반갑습니다
이전에 다뤘던 RAG의 심화라고 할 수 있는 멀티모달 RAG에 대해 설명할까 합니다.
심화라고 했지만 사실 더 어려운 개념은 아닙니다.
그저 Retrieval의 대상을 다양한 형태로 다룰 수 있도록 하는 것이지요.
RAG?
LLM의 답변이 최신성을 갖춤과 동시에 환각(Hallucination)답변을 내보내지 않도록 참고 자료를 함께 input으로 넣어주는 방법론을 의미합니다.
RAG는 유명한 방법론이라 다들 많이 들어보셨을 거라 생각합니다.
제 블로그에서도 자주 다뤘던 것 같네요.
다양한 Context가 있는 Corpus를 바탕으로 사용자 질문에 대한 관련성 있는 문서들을 가져와 답변에 활용합니다.
이 Context들은 대부분 Text의 형태로 구성돼 있습니다.
하지만 만약
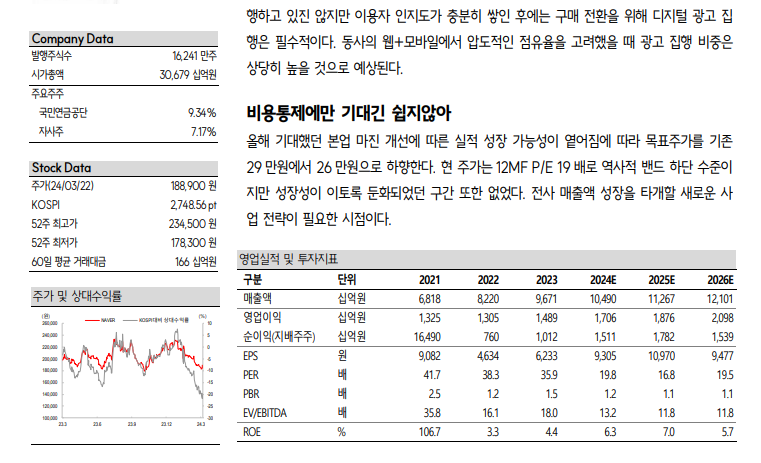
이와 같이 그래프, 표, Text가 함께 들어있는 문서에 있는 내용에 대해 질문한다면 어떻게 답변해야 할까요 ?
가령 '네이버의 2024년 주가 및 상대수익률에 대해 알려줘.' 라는 질문을 던졌다면
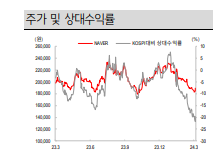
위의 문서에서 이 부분을 참고해서 답변해야 올바른 정보를 전달할 수 있겠죠.
근데 저 그림을 text로 표현해보면...
주가 및 상대수익률
(원) NAVER KOSPI 대비 상대수익률 (%)
260,000 10
240,000 5
220,000 0이런식의 text로 구성됩니다.
이걸 참고해서 질문에 답변하는 것은 쉽지 않겠죠. 그래프는 표현할 수 없으니까요.
따라서 우리는 Retrieval에 이미지, 오디오와 같은 Text가 아닌 정보를 다룰 필요가 있습니다.
Multi-Modal RAG
Text 데이터뿐만아닌 다른 데이터를 Retrieval의 결과로 다뤄 다양한 형태의 데이터를 RAG에 활용하는 기법입니다.
Multi-Modality를 고려해야 한다는 것은 알겠는데 ..
어떻게 고려해야 할까요 ?
크게 살펴보면 두가지가 있습니다.
1. 여러 Modality를 하나의 벡터 공간에 Embedding하기
이미지, 오디오, 텍스트를 하나의 임베딩으로 바꿉니다.
즉, Multi-Modal모델을 사용해서 이미지, 텍스트, 오디오 등 전부 제대로 된 의미를 갖는 임베딩 벡터로 바꾸는 것이지요.
이 경우, 사과를 먹는 그림과 '사과를 먹다' 는 비슷한 임베딩 벡터를 가지게 되겠습니다.
2. 여러 Modality를 하나의 Modality로 통합하기
이미지, 오디오 등을 하나의 Modality로 통합합니다.
일반적으로는 Text가 되겠네요.
사과를 먹는 그림이 있다면, 이를 '한 남자가 사과를 먹고 있다.' 와 같은 Caption으로 바꿉니다.
그리고 이를 Retrieval에 활용합니다.
이외에도 Audio가 있다면 TTS 후 LLM을 통해 요약하는 등 다양하게 활용할 수 있습니다.
Multi-Modal RAG의 구축 과정
2번을 예시로 한번 RAG를 만들어 보겠습니다.
그래프 이미지가 있습니다.

이 이미지를 Multi-Modal 모델에게 설명하도록 프롬프팅하면
이 그래프는 시간이 지남에 따라 늘어나고 있는 인터넷 사용자 수에 대한 선 그래프입니다.
그래프를 보면 2000년 이후 인터넷 사용자가 급격히 증가했으며,
2010년 이후에도 지속적인 증가세를 보이고 있습니다.
또한, 오른쪽 하단에 집(와이파이) 및 노트북(인터넷) 아이콘이 있어
인터넷 사용 환경을 상징적으로 나타내고 있습니다.이렇게 이미지 데이터를 텍스트 데이터로 변환합니다.
그리고 이를 임베딩 모델에 넣어 임베딩 벡터로 바꾼 뒤, VectorDB에 넣어 RAG 시스템을 구축하면 됩니다.
이 때, Metadata를 활용해 이미지나 이미지의 출처, 페이지 등을 기입하여 RAG에 같이 활용할 수 있습니다.
이렇게 구축된 VectorDB는
'인터넷 사용자 수는 점점 늘어나고 있니 ?'
라는 질문에
위 글을 매개로 검색되게 되고, 검색된 객체는 메타데이터를 통해 이미지를 가져올 수 있게 됩니다.
뭐가 더 좋을까?
RAG 시스템은 정말 너무 다양하고 ...
너무 많은 접근 방법이 있습니다.
본문, 그래프, 오디오 등을 전부 비슷한 길이의 Summary로 만들기도 하고
본문만 Text Splitter로 자르기도 하고..
그래프의 Summary를 만들 때 그래프 위 아래의 글을 함께 넣어 제작하기도 합니다.
또, VectorDB에 구축할 데이터의 개수에 따라서도 멀티모달 임베딩의 성능이 많이 달라지기도 하고.. 임베딩 모델에 따라서도 많이 갈리게 됩니다.
그렇기에 RAG 시스템은 개념은 쉽지만 최적의 성능을 찾는 것이 많이 어렵지요.
아주 섬세하게 조정해 나가며 주어진 상황에 맞는 RAG 시스템을 구축하는 역량을 기르는 것이 중요하겠습니다.
'
'
'
이번 글에서는 Multi-Modal RAG에 대해서 알아봤습니다.
혹시라도 미흡한 부분이 있다면 댓글로 달아주세요.
깊게 고민해보고 고치겠습니다.
감사합니다 !
