💡 이 프로젝트는 경희대학교 캡스톤 디자인1 산학연계로 (주) 미리내 멘토와 경희대 학생과 팀을 이뤄 진행하였습니다.
모든 내용은 멘토 및 팀원과 토론을 통해 도출해낸 결과임을 알립니다.
어떻게 하지...?
머신러닝을 이용해서 한국어 띄어쓰기 교정기를 만들기로 했지만, 무엇부터 해야할지 막막하기만 하다.
라이브러리를 찾아보니, 머신러닝을 이용한 한국어 띄어쓰기 교정기들이 꽤 있었다.
그 중 PyKoSpacing이라는 라이브러리의 정확도가 꽤 높았고, 이 라이브러리의 성능을 개선하여 사용하기로 했다.
PyKoSpacing?
PyKoSpacing은 한국어 띄어쓰기 모델로 띄어쓰기가 되어있지 않은 문장을 띄어쓰기를 한 문장으로 변환해주는 라이브러리이다. PyKoSpacing은 대용량 코퍼스를 학습하여 만들어진 띄어쓰기 딥러닝 모델로 준수한 성능을 가지고 있다.
학습에 사용된 모델 구조는 아래 그림과 같다.
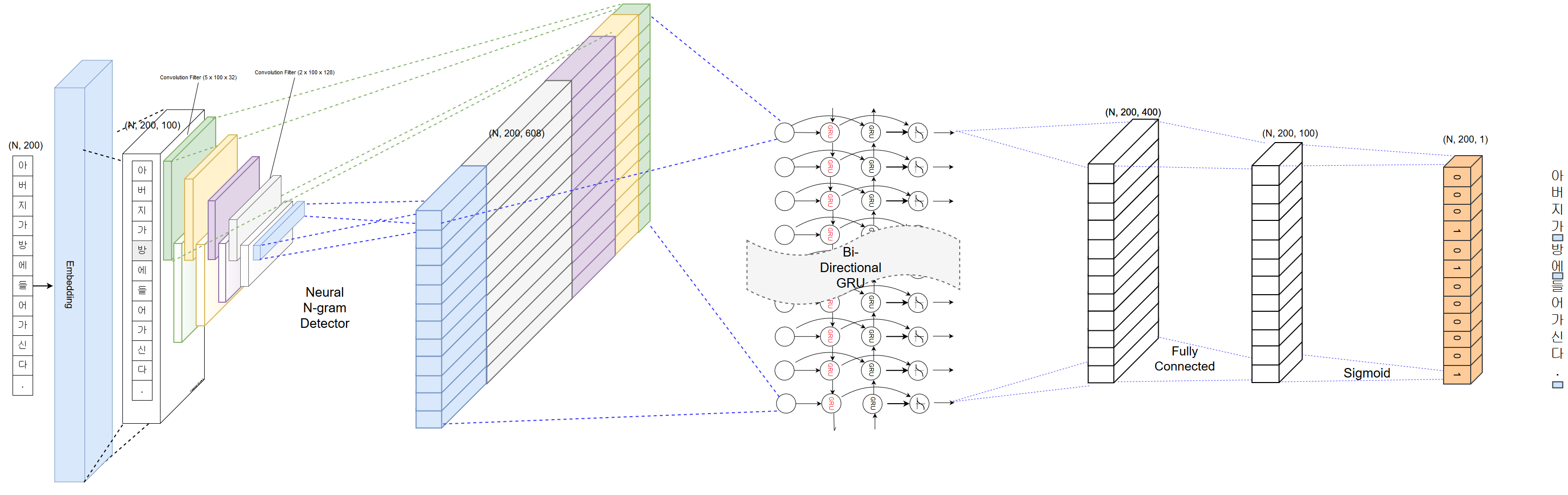
출처: PyKoSpacing Github
어떻게 개선할 것인가?
워드 임베딩은 인간의 단어를 벡터로 표현하는 방법으로 자연어 처리의 큰 비중을 차지하는 분야이다.
컴퓨터는 자연어 단어를 이해할 수 없으며, 연산에 사용할 수도 없다.
따라서, 이를 컴퓨터가 이해할 수 있게 수치화 시킬 필요가 있었다. 이렇게 단어를 벡터로 변환하는 작업이 시작되었으며 워드 임베딩 기법이 되었다.
PyKoSpacing의 워드 임베딩은 Word2Vec 방식이다.
Word2Vec는 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다는 가정에 따라, 벡터에 단어의 의미를 여러 차원에 분산 표현한다.
예를 들어 Word2Vec에서 아버지라는 단어를 표현하는 방식은 [ 0.2 0.3 0.5 0.7 0.2 ... 0.2 ] 이다.
Word2Vec 모델은 현존하는 워드 임베딩 방식 중 가장 유명하고 대표적인 모델로, 장점과 단점이 극명하다.
장점은 유명하기 때문에 pre-trained 된 모델과 reference가 많다는 것이다.
단점은 라이브러리에 존재하지 않는 단어를 벡터로 변환할 경우, Out-of-Vocabulary (이하, OOV) 에러가 발생하는 것이다. PyKoSpacing은 OOV 에러가 발생할 경우, 임의의 벡터값을 입력하여 해당 에러를 처리해주고 있다.
n-gram을 통해 다음 문자로 띄어쓰기가 올 것을 예측하는 PyKoSpacing의 모델에는 해당 OOV 에러가 치명적이다.
이 Word2Vec이라는 워드 임베딩 방식을 FastText로 변경할 것이다.
FastText...?
FastText는 Word2Vec을 개선시킨 방식이다.
Word2Vec은 단어를 쪼갤 수 없는 단위로 취급한다.
반면 FastText는 각 단어를 글자 단위의 n-gram으로 취급한다.
예를 들어, tri-gram으로 ‘자연어 처리’를 표현하면, [ 자연, 자연어, 연어처, 어처리, 처리 ] 라는 결과가 나온다.
이 결과를 내부 단어라고 한다. 이 내부 단어는 백터들의 유사도를 계산할 때 사용한다.
또한, 한글을 자모분해하여 임베딩할 경우, 오타와 같은 노이즈 등에 더 강력한 임베딩 결과를 얻을 수 있다.
다음 글에서는...
개선 방법을 찾았으니 이 방법을 적용하여 띄어쓰기 교정기를 개선 시킨 내용을 담을 것이다!
참고자료
유원준 저, 딥 러닝을 이용한 자연어 처리 입문, https://wikidocs.net/book/2155
PyKoSpacing, https://github.com/haven-jeon/PyKoSpacing
