반갑습니다.
앞의 글에서는 제 개인적 견해와 EDA가 뭔지 추상적으로 설명했었는데요.
이번에는 파이썬의 시각화 라이브러리 Matplotlib에서 가장 많이 사용되는 3가지 그래프에 대해서 소개해보겠습니다.
Matplotlib이 뭔가염?
Matplotlib는 Python 프로그래밍 언어 및 수학적 확장 NumPy 라이브러리를 활용한 플로팅 라이브러리이다. Tkinter, wxPython, Qt 또는 GTK 와 같은 범용 GUI 툴킷을 사용하여 애플리케이션에 플롯을 포함 하기 위한 객체 지향 API를 제공한다. -위키백과-
좀 주의 깊게 보셔야 할 점은 Numpy라이브러리를 활용했다는 것입니다.
Numpy는 C++로 만들어져서 속도가 빠르죠.
파이썬에서는 Numpy를 활용한 라이브러리들이 상당히 많은데, 많은 연산을 빠르게 할 수 있다는 점이 메리트같습니다.
Matplotlib는,
import matplotlib.pyplot as plt로 임포트합니다.
Numpy를 np로 다들 줄이는 것처럼 Matplotlib 또한 plt로 많이 줄여서 사용합니다.
Matplotlib를 활용한 시각화
다양한 그래프들을 소개하기 전에, Matplotlib를 사용하기 위한 기본적인 틀을 설명해보겠습니다.
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2,2, figsize = (7,7))
#Visualization Codes
plt.show()
로 작성해볼 수 있습니다.
fig는, 시각화 할 큰 창을 의미하고, axes는 그 안의 그림들을 의미합니다.
subplots(2,2)라는 것은 가로 2, 세로 2의 subplots들을 만든다는 의미입니다.
axes[0][0]. axes[0][1], axes[1][0], axes[1][1] 총 네가지의 그림을 그릴 수 있습니다.
마지막으로, plt.show()를 통해 여태 그린 그림들을 띄울 수 있게됩니다.
이제 시각화 그래프들을 나열해보겠습니다.
1.Barplot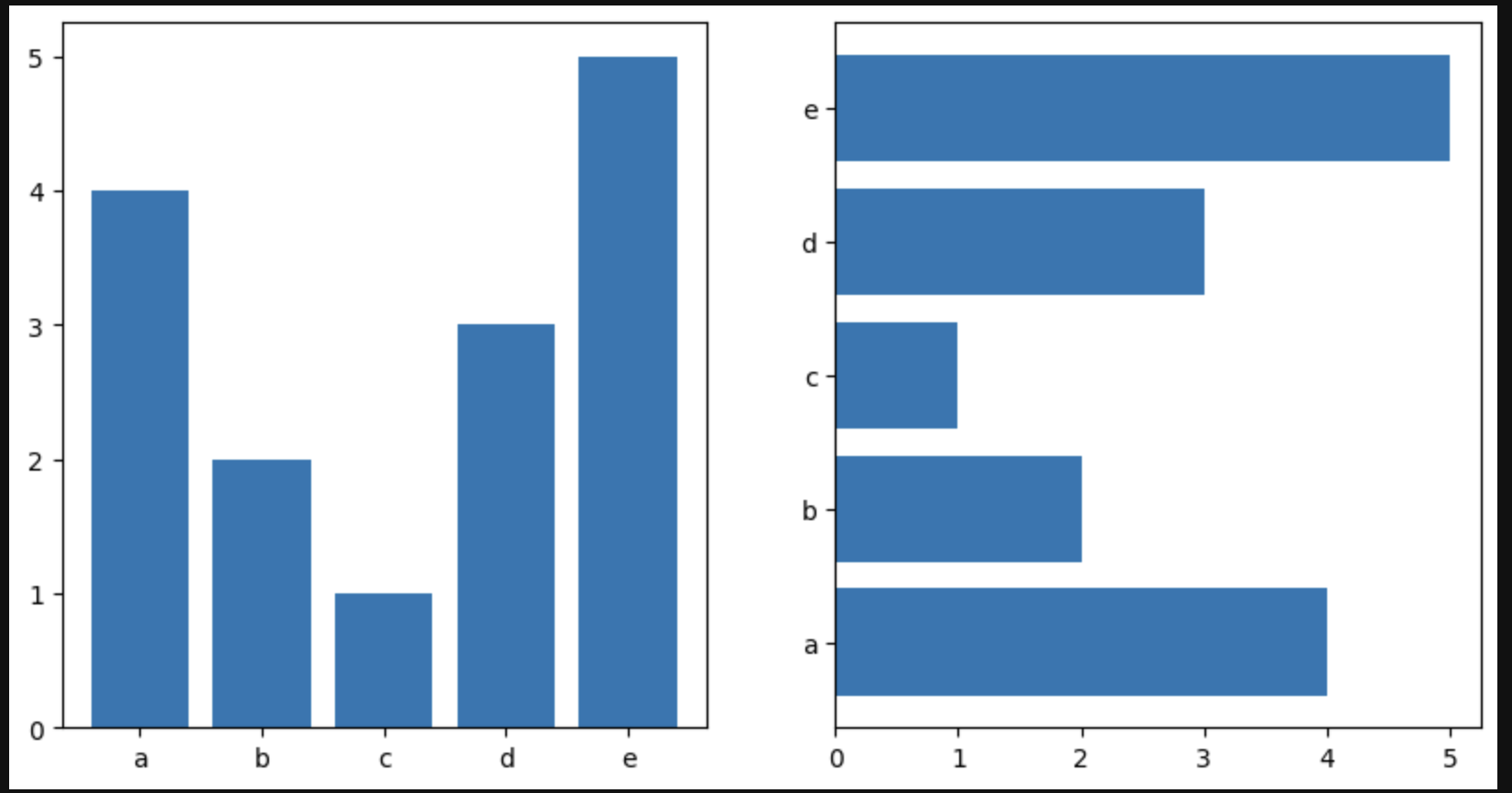
막대그래프입니다. 가장 기본적인 그래프이죠.
수치적인 양을 비교할 때 많이 쓰입니다.
x = list('abcde')
y = np.array([4,2,1,3,5])
ax.bar(x,y)
ax.barh(x,y)
plt.show()를 통해 그릴 수 있습니다.
x,y는 각각 같은 크기의 array를 받습니다.
그리고 그에 상응되는 값을 막대그래프를 통해 띄웁니다.
barh를 사용하면 가로로 막대그래프를 그릴 수도 있겠습니다.
ax.bar(x1,y1)
ax.bar(x1,y2, bottom = y1) # left = y1bottom, left등의 인자를 추가하면 Stacked Barplot 또한 그릴 수 있습니다.
2. Lineplot
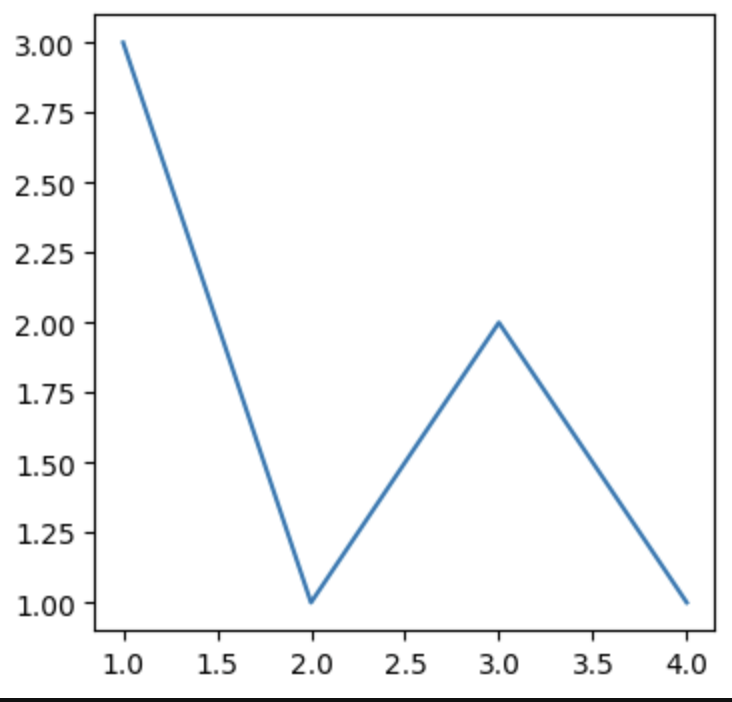
Lineplot입니다.
주로 정확한 값은 아니지만 데이터의 추세가 어떤지를 확인할 때 많이 쓰입니다.
fig, axes = plt.subplots(1, 1, figsize=(4, 4))
x = [1,2,3,4]
y = [3,1,2,1]
axes.plot(x,y)
plt.show()를 통해 그릴 수 있습니다.
유의할 점은, axes.lineplot이 아닌 axes.plot을 통해 그린다는 점입니다.
lineplot은 아주 많은 x와 대응되는 y값을 통해 그리는 경우가 많은데, 이런 경우 noise가 많아 smoothing 기법을 사용하기도 합니다.
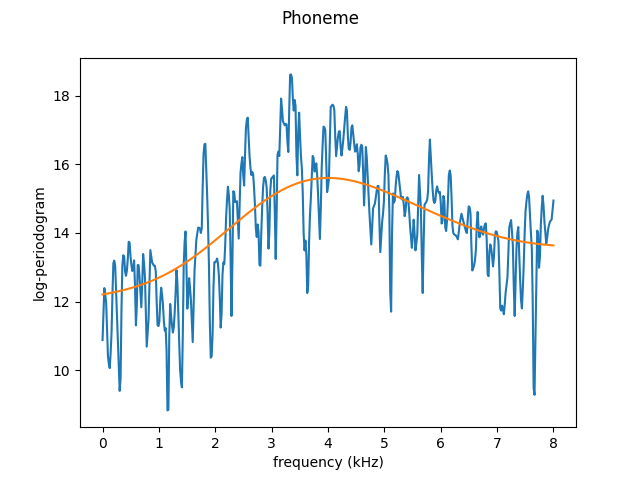
위 사진과 같이 아주 많이 깎아 추세선을 만들어버리기도 하고, 저렇게 자잘하게 나 있는 부분만 깎아 부드럽게 만들 수도 있습니다.
stock_rolling = stock.rolling(window = 20)['google']과 같이 이동평균을 사용하여 smoothing을 할 수도 있겠습니다.
3. Scatter plot
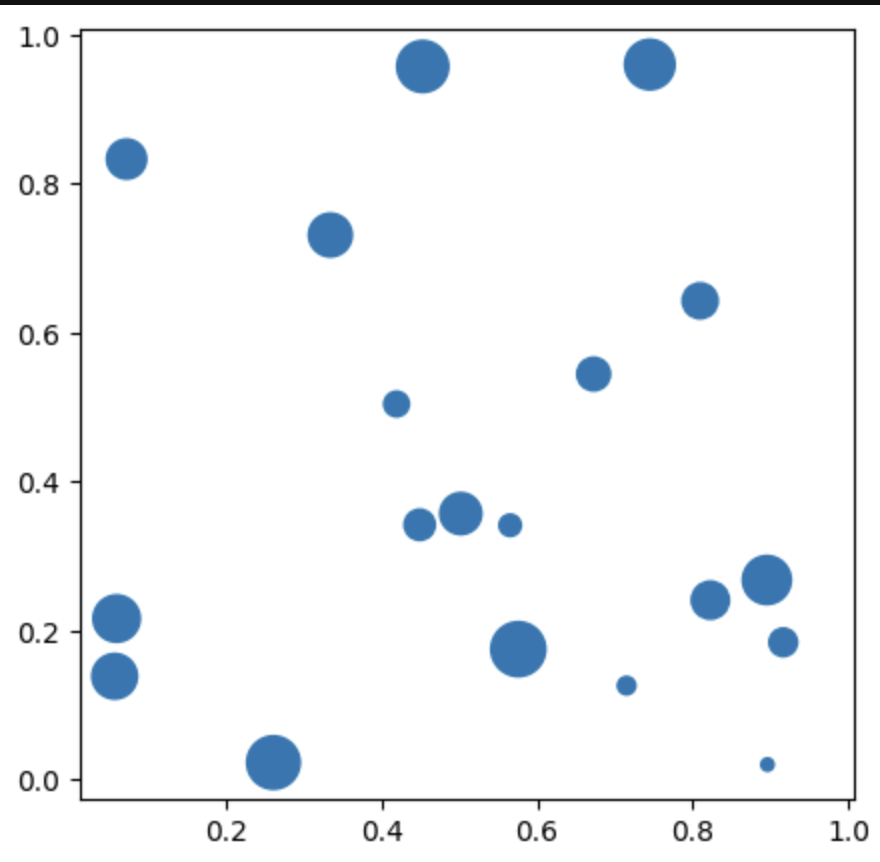
Scatter plot은 산점도를 의미합니다.
Scatter Plot은 각 데이터들이 어떤 분포에 존재하는지를 추정하는 데에 많이 사용됩니다.
fig = plt.figure(figsize=(5, 5))
ax = fig.add_subplot(111)
x = np.random.rand(20)
y = np.random.rand(20)
s = np.arange(20) * 20
ax.scatter(x, y, s = s)
plt.show()위의 두 그래프와는 다르게 x,y와 추가로 s를 입력으로 받습니다.
(x,y)에 어떤 값이 존재하냐 를 의미합니다.
크기는 보통 저렇게 버블의 크기로 표현되지만, 수가 많으면 눈으로 보기 어렵기 때문에 자주 사용되지는 않습니다.
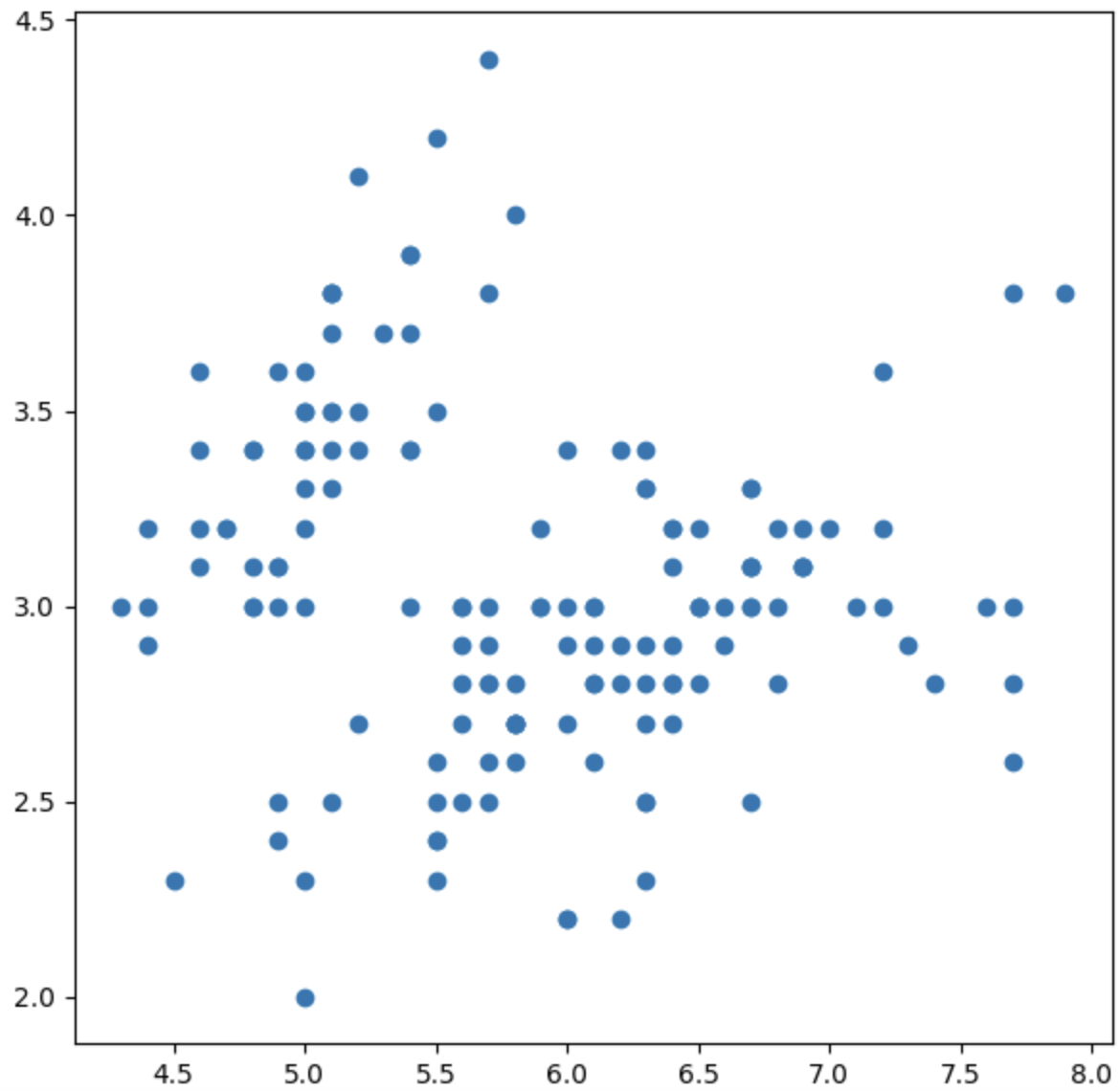
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111)
ax.scatter(x=iris['SepalLengthCm'], y=iris['SepalWidthCm'])
plt.show()이렇게 x,y의 값만을 표시해 bubble의 크기를 고정하여 많이 사용합니다.
scatter plot은 한가지의 데이터만 표현하지 않고, 다양한 군집의 데이터를 표현하여 clustering을 하는 데에 많이 사용합니다.
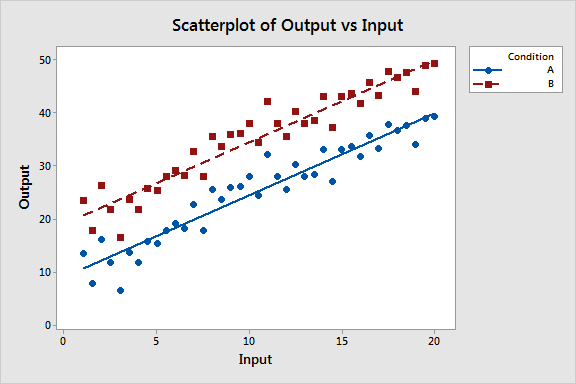
이렇게 말이죠.
이번 글에서는 가장 많이 쓰이는 세가지의 plot에 대해 설명해봤습니다.
이 세가지만 잘 사용해도 본인이 원하는 시각화는 잘 해낼 수 있다고 생각합니다.
다음에 또 작성한다면 이외에도 설명하지 않은 다양한 plot들에 대해 적어보겠습니다.
감사합니다.
