
Transformer에 대해서 설명해주세요.
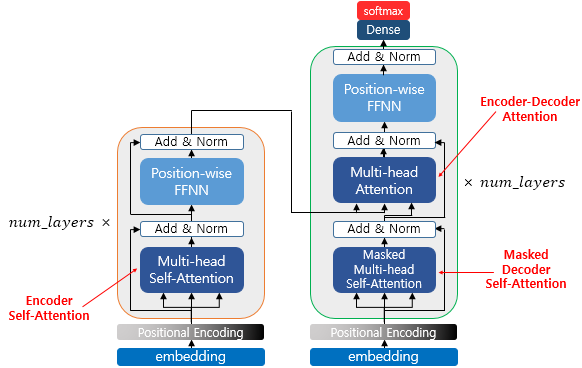
Encoder-Decoder 구조로 이루어진 모델입니다. Attention 매커니즘을 사용하기 때문에,기존 RNN이나 LSTM에서 긴 글의 문맥정보가 소실되는 등의 한계를 극복할 수 있습니다.
Transformer wiki docs ⬅️ 강추!!
교사강요(Teacher Forcing)은 무엇인가요?
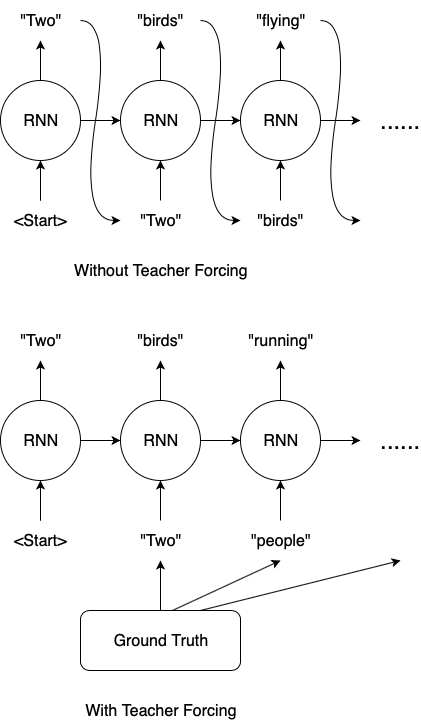
교사 강요(Teacher Forcing)는 sequence-to-sequence류 모델의 훈련 과정 중에 사용되는 기법입니다. 이 기법은 디코더가 다음 단어를 예측할 때 "훈련때만" 이전 단어의 정답을 입력으로 주는 방식으로 작동합니다.
보통 훈련/추론 과정에서 디코더는 이전 시점의 출력을 다음 시점의 입력으로 사용합니다. 하지만 훈련할 때는 이전 시점의 출력이 아닌 정답인 다음 시점의 입력이 주어집니다. 교사 강요를 사용하면 모델이 훈련하는 동안 더욱 안정적으로 학습할 수 있습니다.
medium: what is teacher forcing?
self-attention은 무엇인가요?
NLP 모의면접 (1)기초-attention 참고
BERT와 GPT에 대해 설명해주세요.
BERT는 transformer의 encoder를 사용하여, 양방향으로 문장을 이해하는데 중점을 둡니다. (Bidirectional-encoder) 대규모 corpus를 Masked Language Model과 Next Sentence Prediction(예측, not 생성)의 두가지 사전학습을 통해 학습됩니다.
GPT는 transformer의 decoder를 사용하여, 문장을 생성하는데 중점을 둡니다. (Auto-regressive Decoder) 이전 토큰만을 기반으로 다음 토큰을 예측하기 때문에(단방향), 이해보다 생성에 감정을 가진다.
Bi-directional하다는건 무슨뜻이죠?
양쪽 문맥의 정보를 모두 사용한다는 뜻입니다. 예를 들어 “I (빈칸) a student”라는 문장이 있을 때, (빈칸)은 왼쪽에 있는 “I”와 오른쪽에 있는 “a student”라는 정보를 모두 참고하는 경우입니다.
반대로, GPT류의 decoder 모델들은 unidirectional합니다. 예를 들어 “I am a student”라는 문장을 output으로 만들고 싶다고 할 때, “am”이라는 단어의 위치에서는 “I”의 정보만을 활용하는 경우입니다. “a", "student”는 활용하지 못합니다.
RoBERTa
BERT가 공개된 후 이어진 연구에서 사전 훈련 방법을 수정하면 성능이 더 향상된다는 사실이 밝혀졌습니다. RoBERTa는 더 많은 훈련 데이터로 더 큰 배치에서 더 오래 훈련하며 NSP 작업을 포함하지 않습니다. 이런 변경을 통해 원래 BERT 모델에 비해 성능이 크게 향상됐습니다.
Encoder-Decoder (Sequence-to-Sequence model) 류에 대해 설명해주세요.
encoder와 decoder를 모두 사용한다.
-
T5: T5 모델은 모든 NLU와 NLG 작업을 텍스트-투-텍스트 작업으로 변환해 통합합니다. 모든 작업이 시퀀스-투-시퀀스 문제로 구성되므로 인코더-디코더 구조를 선택하는 것이 자연스럽습니다. 예를 들어 텍스트 분류 문제의 경우 텍스트가 인코더 입력으로 사용되고 디코더는 클래스 대신 일반 텍스트로 레이블을 생성합니다.
-
BART: BART는 인코더-디코더 아키텍처 안에 BERT와 GPT의 사전 훈련 과정을 결합합니다. 입력 시퀀스는 간단한 마스킹에서 문장 섞기, 토큰 삭제, 문서 순환(document rotation)에 이르기까지 가능한 여러 가지 변환 중 하나를 거칩니다. 변경된 입력이 인코더를 통과하면 디코더는 원본 텍스트를 재구성합니다. 이는 모델을 더 유연하게 만들어 NLU와 NLG 작업에 모두 사용할 수 있고, 양쪽에서 최상의 성능을 달성합니다.
GPT부터 BERT까지 트랜스포머 유니버스를 살펴보았어요
핫한 모델들!
(여긴 다들 논문 더 읽어보고 정리하겠습니다ㅎㅎ)
LLaMA
적은 파라미터 수로서 현실적인 추론 비용을 고려하면서도 SOTA와 비슷하거나 더 좋은 성능을 보이는 Foundation Model입니다. 기존 초대형 모델들에 비해 파라미터 수가 적더라도 더 많은 데이터셋으로 더 오래 학습시키는 아이디어를 기반으로 합니다.
Bard
Claud
GPT3보다 넓은 컨텍스트 창, 향상된 추론 능력, 수학 및 언어 이해력, 빠른 응답 시간을 보입니다.
Gemini
Llama, Gemma 또는 Mistral과 같은 오픈 소스 LLM 아키텍처를 설명하세요.
