기존 RAG
기존의 RAG는 토큰 별로 임베딩을 내고, 그 벡터들을 압축하여 하나의 임베딩 벡터로 만들어 정보손실이 일어난다. 하나의 청크, 문단을 하나의 토큰으로 압축한다고 생각해보면, 당연히 생략되어 있는 정보들이 많을 수 밖에 없다.
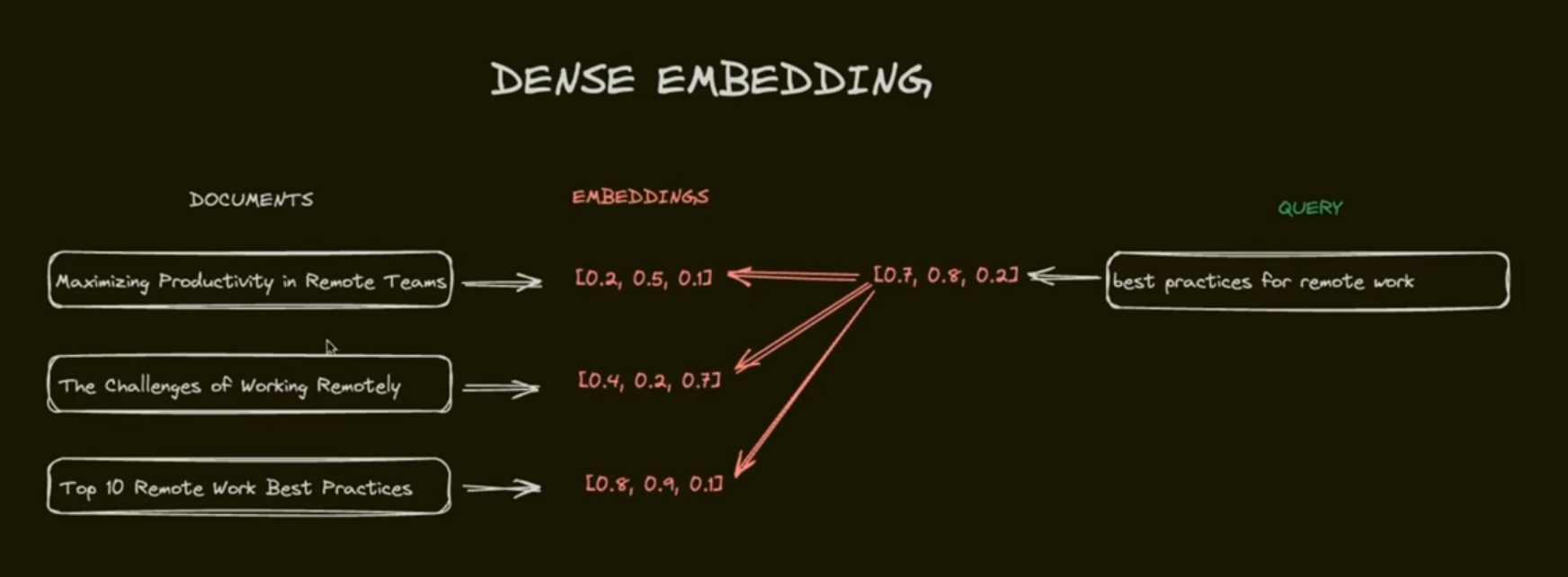
이것을 해결하기 위해 각 토큰별로 유사도로 구하는, ColBERT 가 만들어진 것이다.
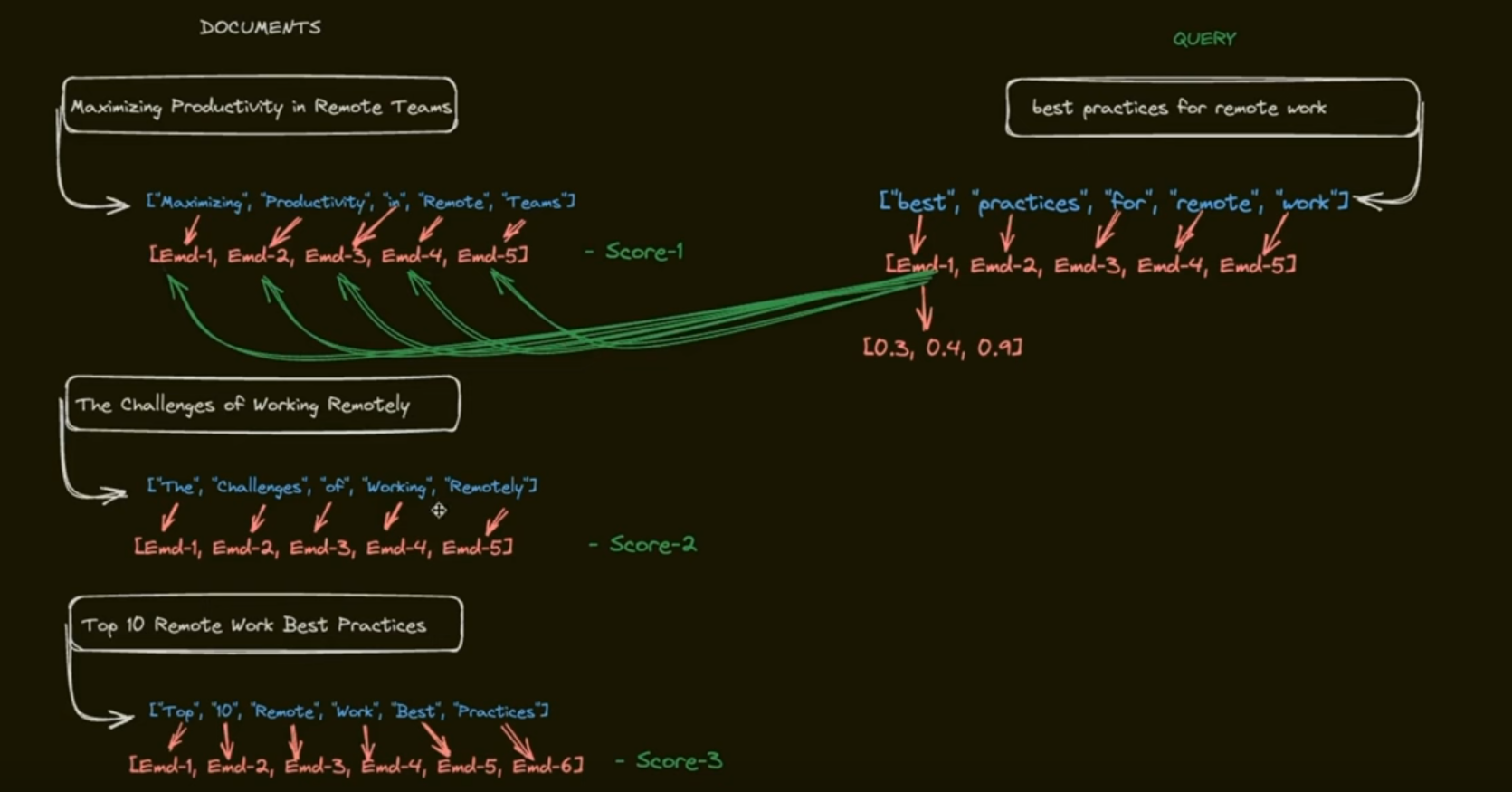
BERT
물론 BERT도 토큰 단위로 쿼리와 document를 한번에 계산하지만, 속도가 중요한 검색에서 쓰기에는 연산량이 너무 많다.
[CLS] Query [SEP] Document [SEP]
BERT는 위와 같이 이렇게 쿼리와 document를 토큰 [SEP] 으로 구별하여 한 청크로 두고, self-attention을 계산한다. 그래프로 표현하면 아래와 같이 된다.
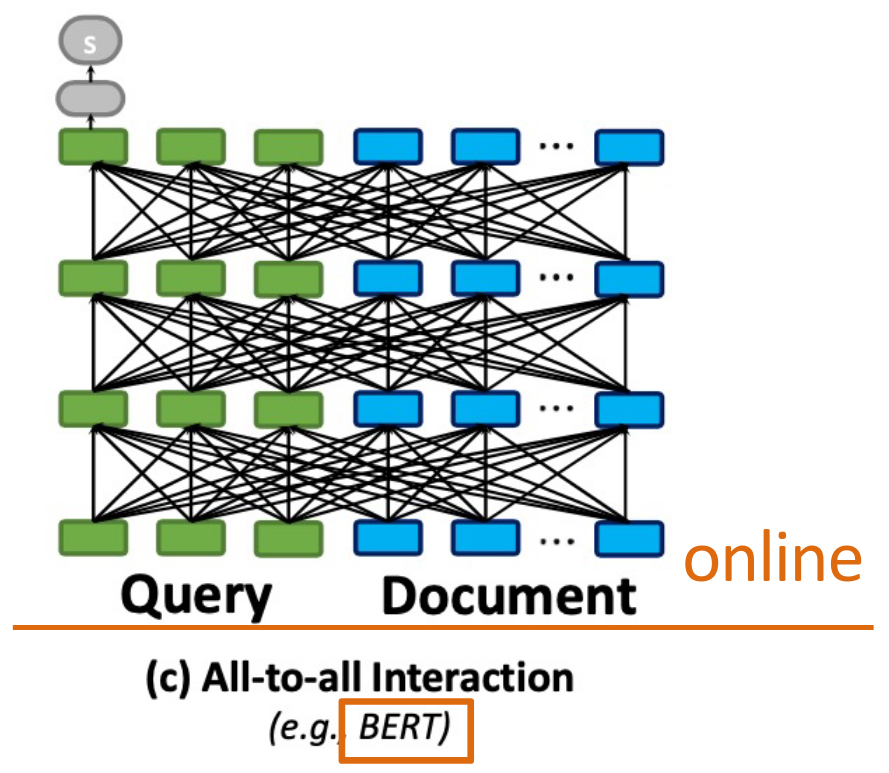
ColBERT
ColBERT는 이러한 시간이 많이 걸리는 문제를 해결하기 위해 미리 document를 임베딩한다.
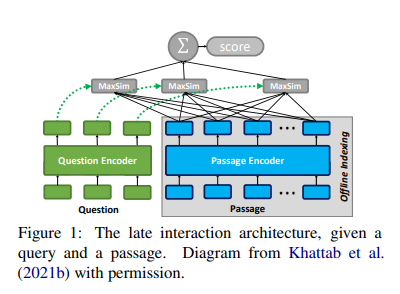
Modeling
이후, Maxsim을 이용하여 쿼리 토큰들의 임베딩과 document 임베딩의 유사도의 최댓값들을 더하여 계산한다.
이런 ColBERT의 랭킹 방식은 (BM25랭킹의 IDF처럼) 중요한 텀에 높은 가중치를 부여하는 효과라고 한다. BERT의 인코더가 임베딩을 만들면서 조사와 같은 큰 의미를 가지지 않는 토큰들보다는 특정 단어와 같이 중요한 의미를 값는 토큰들이 큰 벡터값을 가지도록 훈련이 되었기 때문에 가능하다.
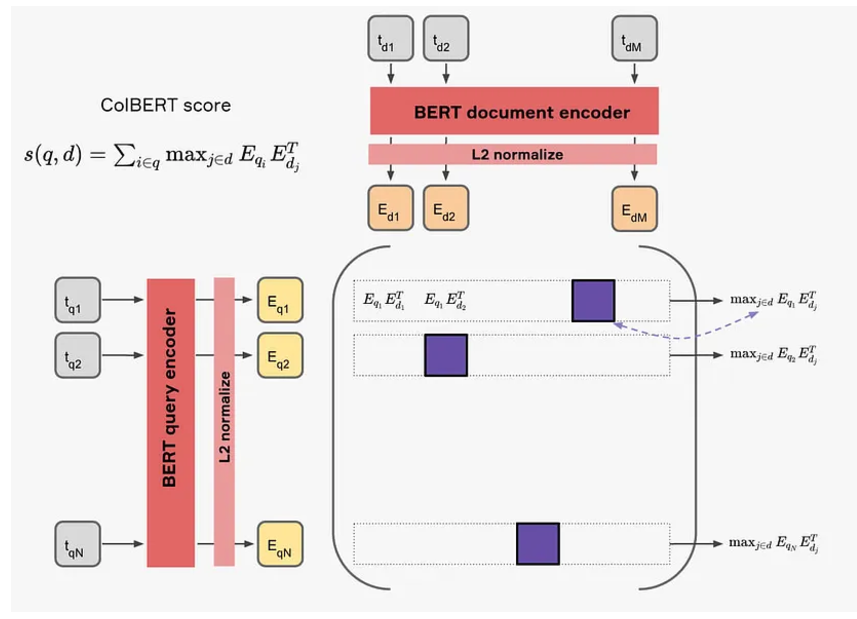
Representation
또한, ColBERT는 아래 그래프를 통해 임베딩되어 있는 토큰 벡터들이 클러스터링 되어있는 것을 발견했다.
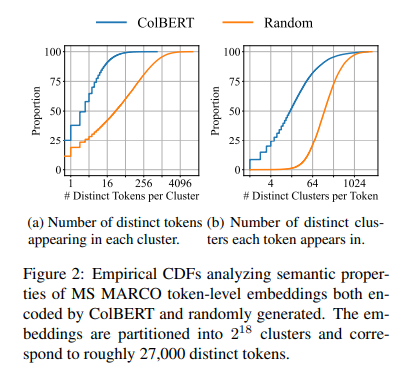
하나의 클러스터 안에, 구별되는 토큰이 random일 때보다 더 적다는 것을 알 수 있다. 이는 colBERT가 contrastive learning으로 쿼리와 관련된 문서의 임베딩은 더 유사하도록, 관련 없는 문서와의 임베딩은 덜 유사하도록(음성 샘플) 최적화되기 때문이다.
이 과정에서 유사한 의미를 가진 단어는 자연스럽게 클러스터로 모이게 되고, 비슷한 의미를 공유하지 않는 단어는 분리된다.
ColBERT는 이러한 특성을 이용해서, 중심점(centroids) C를 k개 골라 벡터 v를 c-r(residual/잔차)로 표현한다. 이때 잔차는 하나 또는 두개의 비트로 표현하여, 임베딩 벡터가 차지하는 공간을 줄인다.
Indexing
앞서 ColBERT가 document를 미리 임베딩한다고 언급했다. 이 임베딩된 document를 retrieve할 때, nearest-neighbor search를 하여 빠르게 가져오기 위해 정리해둔다.
1. Centroid Selection
2. Passage Encoding: representation에서 설명했듯 잔차를 이용해 메모리 효율적으로 임베딩한다.
3. Index Inversion: 빠른 nearest-neighbor search를 하기 위해, centroid과 연관된 임베딩 벡터를 inverted list 형태로 저장해둔다.
C_1: [ID1, ID5, ID8] #해당 centroid에 매핑된 임베딩 벡터
C_2: [ID2, ID6]
C_3: [ID3, ID4, ID7]Retrival
-
우선 쿼리 벡터와 유사한 centroid를 찾는다.
-
Centroids 기반 inverted list를 사용해 유의미한 문서 토큰과 쿼리 벡터의 유사도를 구하여, 토큰에 대해 문서 별로 가장 높은 유사도 점수를 구한다.
-
이후 문서 별로 유사도 점수를 다 더하여, 문서 후보군 n개를 정한다.
-
문서 후보군 n개는 전체 문서를 다 불러와서, MaxSim 점수를 구하여 최종 고려할 문서를 선택한다.

