반갑습니다
Pruning에 대해서 좀 자세히 알아가보겠습니다.
Pruning은 ML/AI를 하면서 좀 자주 접했던 용어인데, 정확한 동작 원리는 잘 몰랐던 것 같습니다.
이번 기회에 정리하면서 글을 작성해봅니다.
시작 !!
Pruning
Pruning(가지치기)란, 신경망 모델에서 노드(뉴런)나 연결(시냅스)를 제거하여 모델의 크기와 계산 비용을 줄이는 기법을 의미합니다.
Pruning은 다음과 같은 장점을 갖습니다.
1. 메모리 사용을 줄인다. (파라미터를 제거하기 때문)
2. 연산 속도를 가속한다. (연산량이 적어지기 때문)
뉴런이나 시냅스를 그럼 무슨 기준으로 제거할까요
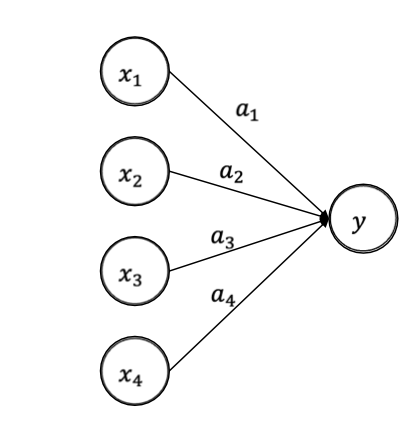
이런 모델이 있다고 생각해봅시다.
가 됩니다.
이때, weight a = [100, 100, 0.01, 100] 이라면 ..
는 0.01과 곱해지기에 왠만한 값들을 넣어도 y의 결과값에 큰 변화를 주지 않습니다.
간단하게 말하면 는 결과에 그렇게 큰 영향을 끼치지 못한다는 의미입니다.
그럼 a_3같은 애들은 계산에서 그냥 빼버리도록 하자
그것이 Pruning의 기본 개념입니다.
이게 실제로 효과가 있을까요?
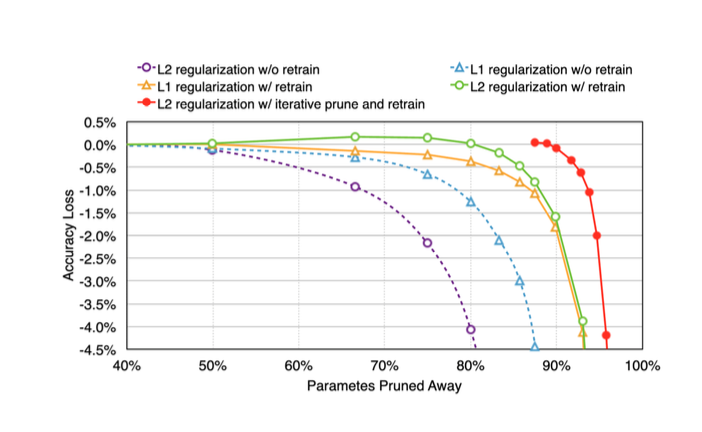
위 그림을 보면, 대부분의 방법론들이 약 70%까지 Pruning을 진행했을 때 성능의 하락이 없음을 알 수 있습니다.
50%~60% Pruning을 진행할 때 오히려 소폭의 성능 향상이 있는 경우도 관찰되는군요.
Pruning이 Dropout과 비슷하다보니 Dropout처럼 일반화성능을 향상시켜 성능이 올라간 듯 합니다.
Pruning의 방법들
Pruning은 크게 4가지 관점으로 방법을 분류할 수 있습니다.
1. Structure
Pruning 단위의 Granularity(세분성)에 따른 구분
Structure 관점에서 Pruning은 두가지로 분류됩니다.
1. Unstructured Pruning
파라미터 하나하나 단위로 값을 0으로 변경합니다.
모델 구조에 변경이 없습니다.
Unstructured Pruning은 구현은 쉽지만.. (기준치 미만인 파라미터는 0으로 바꾸면 되기에) Pruning을 진행한다고 속도가 빨라지진 않습니다.
0이라는 파라미터도 결국 곱해지는 연산에 포함되기 때문이죠.
추가적인 조치를 취해야 속도까지 빨라질 수 있습니다.
2. Structured Pruning
레이어 단위나 채널 단위처럼, 특정 구조 단위로 통째로 제거합니다.
모델의 구조에 변경이 생깁니다.
Structured Pruning은 의미가 없다고 판단된 특정 채널, 구조, 레이어를 날려버리기에 연산 속도가 바로 빨라진다는 장점이 있습니다.
하지만 모델의 구조가 바뀌기에 모델을 수정해야할 수도 있다는 단점이 있습니다.
2. Scoring
Pruning할 파라미터를 선정하는 방법에 따른 구분
Pruning할 파라미터 선정
덜 중요한 파라미터/레이어가 Pruning의 대상이 됩니다.
중요도를 어떻게 계산할까요
(1) 개별 파라미터 하나하나에 대해서 계산할 수 있고, (2) Layer별로 계산할 수도 있습니다.
-
[[1,2,3], [1,10,10]] 이라는 2차원 파라미터가 있을 때,
파라미터 별로 절대값이 낮은 파라미터들을 Pruning한다면
[[0,2,3], [0,10,10]] 이 될 수 있습니다. -
반면에 레이어 별로 Pruning한다면
각 레이어의 L2 거리를 계산합니다.
1번 레이어의 L2 거리는
2번 레이어의 L2 거리는
이니 1번 레이어가 날라가게 되겠습니다.
중요도에 대한 기준을 정했다면, 어디서 얼마나 Pruning할 것인지를 정합니다.
방법은 (1) Global Pruning, (2) Local Pruning이 있습니다.
1.Global Pruning
모델 전체에서 Pruning을 진행합니다.
전체 모델의 파라미터 중 50%를 Pruning 하고자 한다면, 전체 모델의 파라미터에서 50% Pruning을 진행합니다.
이 방법은 중요한 레이어가 보존된다는 장점이 있지만, 파라미터들을 하나하나 비교하기에 계산량이 많습니다.
2. Local Pruning
특정 단위 별로 Pruning을 진행합니다.
각 레이어마다 동일하게 n개씩 Pruning 하겠다는 의미입니다.
이 방법은 특정 레이어에 Pruning이 편중되지 않는다는 장점이 있지만, 중요한 레이어가 과도하게 Pruning될 수 있다는 단점이 있습니다.
선정된 기준에 따라 몇몇 파라미터들이 Pruning이 진행될 수도, 안될수도 있습니다.
뭐가 더 좋은지는 직접 해봐야 알 듯 싶습니다.
3. Scheduling
Pruning 및 Fine-Tuning을 언제, 얼마나 할 것인지에 따른 구분
Pruning을 언제 할것인지를 정합니다.
One-shot Pruning(한번에 Pruning을 진행)과 Recursive Pruning(Pruning을 조금씩 여러번 진행)이 있습니다.
보통 파라미터의 80~90%를 날리는 경우, 한번에 많은 파라미터를 날리게 되면 성능 손실이 크기에 큰 모델에서는 여러번 나눠서 진행하는 경우가 많습니다.
살짝 깎고 Fine-Tuning, 또 살짝 깎고 Fine-Tuning ... 반복하는 것이지요.
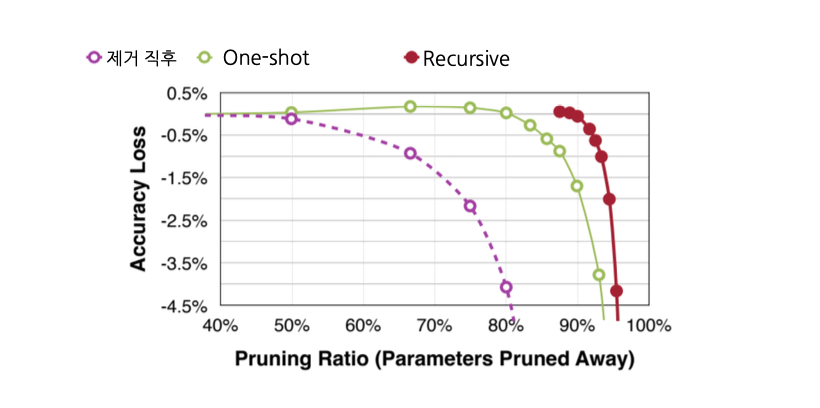
위 이미지를 봐도 Recursive Pruning이 성능을 보호하는 범위 내에서 더 많은 파라미터를 없앨 수 있음을 확인할 수 있습니다.
하지만 시간이 오래 걸린다는 단점이 있지요. (Fine Tuning을 여러번 하기 때문)
4. Initialization
재학습 및 Fine-Tuning할 시 파라미터 초기화를 하는 방법에 따른 구분
Pruning 직후에는 학습된 모델 파라미터 중 일부가 잘려나간 상태입니다.
Fine-Tuning을 통해 파라미터를 다듬는 작업이 필요하죠.
이 때, Initialization을 할 것인지 안할 것인지를 정합니다.
1. Weight-Preserving(기본)
Pruning 직후 상태 그대로 이어서 Fine-Tuning을 진행합니다.
학습/수렴이 빠르다는 장점을 갖지만, 성능이 불안정해질 수 있습니다.
2. Weight-Reinitializing(Rewind)
Pruning한 뒤 남은 파라미터들을 랜덤 값으로 재초기화 후 재학습 진행합니다.
성능이 안정적으로 좋아진다는 장점을 갖지만, 긴 시간 재학습이 필요합니다.
How to Pruning
위의 4가지 관점에서 방법들을 각각 선택하고 Pruning을 진행합니다.
- Structured: Unstructured pruning
- Scoring:
• 절대값을 기준으로 Pruning
• Global pruning (모델 전체에서 중요도계산 및 pruning) - Scheduling: Recursive 방식 활용 (조금씩 Pruning)
- Initialization: Rewind 방식 활용 (Pruning 할때마다 가중치 초기화)
예시를 보니까 흐름이 확 보이는군요.
이렇게 Pruning 작전을 잘 짜서 수행하면 좋은 결과를 얻을 수 있겠습니다.
'
'
'
여기까지는 Pruning에 대해 전반적으로 살펴봤습니다.
이 다음에는 디테일을 챙기고자 조금 더 깊게 살펴보도록 하겠습니다.
How to handle 0?
Pruning을 진행하게 되면.. 결국 대부분의 파라미터가 0이 되기에 가중치 행렬은 Sparse Matrix에 가까워지게 됩니다.
하지만 0 또한 계산에는 결국 포함되기에 파라미터가 적어지더라도 연산 속도에 변화는 없지요.
이런 부분을 어떻게 해결할 수 있을까요?
1. Matrix의 표현법 변경
파라미터 각각의 숫자 좌표를 저장합니다.
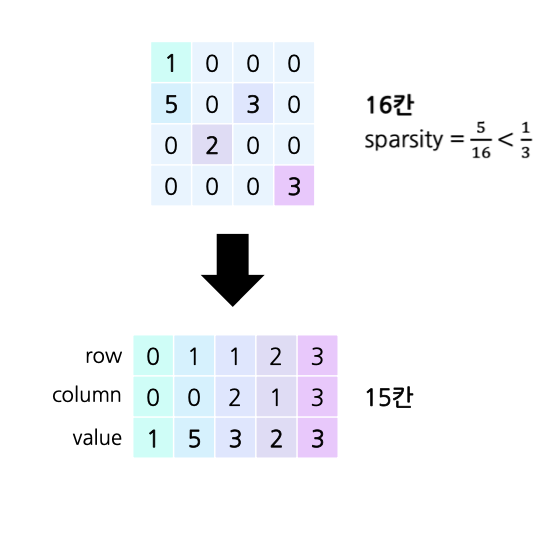
파라미터 각각의 요소를 (row,column,value)의 형태로 저장합니다.
이렇게 하면 한 값을 저장하는 데에 3개의 공간을 차지하게 돼 좋지 않아보이지만, 대부분의 값이 0으로 채워져 있는 Pruned Matrix에는 오히려 효율적일 수 있습니다.
하나의 값에 3개의 공간을 차지하니 전체 Matrix의 값이 1/3 이하로 존재할 때 기존의 공간보다 효율적입니다.
또, 0이 아닌 부분만을 찾아 계산하기에 0의 계산을 피할 수 있습니다.
2. 전용 하드웨어 사용
0의 계산을 피할 수 있도록 제작된 하드웨어를 사용합니다.
가중치 Matrix의 Sparse한 정도가 중간정도라면 표현법을 바꾸는 것이 효율적이지 않을 수 있습니다.
이런 경우, 곱셈 수행 전에 스캔을 통해 0의 위치를 파악하고 해당 위치를 건너뛰는 계산을 할 수 있는 하드웨어를 사용하는 방법을 시도해볼 수 있습니다.
NVIDIA의 Tensor Core가 해당 역할을 수행할 수 있다는군요.
이 경우 0의 위치를 찾는 데에 약간의 overhead가 발생하지만, 기존 연산보다 더 효율적으로 속도를 절감할 수 있습니다.
Sensitivity Analysis
각 레이어의 Pruning 비율을 설정하는 중요도를 측정하는 방법입니다.
위에서 소개해드린 Pruning ratio는 레이어, 파라미터 별로 얼만큼의 파라미터를 제거할 것인지를 정한다고 말씀드렸죠.
사실 더 합리적인 방법은 당연히 레이어마다 Pruning의 비율을 다르게 선정하는 것이겠습니다.
민감도가 높은 부분은 덜 Pruning하고, 낮은 부분은 더 Pruning 하는것이지요.
이를 위해 민감도를 측정하는 것이 Sensitivity Analysis라고 합니다.
방법은 꽤나 무식한데
그냥 레이어를 전부 골라서 레이어마다 Pruning을 진행하고 Fine-Tuning 후 성능을 측정하여 감소폭이 큰 레이어를 찾는 방법을 사용합니다.
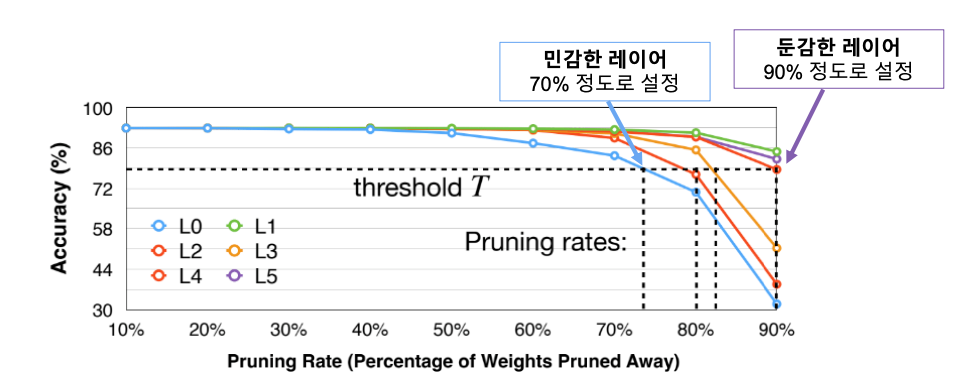
장점으로는 최적의 Pruning 비율을 찾아 모델에게 적용할 수 있다는 점입니다.
하지만 시간이 아주 많이 소요되겠죠.
Hyperparameter Search 중 Grid Search와 유사합니다.
Examples in Sensitivity Analysis
CNN 레이어를 한번 살펴보겠습니다.

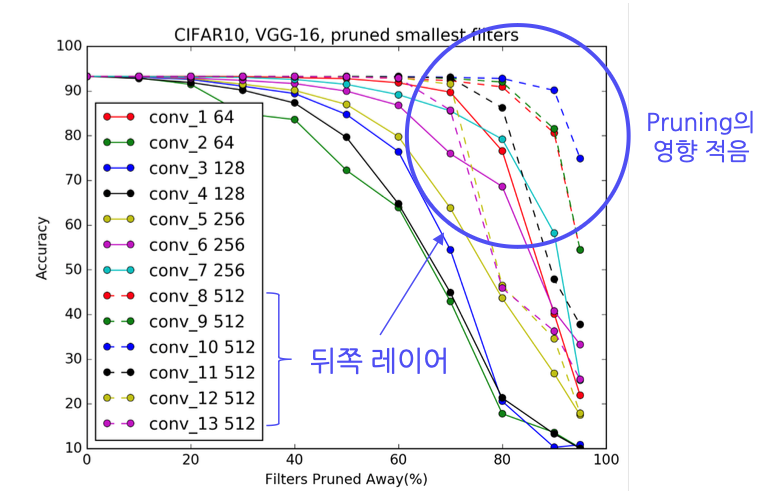
Li, Hao, et al. "Pruning filters for efficient convnets." arXiv preprint arXiv:1608.08710 (2016).
위 논문에 의하면 CNN 레이어는 앞쪽 레이어에서는 Pruning의 영향이 컸고 뒤쪽 Layer로 갈수록 Pruning의 영향이 작았다고 소개합니다.
앞쪽 레이어는 세부적인 형태를 살펴보기에 중요한 반면, 뒤쪽 레이어는 비슷한 형태를 띄고 있어 비교적 파라미터를 적게 필요로하는듯 합니다.
이번엔 BERT를 살펴봅시다.
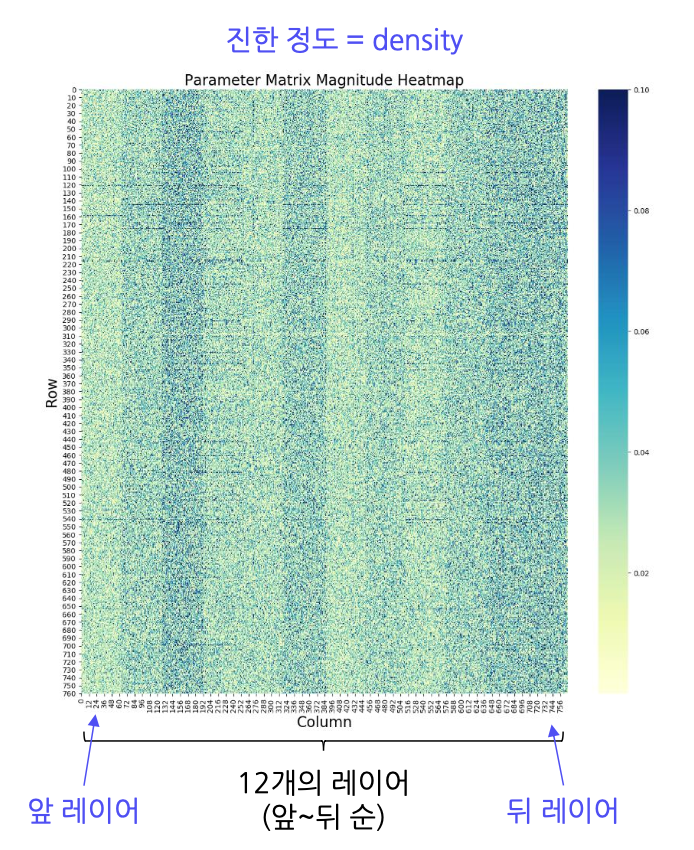
Gordon, Mitchell A., Kevin Duh, and Nicholas Andrews. "Compressing bert: Studying the effects of weight pruning on transfer learning." arXiv preprint arXiv:2002.08307 (2020)
BERT는 CNN과 다르게 중요한 파라미터들이 고루 퍼져있음을 알 수 있습니다.
BERT계열 모델들은 Global Pruning을 진행하면 성능 보존이 어려울 듯 합니다.
각 모델의 특성을 따라 Pruning을 잘 사용하는 것이 중요하겠습니다.
'
'
'
이로서 Pruning에 대한 소개를 마칩니다.
아무래도 Pruning은 지속적인 학습이 필요하다 보니 최근 LLM에서는 많이 사용되지 않는 기법인 듯 합니다.
다음 글에서는 Knowledge Distilation에 대해서 글을 작성해보겠습니다.
감사합니다 !
