반갑습니다.
저번 글에서는 Matplotlib를 활용해서 데이터 시각화에 많이 쓰이는 그래프 세가지에 대해서 소개했습니다.
이번에는 seaborn을 활용한 더 다양한 시각화 기법에 대해서 소개해보겠습니다.
이번주는 많이 힘든 주가 될 것 같습니다.
해야할 일이 많은데, 해낼 시간이 부족하군요.
썩을 예비군
파이썬을 통한 시각화 라이브러리는 Matplotlib를 많이 사용합니다.
하지만 Matplotlib만큼 사용되는 seaborn이라는 시각화 라이브러리가 있는데요, 이번에는 이걸 사용해보겠습니다.
seaborn이라는 라이브러리는 sns를 별칭으로 널리 사용합니다.
다들 그렇게 쓰니까 따르는게 일관성 유지에 좋겠죠.
Seaborn은 Matplotlib와 어떻게 다르죠?
Seaborn 또한 Matplotlib를 활용한 시각화 패키지이지만, Matplotlib는 좀 더 날것에 가까운 시각화를 보여준다면 Seaborn은 더 미적으로 예쁜 그래프를 쉽게 그릴 수 있게 도와주는 라이브러리입니다.
또한, 직접적으로 데이터를 매치해야하는 Matplotlib과 다르게 Seaborn은 좀 더 직관적이고 쉽게 그래프를 그릴 수 있다는 장점이 있습니다.
직관적이고 쉽게?
이 설명부터가 직관적이지 않군요.
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
student = pd.read_csv('./StudentPerformanceData.csv')
sns.countplot(x='lunch',data=student,
hue='gender',
order=sorted(student['lunch'].unique())
)
라는 코드를 작성해 보겠습니다.
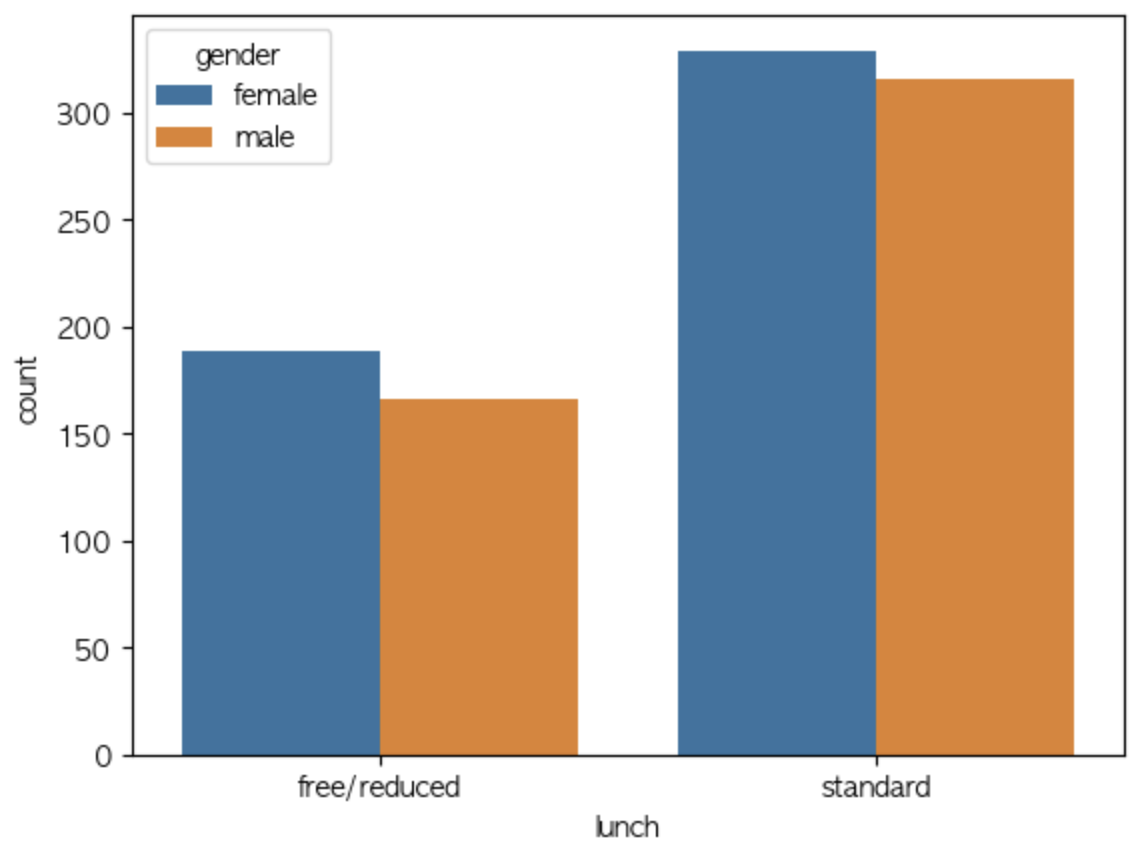
엥 Matplotlib이랑 별 다를거 없는거같은데요
라고 하시면 하수입니다.
Matplotlib에서 저걸 구현하려면 ax를 지정하고, 남자 barplot과 여자 barplot을 각각 x좌표와 너비를 계산해서 살짝 왼쪽, 살짝 오른쪽으로 좌표를 놔줘야하고 x와 y값을 각각 인덱스와 값으로 지정해줘야 하거든요.
근데 seaborn을 활용하니 hue = 'race'를 통해 남녀 구별을 하면서 그래프를 각각에 맞는 barplot으로 변경해줬군요.
또 x에 컬럼명을, data에 student만 넣어준 것도 보입니다.
아~ 요래서 직관적이고 쉽다고 했구나
ㅎㅎ
그럼 제가 저번 글에서 설명하지 못한 그래프들을 마저 설명해보겠습니다.
1. Boxplot
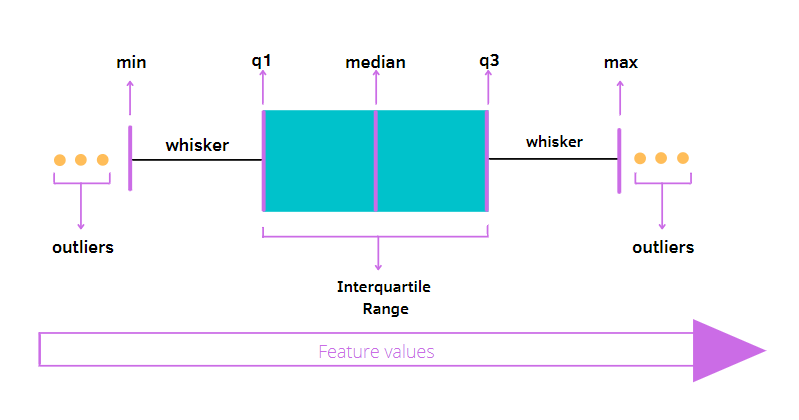
Boxplot이란, 중간값과 최대 최소값, 그리고 2사분위수와 3사분위수를 표현할 수 있는 그래프입니다.
fig, ax = plt.subplots(1,1, figsize=(10, 5))
sns.boxplot(x='parental level of education',
y='math score',
data = student,
order = sorted(student['parental level of education'].unique()),
color = 'skyblue'
ax = ax)
plt.show()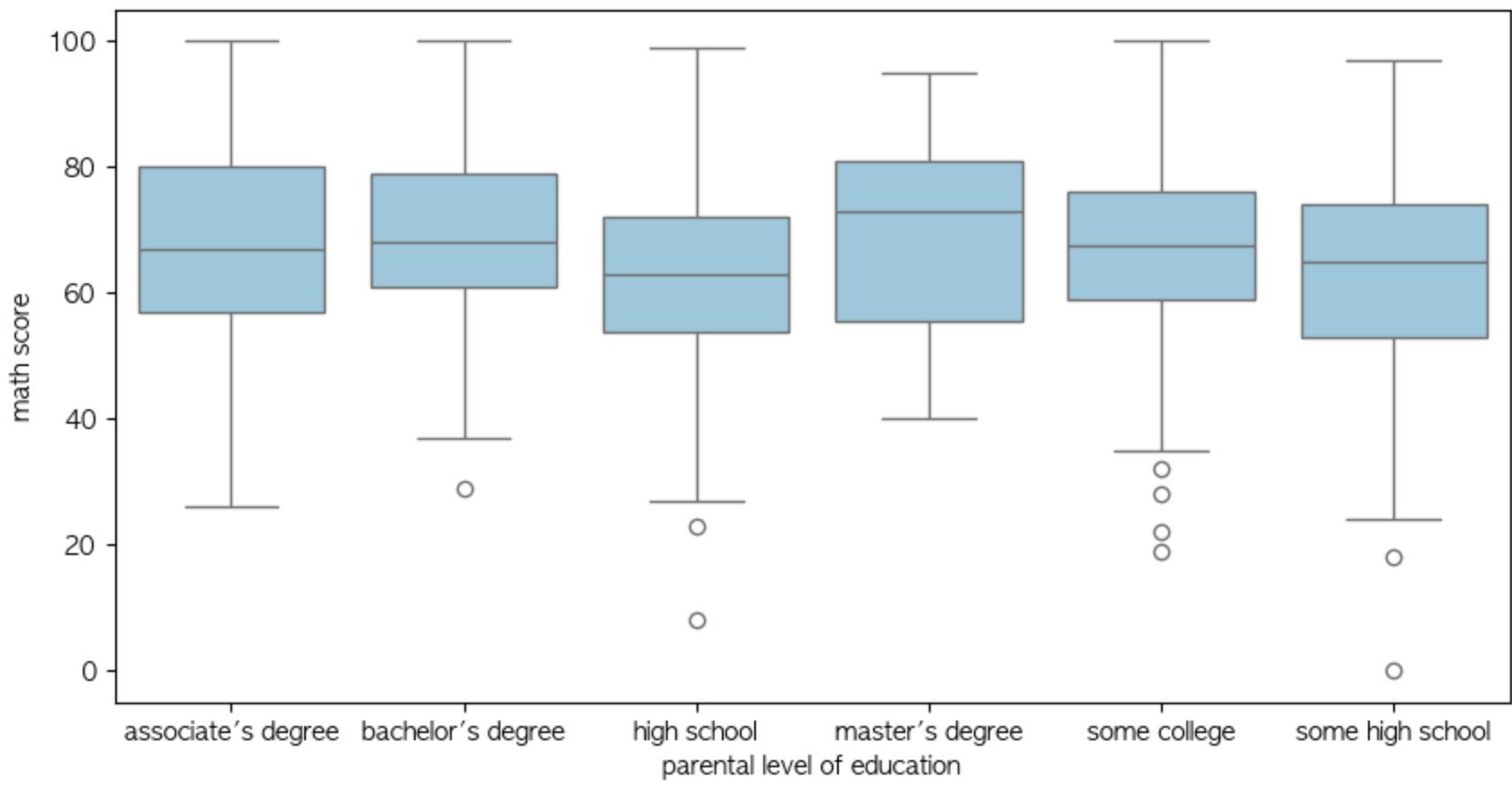
sns.boxplot을 통해 그릴 수 있습니다.
order에 x축 컬럼들을 어떤 순서로 할건지를 리스트로 주면 그에 맞게 x축 컬럼들의 순서를 바꿀 수 있습니다.
data를 넣고 x,y에 컬럼명을 입력해서 그리는 형태가 정말 좋은 것 같습니다.
boxplot들을 보면 아래나 위에 동글뱅이들이 보이실텐데 이것은 이상치라고 판단한 값들을 표현한 것입니다.
확실히 some high school에서 0점짜리가 한 명 있는데 이상치라 판단할 만 하군요.
그래프의 median의 값에 따라 그래프의 skew를 판단할 수 있습니다.
중앙값의 값이 박스의 아래에 있다면 왼쪽으로, 위에 있다면 오른쪽으로 치우친 분포를 가지고 있겠죠.
2. Violin Plot
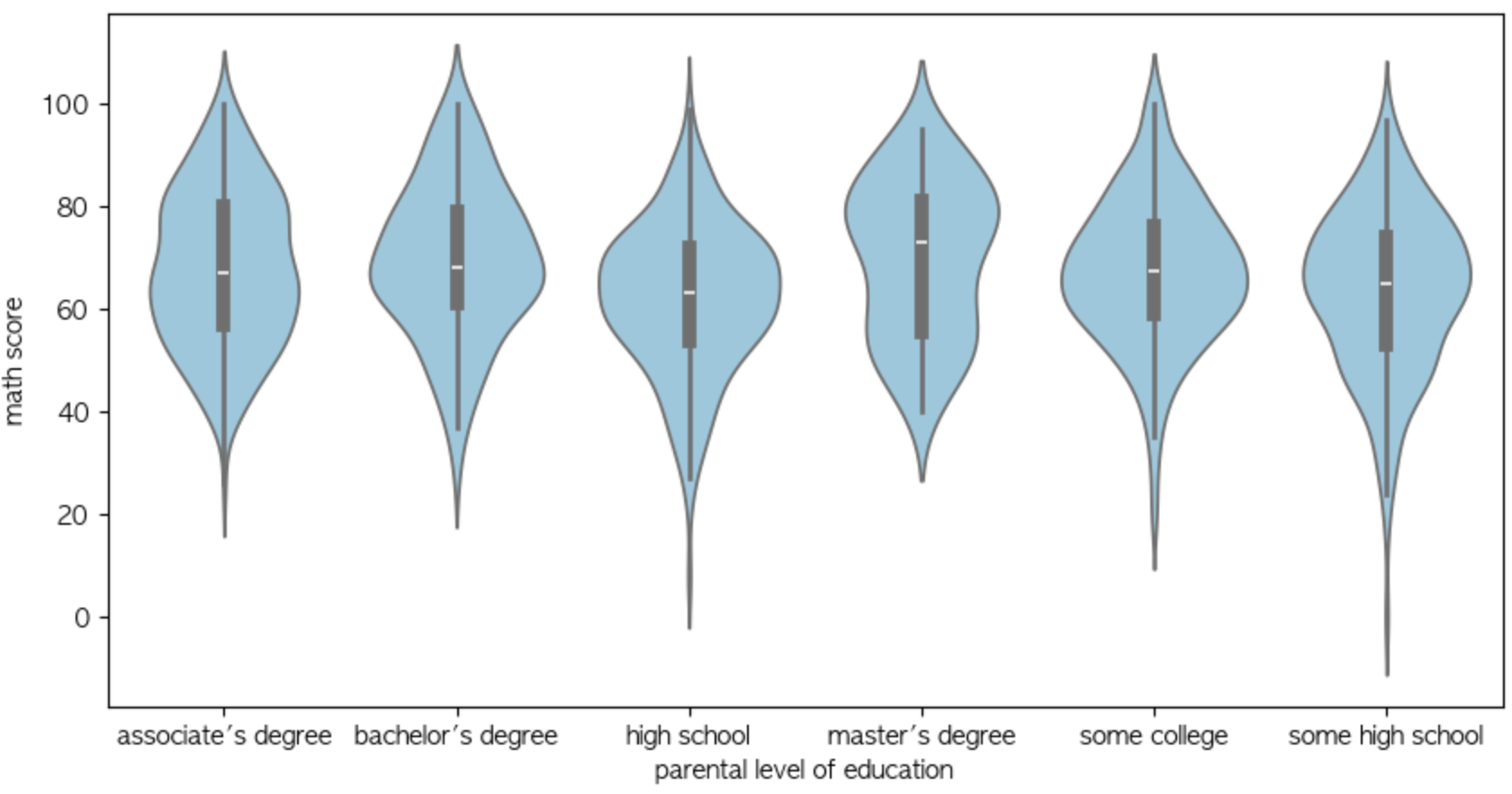
Boxplot은 알멩이가 네모라서 분포를 가늠하기가 좀 어려운 것 같다
에서 나온 Violin Plot입니다.
단순히 왼쪽 오른쪽에 치우친 그래프 뿐만 아니라 봉오리가 두개인 것 까지 표현 할 수 있군요.
fig, ax = plt.subplots(1,1, figsize=(10, 5))
sns.violinplot(x='parental level of education',
y='math score',
data = student,
order = sorted(student['parental level of education'].unique()),
color = 'skyblue'
ax = ax)
plt.show()하지만 그래프가 직관적이진 않는 듯 합니다.
유심히 봐야 이해할 수 있는 그래프들은 실제로 자주 쓰이지는 않는다고 하더군요.
제가 봐도 별로 쓰고싶진 않습니다.
알맞는 상황에 쓰도록 합시다.
3. 밀도 함수들
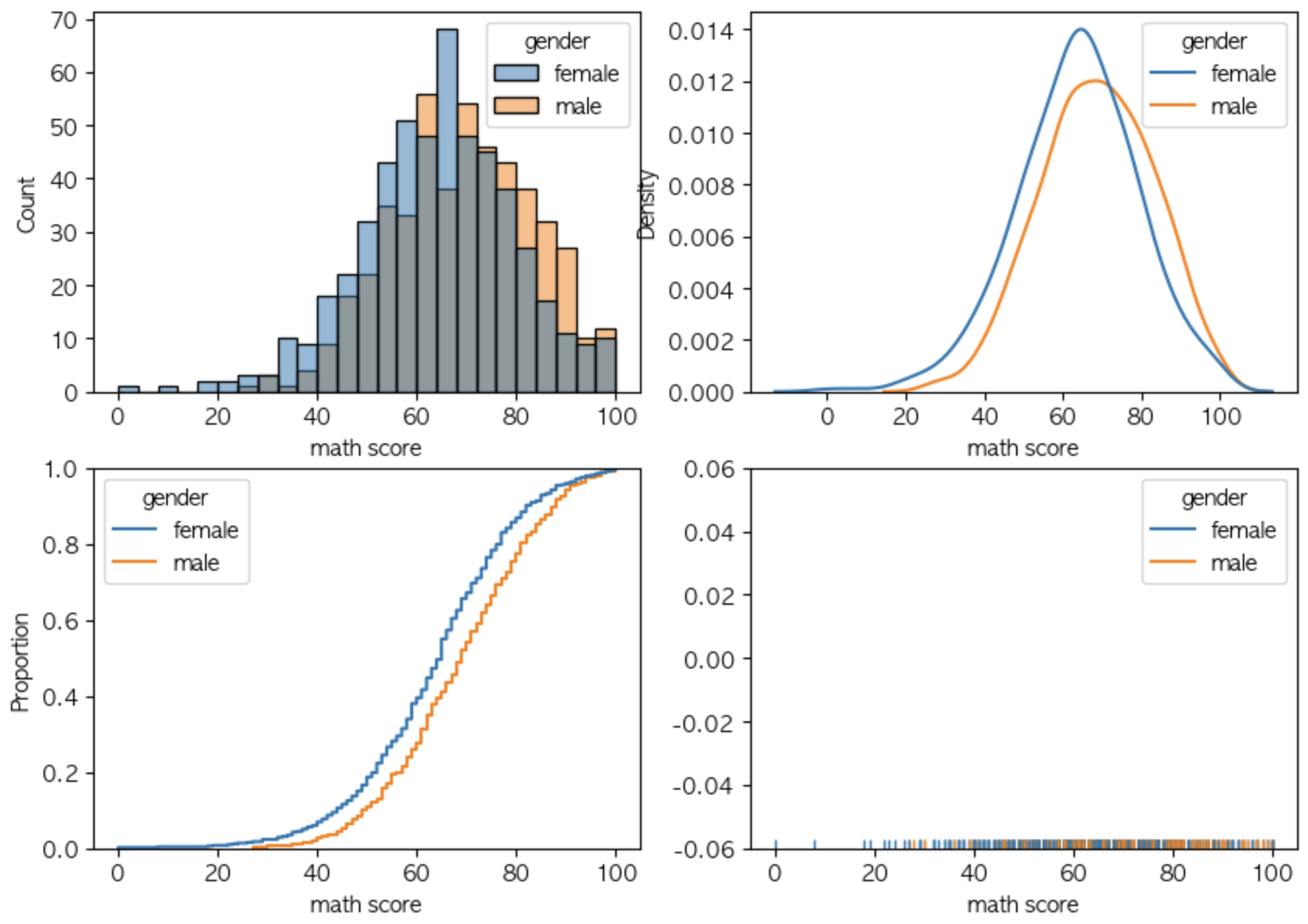
데이터의 분포를 밀도로 나타내는 그래프들입니다.
histogram이나 kdeplot은 다들 익숙하실 듯 싶습니다.
ecdfplot은 경험적 누적 분포 그래프로, 데이터의 순간 기울기를 통해 어느 부분이 데이터가 많은지를 판단 할 수 있습니다.
rugplot은 밀도를 선으로 나타낸 그래프입니다.
선이 빼곡할수록 밀도가 높다고 볼 수 있겠습니다.
fig, axes = plt.subplots(2,2, figsize=(12, 10))
axes = axes.flatten()
sns.histplot(x = 'math score', data=student, ax=axes[0], color = 'skyblue', hue = 'gender', alpha = 0.5)
sns.kdeplot(x = 'math score', data=student, ax=axes[1], color = 'skyblue', hue = 'gender')
sns.ecdfplot(x = 'math score', data=student, ax=axes[2], color = 'skyblue', hue = 'gender')
sns.rugplot(x = 'math score', data=student, ax=axes[3], color = 'skyblue', hue = 'gender')
plt.show()각 그래프들은 전부 비슷한 format으로 그릴 수 있습니다.
4. Heatmap

이런식으로 가로와 세로에 대응하는 값들을 색으로 나타낸 그래프입니다.
Heatmap은 상당히 많이 쓰이는데, 상관계수나 Attention map을 시각화할 때도 쓰입니다.
상관계수란 변수들 사이에 어떠한 상관관계가 있냐를 수치로 나타낸 것입니다.
피어슨, 스피어만, 켄달-타우 상관계수 세가지가 있는데, 제가 예전에 정리해 놓은 글을 올려보겠습니다.
pearson : 상관계수는 -1~1의 값을 가지며 -1이나 1에 가까울수록 연관성이 높다. 0에 가까울수록 연관성은 없다.
아래의 두 상관계수는 비모수적 상관계수이다(모집단의 특정 분포를 가정하지 않고 접근하는 방법. 비모수적 방법은 정규성 검정에서 정규분포를 따르지 않거나 표본의 개수가 10개 미만일 때 사용)
kendall : 켄달 타우 상관계수는 두 변수들 간의 순위를 비교하여 연관성을 계산한다.
켄달 타우는 concordant pair의 수를 이용하여 p를 구한다.
( )
concordant pair : 예를 들어 킬와 몸무게에 대한 상관계수를 알 때, A가 키가 크고 몸무게도 많이 나가면 concordant pair, A가 키가 크지만 B의 몸무게가 더 나간다고 할 때는 non concordant pair이다.
켄달 타우는 샘플 사이즈가 작거나 데이터의 동률이 많을 때 유용하다.
spearman : 순위상관계수는 데이터의 값이 아니라 순위에 의존한다.
스피어만 상관계수는 값에 순위를 매겨 그 순위에 대해 상관계수를 구하는 것이다.
연속형 변수가 아닌 순서형인 경우에도 상관계수를 구할 수 있다.
스피어만은 데이터 내 편차와 에러에 민감하며 일반적으로 켄달 상관계수보다 높은값을 가진다.
상관계수는 pandas의 자체 모듈을 통해 쉽게 구할 수 있습니다.
df_corr_s = df_all[['행복지수 순위','연 근로시간', '휴일 수']].corr(method='spearman')
# 두 변수의 순위 관계에 대해서 사용
sns.heatmap(df_corr_s)method 변수에 'spearman', 'kendal', 'pearson'을 넣어서 사용하시면 되겠습니다.
'
'
'
이로서 시각화에서 쓰일 만한 그래프들은 많이 알아본 듯 싶습니다.
하지만 제가 소개한 것 외에도 아주 다양한 그래프들이 많습니다.
그런 그래프들은 블룸버그와 같은 아주 유명한 데이터 분석 글들을 많이 보시면서 배우시고 감각을 익히시는게 큰 도움이 될 것 같습니다.
저도 영어를 싫어해서 잘 찾아보지 않지만, 큰 배움들은 해외에 많은 것 같습니다.
더 늙기 전에 외국어를 체득하도록 노력해야겠습니다.

선생님 안녕하세요, 도움 많이 얻고 있습니다. 감사합니다.