반갑습니다
꽤 오랜만에 글을 작성하네요.
이번 글에서는 Agent에 대해 소개하고 구현해보도록 하겠습니다.
시작 ~~!
AI Agent ?
AI Agent란, 한 목표를 달성하기 위해 하나 이상의 LLM이 모여 주어진 도구들을 활용하여 결과를 내는 것을 의미합니다.
한번의 결과를 내는 데에 많은 추론 과정을 거칩니다.
사실 AI Agent라는 개념에 대해 소개하기가 쉽지 않습니다.
새로 나온 개념이기도 하고.. 생각보다 어려운 개념이 아니라 새로운 기술들을 적용해서 만든 것도 아니기 때문이죠.
꽤 쉽기 때문에 제 글만 읽으셔도 본인의 AI Agent를 만드실 수 있다고 생각합니다.
AI Agent의 원리
갑자기 엔비디아의 주가가 15프로가 떨어졌다고 합시다.
그러면 저의 15프로의 돈이 사라진 경위를 알고자 엔비디아의 최신 정보를 찾아보겠죠. (에횽 내돈)
일반적인 흐름은 일단 구글이나 유튜브에 엔비디아 주가 라는 주제로 검색을 하는것입니다.
그 뒤에 검색돼 나온 결과들을 하나하나 클릭하며 정보를 수집하겠죠.
정리해봅시다.
- Query 작성
- 검색 결과 탐색
- 검색 결과 방문 후 정보 수집
이네요.
이정도 수준의 Task는 LLM에도 맡길 수 있을 것 같습니다.
1,2,3 에 맞는 Prompt를 작성해봅시다.
# 1
prompt1 = f'''
구글 검색에서 더 정보를 잘 얻을 수 있도록 사용자의 질문을 가공하세요.
사용자 질문 : {query}
가공된 질문 :
'''
가공된_질문 = llm.invoke(prompt1) # 가공된 검색 쿼리가 들어갑니다.
웹검색결과 = 웹검색함수(가공된_질문) # url과 제목을 내보내도록 구성된 함수입니다.
# 2
prompt2 = f'''
다음은 질문에 대한 검색 결과입니다.
이 중 사용자에게 유용한 정보를 담는 검색 결과의 url을 제출하세요.
질문 : {가공된_질문}
검색 결과 : {웹검색결과}
유용한 url :
'''
contexts = []
urls = llm.invoke(prompt2)
for url in urls:
context = 내용추출함수(url) # url을 방문하여 내용을 가져옵니다.
contexts.append(context)
# 3
prompt3 = f'''
주어진 내용을 정리하여 질문에 대한 유용한 정보를 사용자에게 제공하세요.
질문 : {가공된_질문}
주어진 내용 : {contexts}
대답 :
'''
final_result = llm.invoke(prompt3)
프롬프트를 보니 이해가 잘 되실까요 ?
파이썬은 한국어로 변수를 저장할 수 있답니다 하하
위처럼 코드를 구상했다면, 총 3번의 추론을 내부에서 처리하여 원하는 정보들을 제공받을 수 있습니다.
즉 쿼리만 작성하면 클릭과 눈의 피로감을 획기적으로 줄일 수 있는 것이지요.
이것을 Agent라 부를 수 있습니다.
즉 Agent란, 사전에 정의해놓은 Task들을 수행하는 다양한 LLM의 집합이라고 생각하시면 되겠습니다.
Agent 라이브러리
Agent를 좀 더 쉽게 구성할 수 있도록 도움을 주는 라이브러리입니다.
내부에 많은 CoT 과정이 설계돼 있기 때문에 직접 구성하는 것 보다 성능, 안정성이 높습니다.
Agent 구현을 쉽게 도와주는 라이브러리는 크게 세가지가 있습니다.
- CrewAI
Langchain 기반 Agent 프레임워크입니다.
간단한 동작으로 쉽게 Agent 시스템을 구현할 수 있습니다. - AutoGen
MS에서 개발된 Agent 프레임워크입니다.
여러 에이전트간의 내부 대화에 포커스를 맞춘 프레임워크입니다. - Langgraph
Langchain 기반의 그래프 형식 Agent 프레임워크입니다.
low level에서의 Agent를 구현할 수 있으며, low level 수준으로 구현하기에 어려운 만큼 유연성이 아주 높습니다.
이 중, 제가 사용한 프레임워크는 CrewAI입니다.
CrewAI를 고른 이유는 일단 가장 쉽다는 점이겠네요.
아래에서 자세히 설명해보도록 하겠습니다.
CrewAI
AI Agent를 구현하는 데에 도움을 주는 프레임워크입니다.
Agent, Task, Tool, Crew 등으로 구성돼 있습니다.
Multi Agent를 손쉽게 구현할 수 있습니다.
https://docs.crewai.com/introduction
CrewAI의 공식 문서입니다.
위 페이지를 방문해서 간단한 개요 및 Installization에 대해 알 수 있습니다.
아주 친절하고 자세히 나와 있습니다.
영어로 작성돼 있다는 점이 유일한 단점이겠네요.
이 글에서는 개념은 간단히 설명하고 예시를 들어보도록 하겠습니다.
CrewAI의 구조
Agent : 하나의 LLM
Task : Agent가 맡을 일
Tool : Agent가 사용할 수 있는 도구
Crew : 하나의 큰 목표를 달성하기 위해 모인 Agent들의 집합
위 네가지만 알고 있다면 Agent를 구현할 수 있습니다.
CrewAI를 통해 Agent를 제작할 때는 주의깊게 봐야 할 부분은 단 하나입니다.
어떻게 프롬프트를 구성해야 할까?
입니다.
위에서의 검색 과정 예시를 좀 더 좋은 결과를 내도록 섬세히 다듬어야하죠.
Agent
# agents.yaml
searcher:
role: >
뉴스 검색자
goal: >
사용자의 질문에 알맞는 뉴스들을 검색하기 위한 query를 생성
backstory:
당신은 뉴스 검색자입니다.
사용자의 질문에 도움이 될 만한 뉴스를 검색하여 url을 내보내세요.
analyzer:
role: >
뉴스 분석가
goal: >
url들을 받아 도구를 사용하여 뉴스의 내용들을 추출한 뒤, 사용자의 질문에 도움이 될만한 부분들을 출처와 함께 전달
backstory:
당신은 뉴스 분석가입니다.
url들을 받아 도구를 사용하여 뉴스의 내용을 본 뒤, 사용자의 질문에 도움이 될 만한 부분들을 모아 전달하세요.
answerman:
role: |
최종 답변자
goal: |
제공받은 정보를 바탕으로 사용자에게 최선의 답변을 제공합니다.
backstory: |
당신은 최종 답변자입니다.
여태까지 제공받은 정보를 바탕으로 사용자의 질문에 대해 가장 도움이 되는 답변을 제공합니다.
답변을 작성할 때마다 참고한 url의 출처를 즉시 표기하세요.
[출력 형식]
'''
1. 답변 (출처: 참고한 url)
2. 답변 (출처: 참고한 url)
3. 답변 (출처: 참고한 url)
4. ...
'''
CrewAI는 위와 같이 yaml 파일에 Agent의 역할을 자연어 형태로 정의합니다.
role, goal, backstory 총 세가지를 작성하시면 되겠습니다.
agent.yaml파일을 작성했다면, task.yaml파일을 작성해야겠죠.
Task
# tasks.yaml
news_search_task:
description: >
사용자의 질문에 답하기 위해 적절한 검색어(20자 이내)를 작성하여 뉴스의 url들을 내보냅니다.
제공되는 url은 반드시 리스트의 형태여야 합니다.
도구를 사용하여 검색합니다.
질문: {query}
expected_output: >
사용자의 질문에 도움이 되는 뉴스 기사들의 URL 리스트
agent: searcher
news_analyze_task:
description: >
뉴스의 URL들을 받아 사용자의 질문에 도움이 될 수 있는 부분들을 추출합니다.
도구를 사용하여 URL에 방문하여 뉴스의 제목과 본문을 가져옵니다.
제공된 정보는 최종 답변가에게 전달됩니다.
질문: {query}
[출력 형식]
1. 뉴스 제목1(출처 url1) : 본문 내용1
2. 뉴스 제목2(출처 url2) : 본문 내용2
3. ...
expected_output: >
사용자의 질문에 도움이 될 수 있는 뉴스의 제목, 출처, 본문 내용들
agent: analyzer
context:
- news_search_task
answer_task:
description: >
analyzer에게 제공받은 정보를 바탕으로 사용자의 질문에 대해 가장 도움이 되는 답변을 제공합니다.
신뢰성을 위해 답변을 전부 제공한 후, 반드시 뉴스의 제목과 url을 같이 첨부합니다.
마지막에는 질문에 대한 종합적인 답변을 제시합니다.
질문: {query}
expected_output: >
제공된 정보를 바탕으로 만들어진 신뢰성 있는 대답과 그 대답들의 출처
agent: answerman
context:
- news_search_task
- news_analyze_taskTask는 description, expected_output, agent, context(선택) 을 작성합니다.
어떤 일인지, 누가 맡을것인지, 어떤 결과를 내야 하는지, 참고해서 볼 내용이 있는지에 대해 상세히 기술합니다.
이렇게 Agent와 Task가 구성됐다면, Agent가 사용할 Tool에 대해 정의해봅시다.
Tool
# naver_news_search.py
from crewai.tools import tool
import os
import urllib
import json
@tool('naver_news_search')
def get_news_urls(query:str) :
"""Get news URLs related to a query from the Naver News search engine."""
client_id = os.environ['NAVER_API_CLIENT_ID']
client_secret = os.environ["NAVER_API_CLIENT_SECRET"]
encText = urllib.parse.quote(query)
url = "https://openapi.naver.com/v1/search/news?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if (rescode==200):
response_body = response.read()
result = json.loads(response_body)
return result['items']
else:
print("Error Code:" + rescode)
Tool은 함수를 구성한 뒤, 위에 @tool 이라는 데코레이터를 작성해서 crewai에서 사용할 수 있는 tool임을 알려주도록 합시다.
위 tool은 query를 받아 네이버 뉴스 기사 API를 사용하여 url과 제목을 제공해주는 함수입니다.
url을 받았다면, 그 url에 하나하나 접속해서 내용을 추출하는 함수도 필요하겠죠?
# urls_to_context.py
from newspaper import Article
from crewai.tools import tool
@tool('urls_to_context')
def get_article(urls:list):
"""Get news contexts from URLs"""
result = {'title': [], 'context': []}
for url in urls:
# 기사 객체 생성
try:
article = Article(url)
# 기사 다운로드 및 파싱
article.download()
article.parse()
# 본문 내용 추출
result['title'].append(article.title)
result['context'].append(article.text)
except:
pass
return result위 코드는 Article이라는 라이브러리를 사용하여 url에 방문한 뒤 내용을 파싱하는 함수입니다.
Tool을 제공할 때에는 input으로 받는 형태가 무엇인지 잘 명시하도록 합시다.
그래야 오류 없이 Agent가 Tool을 사용할 수 있습니다.
자 모든 구성이 끝났네요.
Agent들과 Agent들이 수행할 Task, Agent들이 사용할 Tool에 대해서 정의하였습니다.
그렇다면 이들을 모아 하나의 Crew를 만들어 봅시다.
Crew
# yongari_crew.py
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task, before_kickoff
from .tools import naver_news_search, urls_to_context
@CrewBase
class NewsCrew:
agents_config = 'config/news_search_agents.yaml'
tasks_config = 'config/news_search_tasks.yaml'
@before_kickoff
def before_kickoff_function(self, inputs):
return inputs # before_kickoff를 구성하여 시작 전에 사용자로부터 쿼리를 받을 수 있도록 구성합니다.
@agent
def searcher(self) -> Agent:
return Agent(
config = self.agents_config['searcher'],
verbose = True,
tools = [naver_news_search.get_news_urls],
llm = 'gpt-4o-mini'
)
@agent
def analyzer(self) -> Agent:
return Agent(
config = self.agents_config['analyzer'],
verbose = True,
llm = 'gpt-4o-mini',
tools = [urls_to_context.get_article]
)
@agent
def answerman(self) -> Agent:
return Agent(
config = self.agents_config['answerman'],
verbose = True,
llm = 'gpt-4o-mini',
)
@task
def news_search_task(self) -> Task:
return Task(
config = self.tasks_config['news_search_task']
)
@task
def news_analyze_task(self) -> Task:
return Task(
config = self.tasks_config['news_analyze_task']
)
@task
def answer_task(self) -> Task:
return Task(
config = self.tasks_config['answer_task']
)
@crew
def news_crew(self) -> Crew:
return Crew(
agents=self.agents, # @agent 데코레이터로 감싸진 애들을 자동으로 가져옴
tasks=self.tasks, # @task 데코레이터로 감싸진 애들을 자동으로 가져옴
process=Process.sequential,
verbose=True,
)
이렇게 CrewBase라는 데코레이터를 통해 클래스를 제작하고, 내부에 Agent, Task, Crew를 구성합니다.
tool은 사전에 정의해놓은 함수를 다른 폴더에서 임포트해도 좋고 클래스 위에 구현해도 좋습니다.
다만 임포트하여 사용하는 것이 가독성에는 더 좋겠습니다.
폴더 구조에 대해 간단히 설명해보자면
yongari_crews라는 폴더 안에
- config
- agents.yaml
- tasks.yaml - tool
- naver_news_search.py
- urls_to_context.py - yongari_crew.py
이렇게 구성되겠네요.
야호 끝났다
한번 실행시켜보도록 하겠습니다.
위와 같이 load_dotenv를 통해 .env에 작성돼 있는 OpenAI API Key를 로드해줍시다.
저는 GPT 4o mini를 사용하였기에 OpenAI 키이지만.. 다른 모델도 지원합니다.
원하는 모델의 API 키를 가져오도록 합시다.

이처럼 input을 딕셔너리 형태로 전달합니다.
yaml 파일의 Task를 정의할 때 {query}라는 이름으로 질문을 전달하기에 'query'로 전달합니다.
kickoff는 crew를 동작시킬 때 사용하는 명령어입니다.
그래서 동작 과정을 살펴보면 ?
-
tool을 사용하여 네이버 뉴스를 검색합니다.
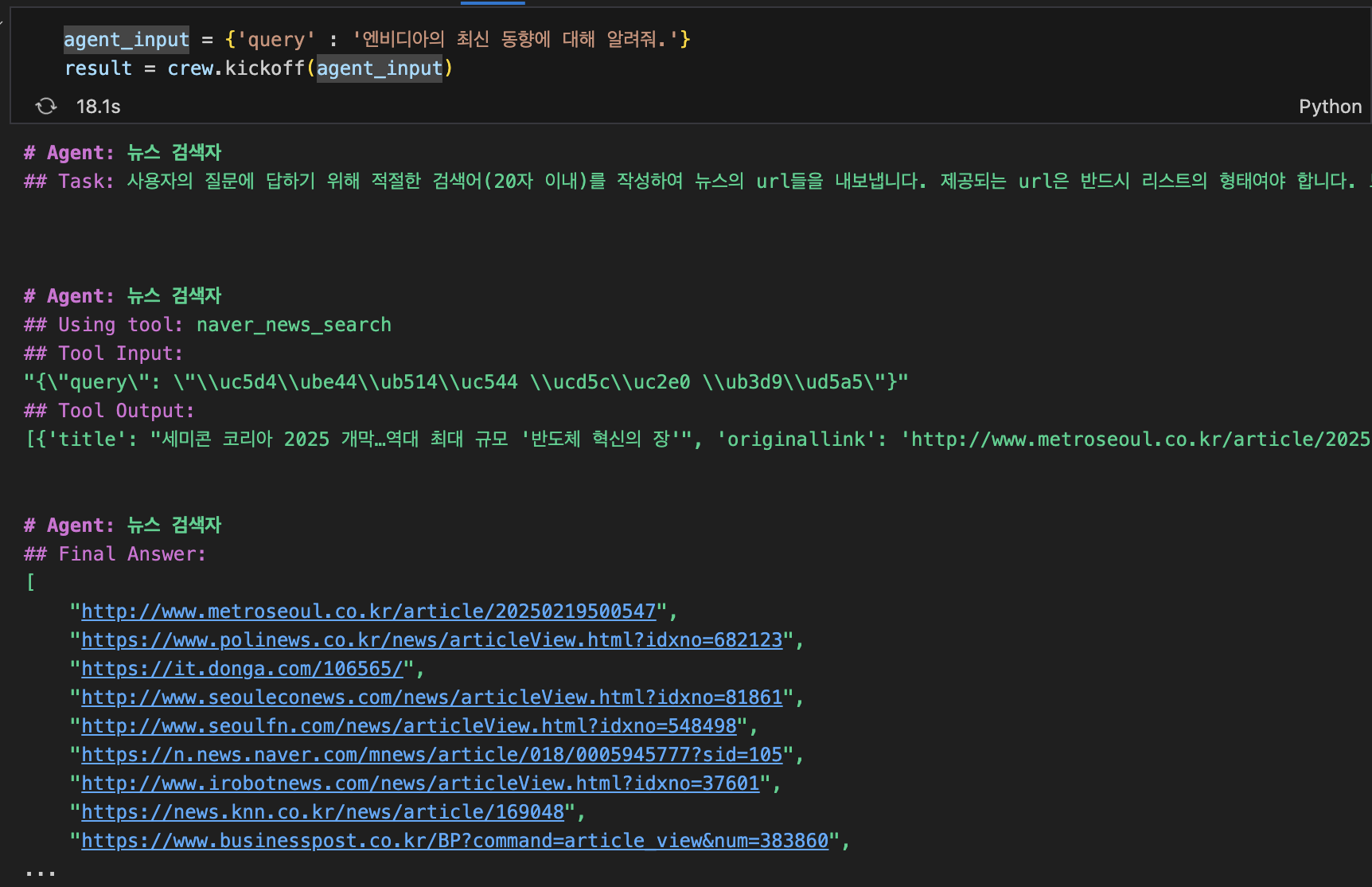
-
검색 결과로 받은 url들을 방문하여 context를 추출한 뒤, 최종 답변가에게 넘겨 사용자의 질문에 대답합니다.
최종 답변가에게 정보가 넘어가서 output을 생성하고 있군요.
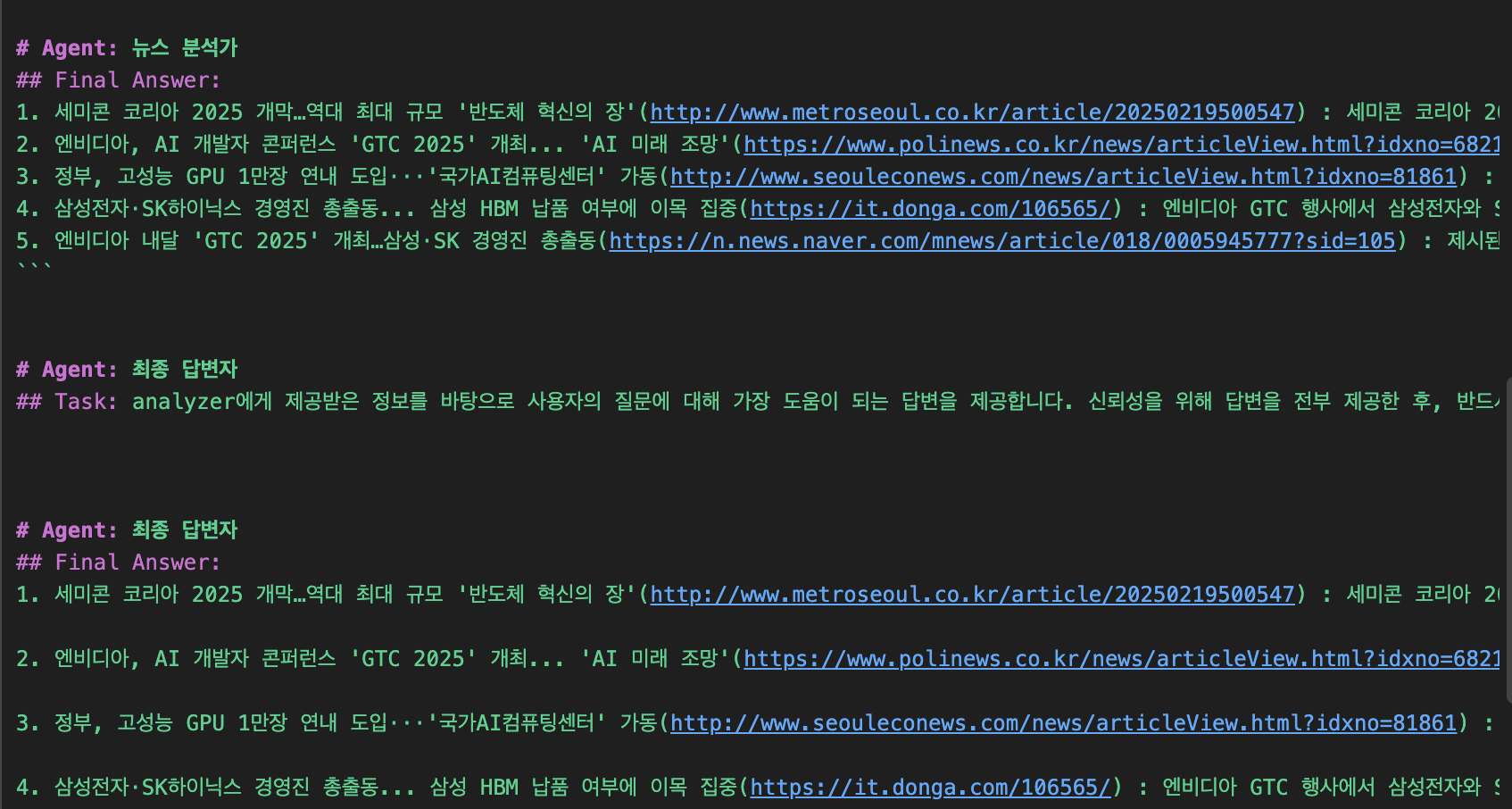
진행된 작업들은 CrewOutput이라는 형태로 result에 담깁니다.
result.raw를 통해 최종 output을 볼 수 있으며, result.dict를 통해 각 Agent들의 사고 과정을 하나하나 살펴볼 수도 있습니다.
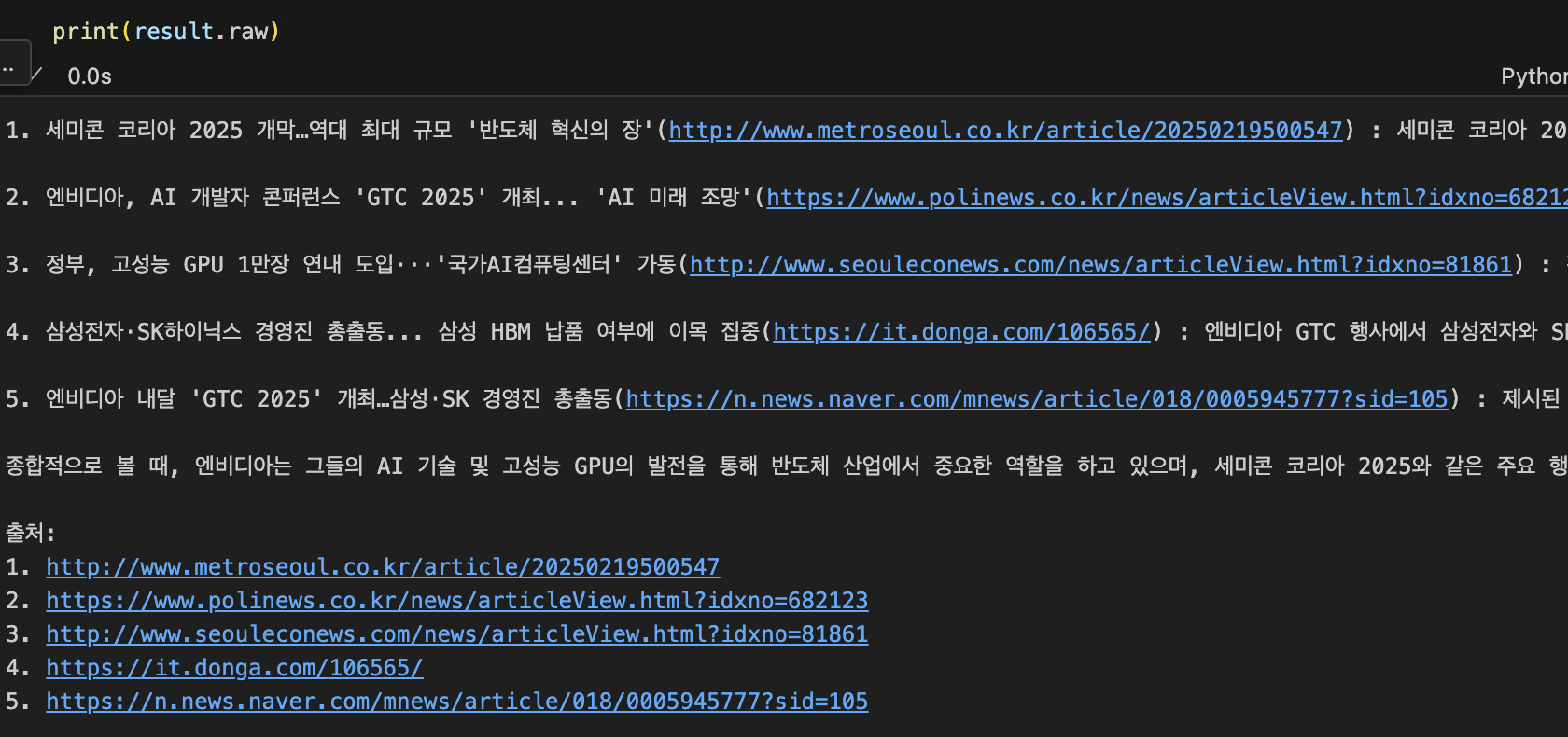
이렇게 제가 많은 클릭과 검색을 반복해야 하는 작업을 한순간에 완료하였습니다.
대박티비군요.
'
'
'
이번 글에서는 Agent의 개념에 대해 알아보고 검색 Tool을 활용한 Agent 구축에 대해서 살펴봤습니다.
본인이 Tool을 어떻게 지정하느냐에 따라 내부에서 코드를 실행시킬 수도 있고, 사용자 컴퓨터에 있는 데이터를 참고해서 대답을 작성할 수도 있습니다.
무궁무진하죠 ㅎㅎ
CrewAI의 공식문서에는 제가 소개한 기능 외에도 수많은 기능이 존재합니다.
원하는 기능들을 찾아서 코드 예제와 함께 살펴보시면 금방 익히실 수 있을겁니다.
혹시라도 CrewAI를 통한 개발에 어려움이 있다면 댓글 달아주시면 제가 아는 만큼 도와드리겠습니다.
이만 글을 마칩니다.
감사합니다 !
