Back ground
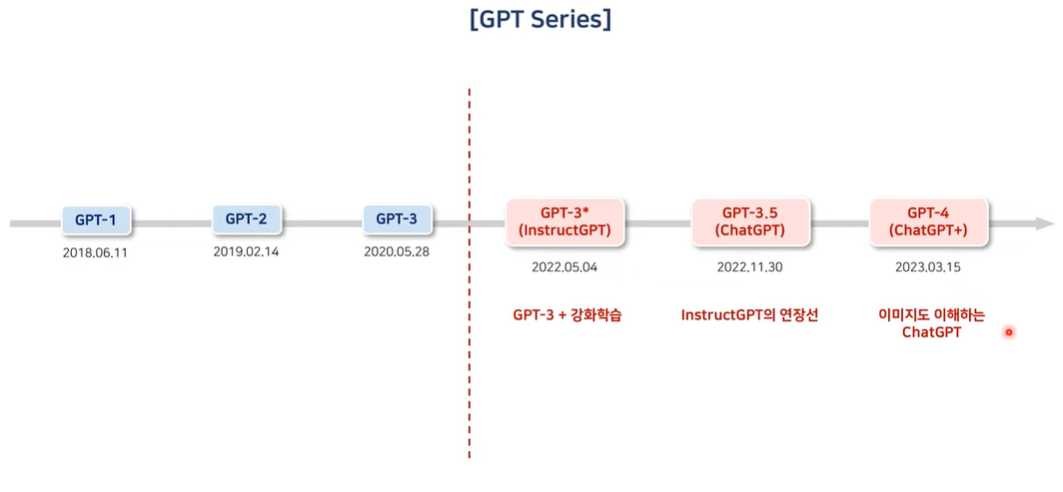
GPT1
Langauge Modeling
특정 sequence를 구성하는 토큰들이 순차적으로 하나씩 입력이 될 때 주어진 토큰의 sequnce를 바탕으로 그 다음에 올 토큰을 순차적으로 예측하는 Auto-Regressive한 특징을 가지고 있음
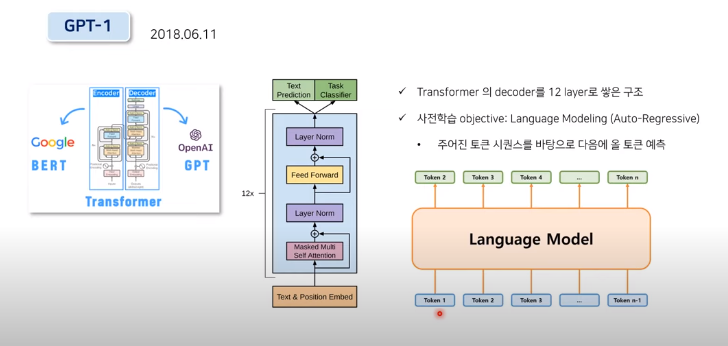
GPT2
In-context learning
다양한 downstream task에 대한 정보를 이미 사전학습에서 배우기 때문에 실제로 풀어야할 downstream task에 대해 별도의 parameter update를 거치지 않더라도 prompt를 추가하기만 하면 zero shot으로 정답 생성 가능
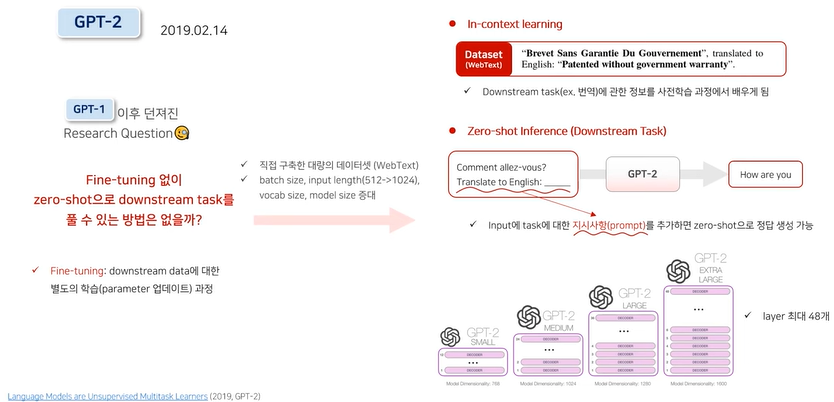
GPT3
In-context learning
- GPT2의 in context learning과 차이 있음
- 모델이 task에 대한 정보를 참고해서 Inference할 수 있도록 input에 예제(demonstration)추가
- 학습 데이터에서 랜덤으로 최대 32개의 문장을 뽑아 연결
문제점 - 사실을 지어내거나, 편향적이거나 유해한 텍스트를 생성하거나, 사용자 지시를 따르지 않는 경우 발생
Alignment: 인간의 의도에 맞게 동작하도록 LM을 조정하는 것 - misaligned: Language Modeling Objective는 주어진 텍스트 시퀀스를 바탕으로 다음에 올 토큰을 맞추는 것으로 사용자의 지시를 안전하고 유용하게 따르는데 영향을 미치지 못한다.
논문의 목표
- 명시적 의도: 사용자의 지시를 제대로 따르는 것
- 암묵적 의도: 신뢰도를 유지하면서 편향되거나 해롭지 않은 답변을 내놓는 것
- 3가지 기준: 도움, 정직, 무해 - 기업이 고객 중심으로 전략을 수립하고 솔루션을 개발하는 것처럼, LM 학습도 사용자 중심으로 바라보자
제안 방법론: InstructGPT
GPT3를 사용자의 입맛에 맞게 Fine-tuning해보자
- 인간의 피드백을 통한 강화학습(Reinforcement Learning with Human Feedback, RLHF)으로 광범위한 지시사항에 따를 수 있도록 GPT-3를 fine-tuning
- 인간의 평가(선호도)를 reward로 사용
- 사용자: 연구에 참여한 저자들과 laber들로 한정됨, 더욱 광범위한 사용자의 선호도를 반영할 수 있는 방안은 여전한 Open Question
학습 방법
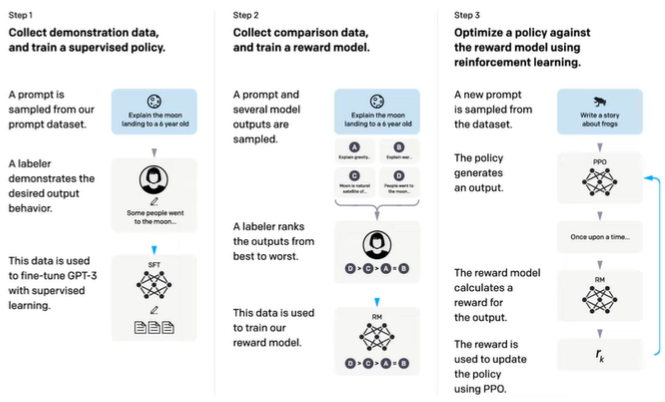
1. Demonstration data 구축 및 Supervised Fine-Tuning(SFT)
- Demonstration data: prompt-response 쌍
- prompt: labeler가 직접작성 + Open AI의 API를 통해 수집된 실제 사용자들의 prompt- response: 주어진 prompt에 대한 답변을 labeler가 직접 작성
- 위 데이터로 GPT3를 finetuning
2. 인간의 선호도를 반영한 Comparison data 구축 및 Reward Model 학습
- prompt와 model이 만든 여러 결과를 sampling
- labeler가 model이 만든 결과에 순위를 매김
- labeler가 선호하는 답변을 예측하는 Reward model 학습
3. Reward Model을 활용하여 PPO 기법으로 GPT3 fine-tuning
- 데이터셋에서 새로운 prompt 추출
- policy(=model)가 결과 생성
- reward model은 해당 결과에 대한 reward 계산
- reward는 PPO 알고리즘을 통해 policy를 업데이트 하는데 사용
Reinforcement Learning
agent가 environment와 상호작용하며 주어진 state s_t에서 누적 보상 합(return)을 최대로 하는 acrion a_t를 선택하는 최적의 policy를 찾아가는 학습 방법
Agent는 Return을 최대화하는 방향으로 policy를 지속적으로 업데이트
Env는 계속해서 agent에게 보상을 주고 전이 확률에 따른 next state를 알려줌 - 학습된 RM을 value function으로 하여 PPO를 통한 policy 최적화: reward model이 최대화되는 방향으로 GPT3를 구성하는 parmaeter를 업데이트
- PPO: 새롭게 업데이트 되는 policy가 이전 policy와 너무 멀어지지 않게 parameter 변동 폭에 제한을 두는 것
Evaluation
평가 기준
Alignment: LM이 사용자의 의도에 맞게 동작하는가?
1. 도움 => Labeler의 판단
2. 정직 => TruthfulQA와 closed-domain 결과로 평가
3. 무해 => 독성 측정용 RealToxicityPrompts 데이터셋으로 평가
논문의 주요 발견
결과1: Labeler들은 GPT3보다 InstructGPT의 결과를 훨씬 선호한다.
결과2: 학습 데이터 생성에 참여하지 않은 labeler에게도 좋은 평가를 받았다.
결과3: GPT3에 비해 정직함이 개선되었다.
결과4: GPT3에 비해 Toxity가 약간 개선되었지만 bias는 개선되지 않았다.
결과5: fine-tuning 과정에서 거의 학습되지 않은 지시사항에도 잘 답변한다.
결과6: 여전히 완벽하지 않고 실수를 범한다.
ChatGPT
InstructGPT와 유사한 학습 방식을 사용하였으나 데이터 수집 단계에서 약간의 차이 존재
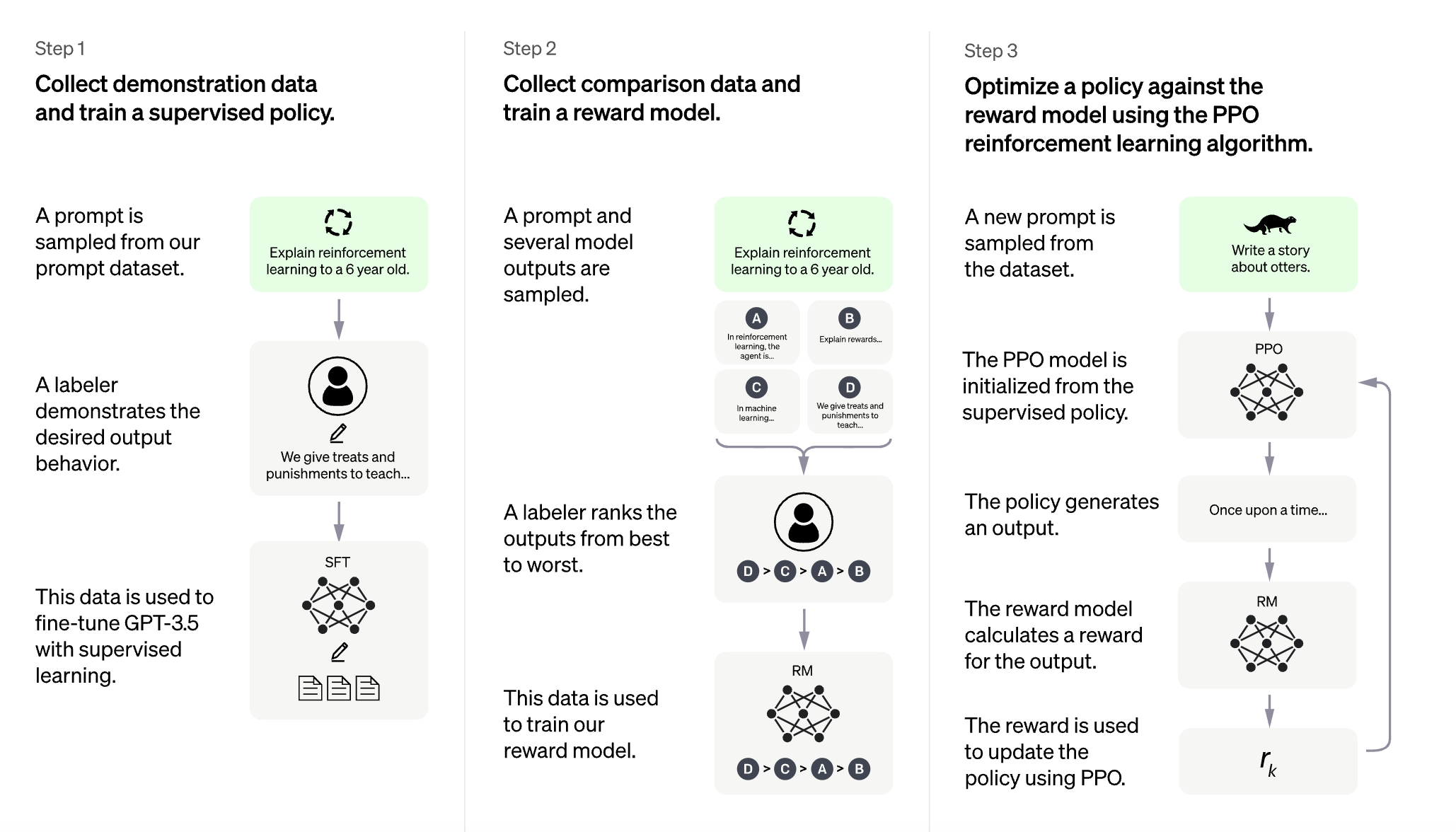
1. 예시 데이터 수집 및 policy 지도학습
- 지도학습을 위해 데이터를 수집할 때 AI 트레이너(사람)가 사용자와 AI assistant 양쪽의 대화를 모두 제공
- 이렇게 만들어진 새로운 대화 데이터셋을 대화형식으로 변경한 InstructGPT 데이터셋과 함께 사용
- 비교 데이터 수집 및 보상 모델 학습
- 비교 데이터 생성을 위해 AI 트레이너가 챗봇과 대화를 하도록 한 후 랜덤으로 모델이 생성한 메시지를 선택하고, 몇몇 대체재(=alternative completions)를 샘플링
