반갑습니다.
저번 Attention 포스트에 이어서 Transformer와 Self-Attention에 대해 설명해보겠습니다.
저번 포스트에서 RNN 기반의 모델의 세가지 문제점에 대해서 설명했었죠.
1. 앞단의 내용을 제대로 담지 못한다. (제일 끝단만 봄)
2. 순차적으로 사용하기에 병렬화가 어렵다. (느리다)
3. RNN의 vanishig/exploding gradient 문제
1번의 문제점은 Attention으로 해결했지만 2,3번의 문제들은 여전히 존재했습니다.
그래서 고안한 모델이 Transformer입니다.
Transformer에서는 RNN 구조를 아예 빼버리고 Attention만으로 만든 번역 모델입니다.
특히, self-attention이라는 기술을 통해 자잘한 다른 문제마저 해결한 레전드 모델이죠.
하지만 그만큼 정교하고 어려운 개념들이 많은 모델입니다.
이 글을 작성하기 위해 아주 많은 영상과 글을 봤지만, 아직도 50프로밖에 설명하지 못할 것 같습니다.
Transformer, 왜 잘되나요?
일단 RNN 구조를 아예 사용하지 않음으로서 RNN의 고질적인 문제들(vanishing, exploding gradients)을 해결했습니다.
RNN을 빼니 순차적 계산 또한 안하니까 모델을 병렬적으로 연산할 수 있게 함으로써 학습속도를 끌어올렸습니다.
그리고 self-attention을 통해 기존 attention의 문제도 해결하였죠.
기존 Attention의 문제?
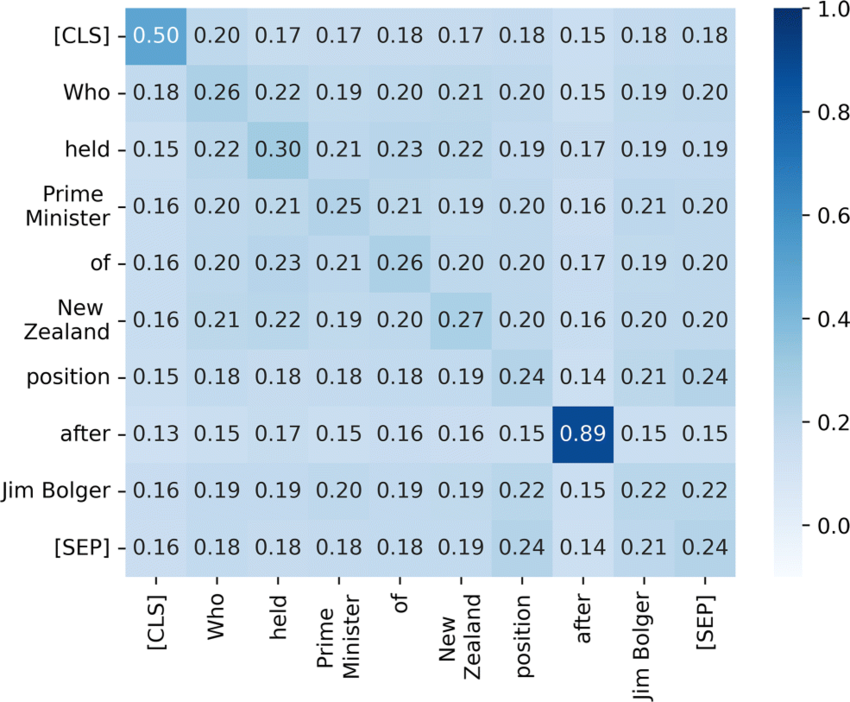
Attention은 한 문제가 있었는데, 바로 동음이의어입니다.
일반적인 Attention은 출력 단어를 쿼리로 키 간의 dot-product를 수행하는데, 동음이의어가 있으면 이게 무슨 의미인지를 알지 못합니다.
예를 들어서, "내 눈으로 본 바깥 풍경은 온통 눈으로 덮여있었다"
라는 단어가 있다고 했을때, output으로 "눈으로" 라는 단어가 나왔고, 이를 query로 두고 문장들과의 attention을 수행하면 앞의 "눈으로"와 뒤의 "눈으로"가 같은 attention value가 나온다는거죠.
이거를 어떻게 고치냐
self-attention을 통해 해결할 수 있습니다.
Self-attention은 어떻게 하나요?
self-attention 은 간단히 말해 본인 또한 attention에 포함시킨다는 의미입니다.
기존의 attention에서는 query를 하나 잡고 attention을 돌렸다면, 이번에는 query = key 로 같은 dimension으로 돌리는겁니다.
word = (10, 100)라 하면
Wq = nn.Linear(100, 10)
Wk = nn.Linear(100, 10)
Wv.shape = (100, d_model)
로 dense layer을 잡아보겠습니다.
그러면 word의 shape이 (10,100) 이니까 한 단어를 100개의 숫자로 표현한다고 볼 수 있겠죠.
그럼 input으로 넣고 계산해보면
Wq(word).shape = (10,10)
Wq(word).shape = (10,10)
를 하면 (10,10)짜리 Attention map이 나옵니다. Attention에서는 Attention score가 나왔지만, self-attention에서는 attention map이 나오는겁니다.
그럼, 이 출력에 softmax를 씌우고 Wv를 곱해주면 우리가 원하는 문맥을 잘 파악하는 벡터를 얻을 수 있는거죠.
softmax를 통과하면 각 단어들(자신포함)이 서로 어떤 영향을 끼치는지를 알 수 있고, Wv를 곱함으로써 다시 우리의 단어 차원으로 사영을 시키는겁니다.
이게 왜 좋냐
1. 자기 자신과 주변 단어들을 통해 정보를 섞기때문에 문맥을 더 잘 파악할 수 있습니다.
2. 저 구조에서 nn.Linear(100,10)을 nn.Linear(100, 2)로 바꾸고 5개를 만든 뒤, 5개를 concat해버리면 더 복잡하고 문맥을 잘 읽게 할 수 있습니다.(multi-head-attention이라고 합니다)
다만 자잘한 문제점이 있습니다.
똑똑한 사람들은 눈치채실 수도 있지만 각 단어들의 순서를 바꿔버려도 결과값이 차이가 없습니다. 1번 단어를 4번에 옮긴다고 해도 softmax를 취했을 때 1번 확률이 4번에 가는 것 뿐입니다.
또, sequencial한 모델이 아니기 때문에 입력이 한꺼번에 들어갑니다.
정답이 I love you 라면 I Love you가 그냥 다 들어가버리기 때문에 정답을 알고 맞추기를 하는거죠. 이건 디코더쪽에서 설명해보겠습니다.
Transformer의 구조 사진을 보겠습니다.
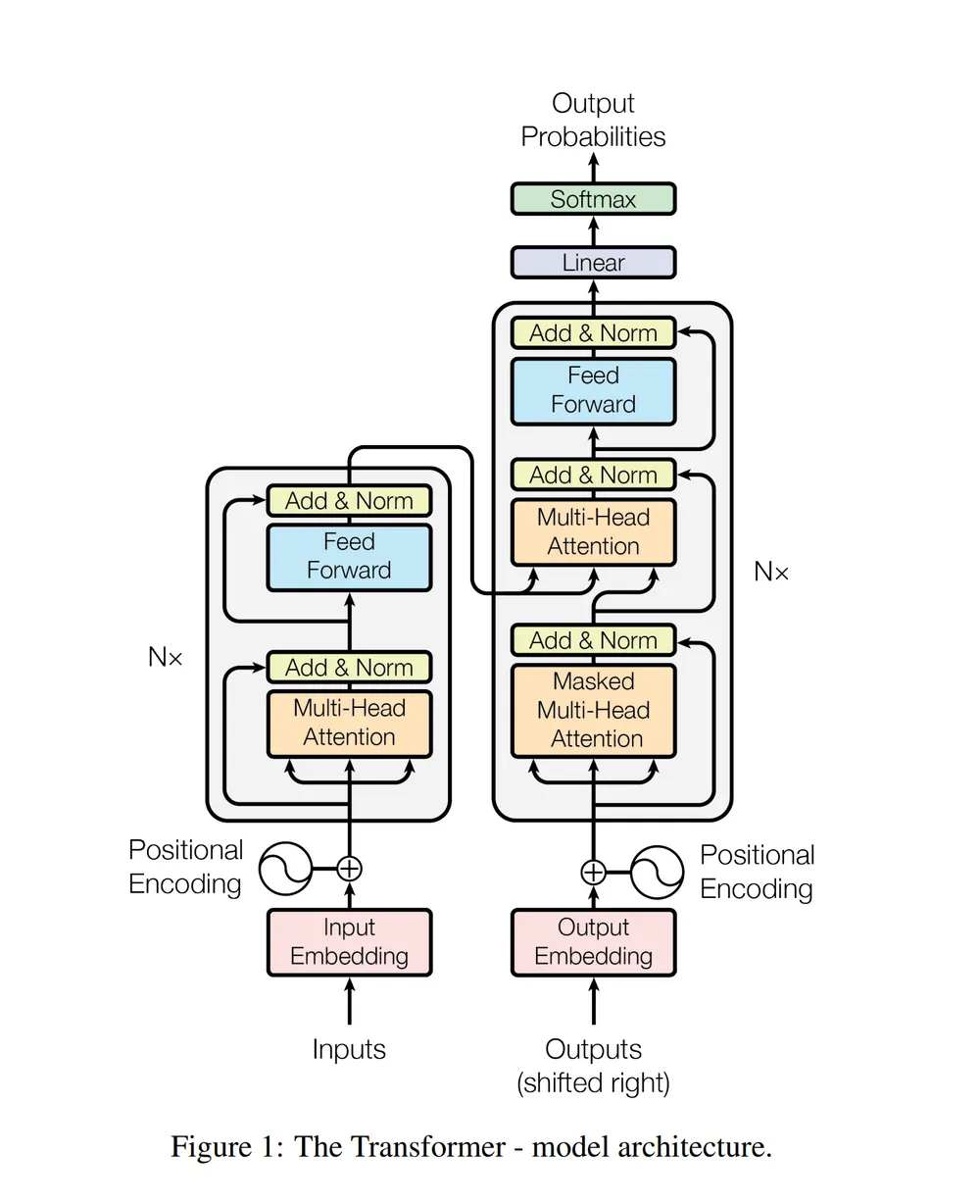
아래를 봐보면 input Embedding 위에 좌우반전된 태극문양이 있습니다. Positional Encoding
간단히 말하면 그냥 input을 해버리면 위치를 알 수 없으니 위치를 알 수 있도록 어떤 상수를 더하는겁니다.
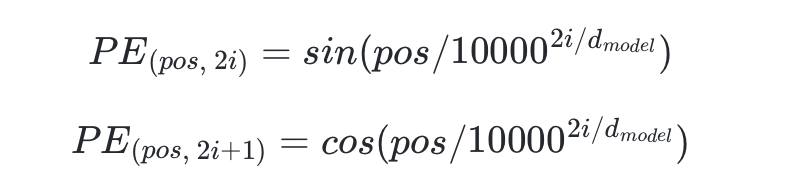
이 식이 Transforemr에서 사용된 positional Encoding 식입니다.
Positional Encoding은 학습한 모델을 쓰기도 하고 다양하다고 하는데, 저는 저거만 배웠습니다.
pos와 i가 눈에 보이는데, attention map에서의 (pos,i)위치의 값을 의미합니다.
input = input + pos_encoding 와 같이 더해서 구현할 수 있습니다.
이로서 위치 문제를 해결합니다.
그 위에 Multi-head attention
아까 말했던 self-attention 과정을 수행하는 nn.linear 블록을 잘게 나눠서 학습시키고 합치는겁니다.
이로서 많은 head들이 각각의 문맥을 학습한다고 하는데 솔직히 저는 모르겠습니다. 어차피 linear로 만들면 가중치 다 비슷하게 초기화 돼서 비슷한 문맥만 볼거같은데.....
각각의 head들이 왜 기특하게도 여러 문맥을 보도록 형성되는지 아시는분은 알려주시면 감사하겠습니다(제발)
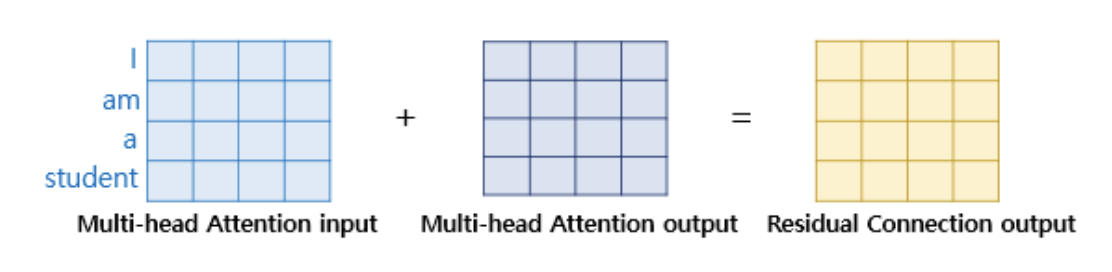
각 블록마다 보시면 어텐션 안하고 고속도로로 Add & Norm에 들어가는 녀석들이 있는데, Residual connection이라고 합니다.
Multi-head Attention block은 출력이 인풋과 shape가 똑같습니다. 이를 이용해 그냥 output과 더해버리는거죠.
왜 이렇게 하냐
1. Vanishing gradient 문제 해결
2. 과거 정보 유지(빠른 수렴)
3. 모델의 표현력 상승
이라고 합니다. 전체적으로 안정화를 시키는 느낌입니다.
Add 는 설명했으니 Norm을 설명해야겠죠.
Norm은 Layer Normalization입니다. 이름에서 알 수 있듯이 정규화입니다. 각 층의 출력의 분포를 일정하게 만들어서 학습을 잘 되게 하는것이죠.
출처 : 딥러닝을 이용한 자연어처리 입문(위키독스)
두 벡터를 더했으니, 정규화를 시켜서 가운데에 잘 모아주는 역할인 듯 합니다.
이로서 왼쪽의 Encoding 부분은 설명을 끝냈다고 생각합니다.
디코더를 살펴보겠습니다.
디코더는 Multi-head attention 블록들을 살짝씩 바꿔서 두겹을 쌓은 형태입니다.
먼저 가장 아래 블럭
가장 아래 블럭은 Masked-Multi-head Attention이라고 써 있군요
아까 위에서 설명드렸듯이, 트랜스포머는 디코더에서 입력을 한 단어씩 받지 않습니다. 한번에 받지요.
그러면 커닝을 하는거와 다를 바 없으니 제대로 된 학습이 진행되지 않습니다.
이를 막기 위해 Masking 작업을 합니다.
Masking 작업은 어떻게 해야되즤
간단하게 못보게 막고 싶은 단어 벡터에는 아주 큰 음수를 더해줍니다.
그러면 softmax 과정에서 마스킹 된 단어의 확률이 0에 수렴하기 때문에, 로 짬뽕시킬 때 정보가 들어가지 않습니다.
그리고 그 위 블럭
위 블럭은 Wk와 Wv는 인코더에서 오지만, Wq는 디코더에서 전달됩니다.
I love you so much에서 디코더로 "나는"이라는 단어가 나왔다면
이걸 가지고 I love you so much끼리 self attention 된 문맥 벡터와 잘 비교를 해서 어떤 단어와 연관성이 있고 다음에 뭐가 나올지에 대해 추론을 해본다고 할 수 있겠습니다.
그리고 Linear layer과 softmax를 통해 다음에 나올 단어를 출력하는 것이죠.
'
'
'
죄송하지만 제 지식으로는 이렇게 되게 먼 차원에서 설명하는 수준밖에 되지 못합니다.
아직 모르는 부분이 많네요.
좀 더 벡터가 어떻게 변하고, 번역 도메인이 어떻게 바뀌는지에 대해서 음미하고 설명을 추가하던가 해야겠습니다.
(잘 아시는 분은 꼭좀 알려주셨으면 좋겠습니다.)
긴 글 읽어주셔서 감사합니다.
