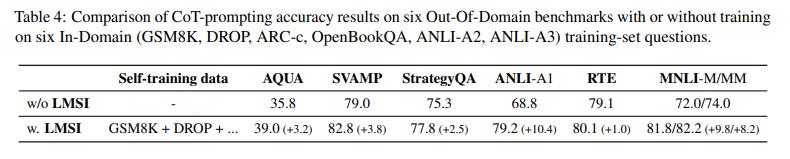
또한 파인튜닝되었기 때문에 특정 도메인에서만 잘 될 것이라고 생각할 수도 있지만, OOD에서도 잘 작동하기에 전반적인 추론 능력이 향상되었다고 말할 수 있다.
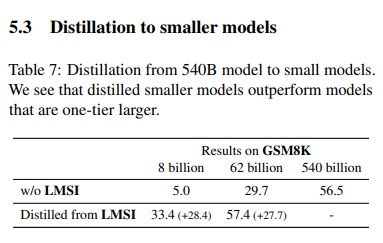
마지막으로 동일한 학습(파인튜닝-> 큰 모델로 만든 데이터)을 작은 모델에 진행하였을 때, 학습이 안된 큰 모델보다 더 좋은 결과를 보인다는 것을 알 수 있다.
--활용 가능
