
💡 이 프로젝트는 경희대학교 캡스톤 디자인1 산학연계로 (주) 미리내 멘토와 경희대 학생과 팀을 이뤄 진행하였습니다.
모든 내용은 멘토 및 팀원과 토론을 통해 도출해낸 결과임을 알립니다.
그래서 결과는...?
PyKoSpacign의 워드임베딩을 Word2Vec에서 FastText로 변경한 결과...
성능은 엇비슷하거나 오히려 약간 떨어져 보였다.
문제가 뭐였을까? 어떻게 해결하지?
FastText는 subword(내부단어)를 이용하여 벡터 간의 유사도를 계산한다.
음절 단위로 토큰화 된 임베딩을 이용하여, OOV의 유사도를 계산할 경우, 내부 단어의 수가 부족하여 정확하지 못한 유사한 글자를 결과 값으로 가지고 오는 것을 확인했다.
따라서 한 음절의 자음과 모음을 분해하여 내부 단어를 늘리고, OOV에러가 발생한 경우 비슷한 형태를 가진 글자를 임베딩 할 수 있도록 했다.
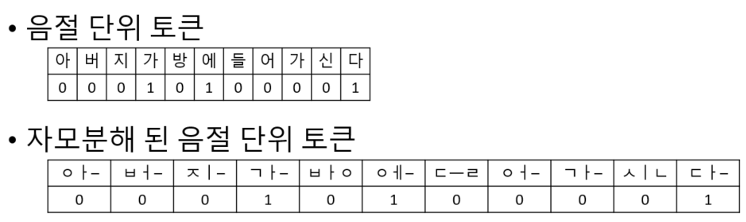
음절 단위 토큰화와 자모분해 된 음절 단위 토큰화의 비교
아래 표는, 자모 분해한 FastText와 자모 분해하지 않은 FastText의 OOV유사도 계산 결과이다.
자모 분해를 할 경우 OOV 글자의 형태에 더 비슷한 글자를 OOV 유사도 계산의 결과로 얻을 수 있음을 알 수 있다.
따라서, 토큰화는 음절 단위로 하되, 한글을 자모분해하여 임베딩 후 모델을 학습시킨다. 결과는 확실한 정확도 상승으로 나타났다.

너무 느려요!
자모분해한 한글의 경우 초, 중, 종성의 3개의 문자로 구성되어 있고, 알파벳, 숫자 그리고 특수문자 등은 1개의 문자로 구성되어 있어 이를 토큰화하기 위한 시간이 더 필요하다.
따라서 기존 자모 분해를 하지 않은 FastText를 이용하되, OOV가 발생했을 때만 해당 글자를 자모분해 후, 자모분해한 corpus로 학습시킨 FastText 모델을 이용하여 형태가 비슷한 글자를 가져오는 방식으로 학습을 진행했다.
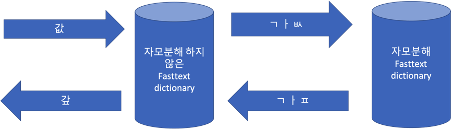
이거 정말 띄어쓰기 해야할 곳이 맞을까..? 임계점!
기존 TrainKoSpacing 모델은 0.5 global threshold으로 띄어쓰기 유무를 결정한다. 띄어쓰기 출력 벡터의 확률 분포를 구해봤을 때, 아래 그림과 같이 양극단을 제외한 중간값들의 분포가 고르게 나타나므로 단일 값으로만 thresholding 할 수 없다고 판단했다.
또한 출력 벡터의 분명한 impulse는 존재했지만 띄워지지 않는 경우가 존재했다.
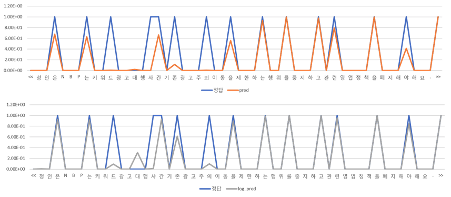
따라서, 출력 벡터의 약한 확률 값을 증폭시키기 위해 log transform 하여 출력 벡터의 확률 값을 증폭한다.
이 때, 확률 값을 일률적으로 증폭시킬 경우 기존의 띄어쓰지 말아야 할 글자까지 threshold를 넘어서 모두 띄어쓰기 되는 문제가 발생했다.
정답 셋은 00100101과 같은 형태를 띄므로, 차분을 활용하여 확실한 impulse를 걸러낸다.
아래 그림은, 기존 예측값, log transform 후, 차분을 이용한 filtering, 최종 결과를 나타낸다.
그래서 얼마나 개선되었나요?
자모분해 후 FastText를 이용한 임베딩을 사용할 경우 성능개선을 확인할 수 있었다.
또한, 자모분해 처리에 걸리는 시간복잡도를 줄이기 위하여 OOV에만 자모분해 한 FastText 임베딩을 사용할 경우 인코딩 과정에서 시간 단축을 확인할 수 있었다.
기존 PyKoSpacing의 성능은 구어체에서 97.1%의 정확도를 보인다.
이 프로젝트는 구어체에서 99%의 정확도를 보이고 있다.
그리 높아 보이지 않지만, 사실 2%는 머신러닝에서는 꽤 높은 성능 향상이다.
다음 글에서는...
띄어쓰기 교정기를 개발하며 느낀 내용을 회고록으로 정리할 것이다!
