반갑습니다.
오늘은 모델의 성능을 올리는 방법들에 대해 소개해볼까 합니다.
저도 모델의 성능을 올리는 것이 아직 서툴지만 소개해드리는 방법중 하나라도 읽는 분의 도움이 되었으면 좋겠습니다.
1. Task 선정
일단 첫번째로 내가 AI 모델로 뭘 할것인지를 정합니다.
Classification, Summarization, Translation, chatbot 등이 있겠죠.
2. 기반모델 선정
Task를 정했다면 사용할 모델을 정합니다.
이 부분이 아마 많이 어렵지 않나 싶습니다.
최신 연구 동향을 파악하실 수 있을 정도의 실력자라면 모델 선정을 쉽게 할 수 있겠지만, 어떤 모델이 어디에 특화되어 있는지 잘 모른다면 방향성을 잡기 어렵겠죠.
방법은 두개정도 있을 것 같습니다.
1. 직접 조사한다.
허깅 페이스에 있는 모델들중 small이라고 돼 있는 모델들을 잡고 데이터를 넣어 학습을 시켜봅니다.
그리고 평가를 해보면 어떤 모델이 좋은지 알 수 있습니다.
이를 좀 더 효과적으로 알 수 있게 하기 위해 Wandb나
Tensorboard를 적극적으로 활용해야 합니다.
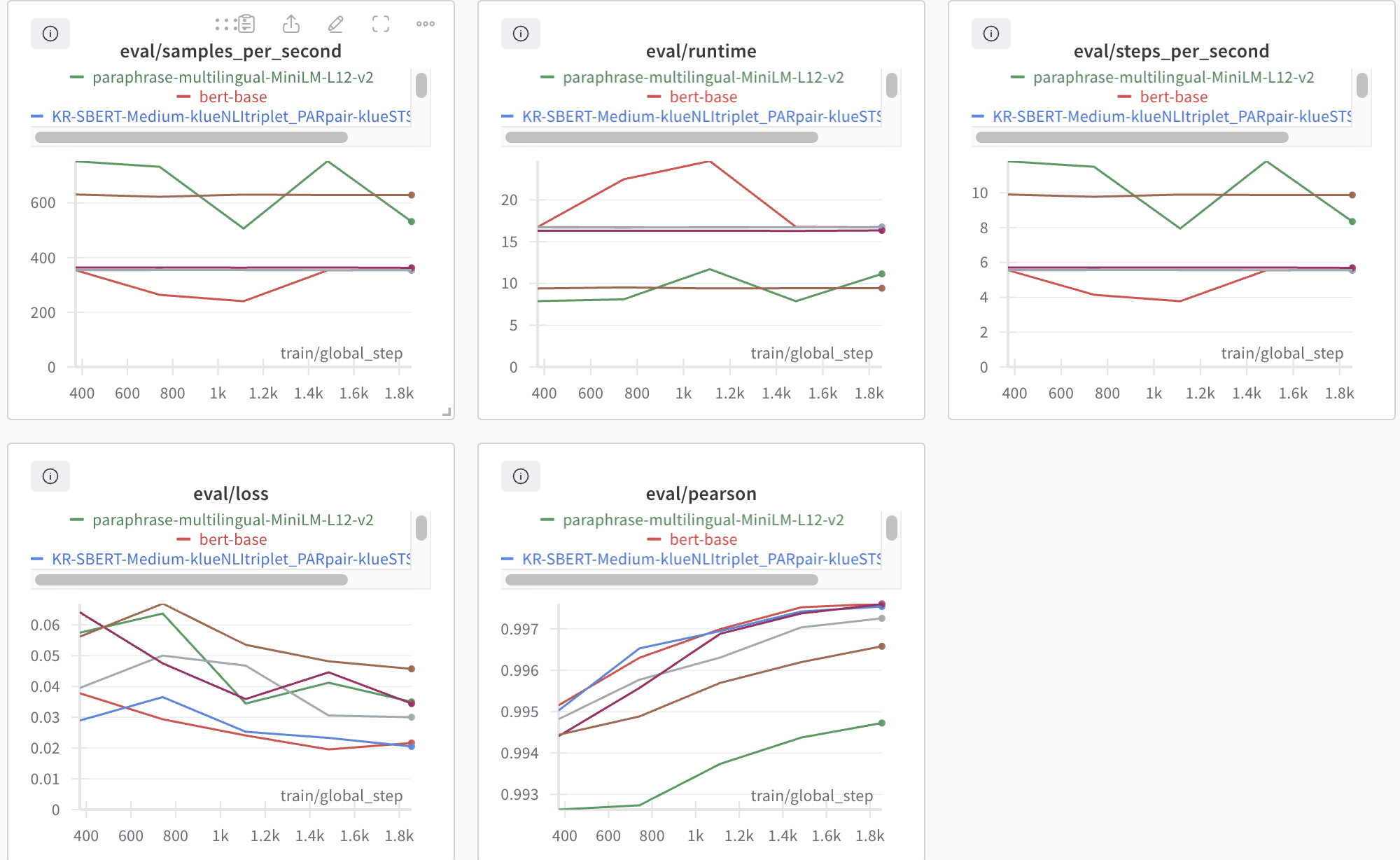
저는 Wandb를 사용합니다.

그래프에 마우스를 갖다 대면 이렇게 평가에 대한 지표들을 알 수 있습니다.
2. 이미 나온 모델들의 지표를 살펴본다.
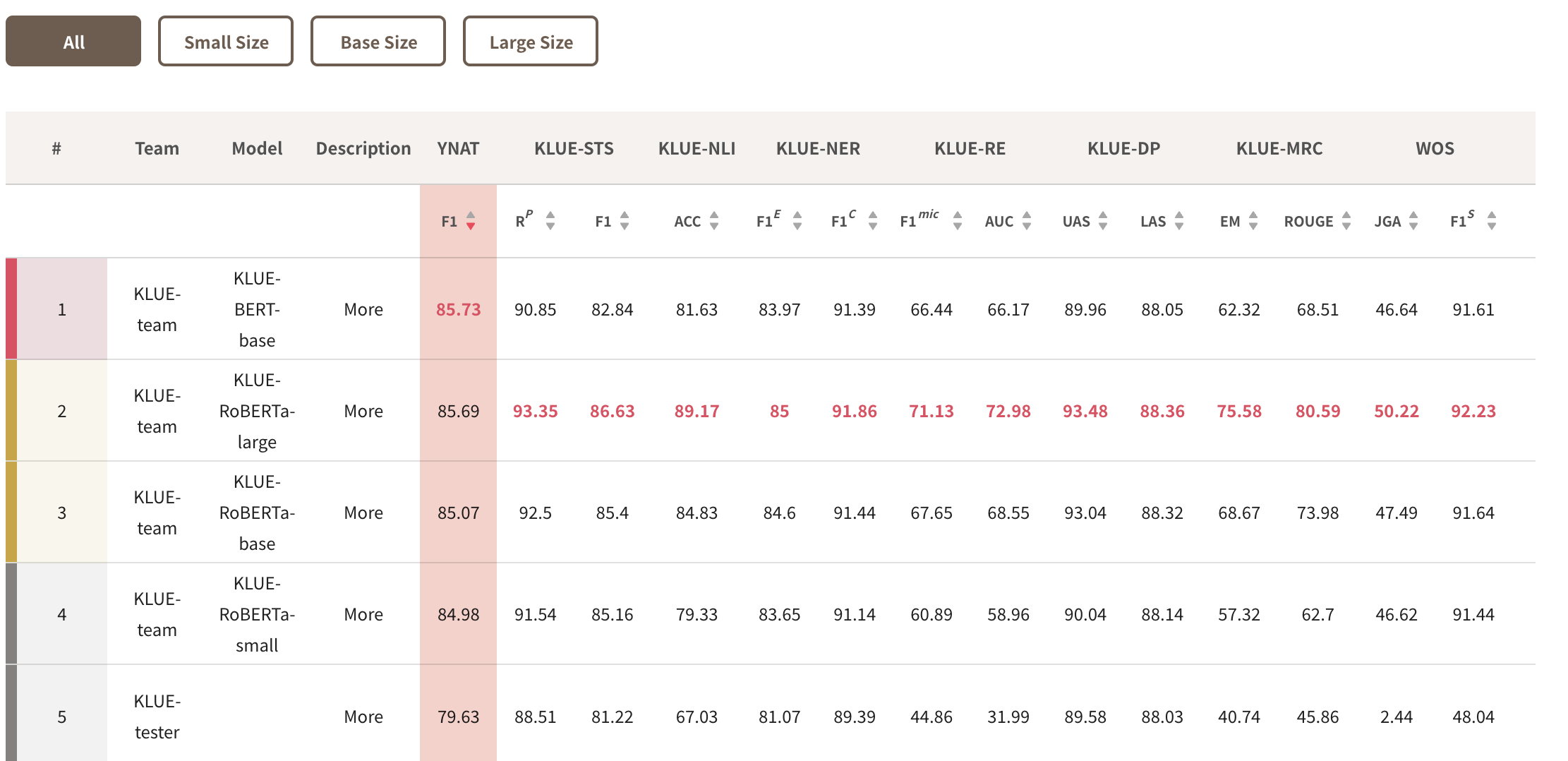
KLUE를 예로 들어보면 그냥 구글에 KLUE leadorboard라고 치면 벤치마크가 나옵니다.
여기서 모델들을 보면
아합
KLUE는 BERT-base가 성능이좀 좋구나
나도 한국어 데이터셋을 가지고 Classification을 할거니께
좀 써봐야겠다
라고 알 수 있겠습니다.
좀 더 디테일하게 생각해본다면 내가 일상 대화 챗봇을 사용하고자 한다.
그러면 기반 모델을 고를 때 구어체의 텍스트를 학습한 모델을 골라야겠죠.
문어체로 학습한 모델을 고르면 너무 딱딱한 말투의 output이 나올 수도 있으니 잘 고려해야겠습니다.
3. 하이퍼파라미터 최적화
모델의 성능을 올리고자 한다 하면 자주 나오는 하이퍼파라미터 최적화입니다.
Batch_size, num_epochs, learning_rate 등의 하이퍼파라미터를 잘 조정하여 모델의 성능을 올립니다.
예전에는 직접 하나씩 넣으면서 잘 볶으면 됐다던데 잘 모르겠습니다.
요즘은 Optuna나 Sklearn, Hyperopt, WandbSweep 과 같은 최적화 툴을 이용하여 하이퍼 파라미터를 찾습니다.
저는 Optuna만 써봐서 이것을 예로 들어보겠습니다.
import optuna
def objective(trial):
learning_rate = trial.suggest_float("learning_rate", 0.00005, 0.0001, log = True)
params = {~~, 'learning_rate' : learning_rate}
model = SomeClassifier(**params) # 주어진 하이퍼파라미터로 모델 생성
model.fit(X_train, y_train) # 모델 훈련
preds = model.predict(X_val) # 검증 데이터에 대해 예측
score = accuracy_score(y_val, preds) # 정확도 계산
# 최적화에서는 보통 음수 값을 반환하여 최적화 알고리즘이 최소화하도록 설정
return score
study = optuna.create_study(direction = 'maximize')
study.optimize(objective, n_trials = 100)
print(study.best_value, study.best_params)이렇게 objective 함수를 만들어서 지표를 return해주면 optuna가 여러번 반복하며 최적의 하이퍼파라미터를 찾습니다.
보통 하이퍼 파라미터 searching에는 grid search과 random search가 있습니다.
- grid search : 에폭을 예로들면 1, 2, 3, 4, 5 이런식으로 지정한 값을 대입
- random_search : 에폭을 예로들면 randint(1,5)와 같이 범위만 지정
이외에도 다양한 방법이 있습니다.
optuna에서는 Tree-structured Parzen Estimator (TPE)라는 방식으로 하이퍼파라미터를 제안한다고 하는데, 간단히 말하면 이전 결과를 보고 내려야 할건 내리는 쪽으로 올려야 할건 올리는 쪽으로 제안을 한다고 생각하시면 되겠습니다.
4. 앙상블
앙상블이란, 다양한 모델을 합치는 것을 의미합니다.
Hard/Soft Voting을 이용하여 모델들을 합치거나 bagging, boosting, MoE(mix of Experts)등을 이용하여 모델들을 합쳐 성능을 향상시킵니다.
1. Voting
어떤 모델이 90점의 성능을 가졌다고 생각해 봅시다.
그러면 모델을 사용할 때 랜덤값이 어떻냐에 따라 또는 시드가 어떻냐에 따라 89점이 나올 수도 있고 88점이 나올수도 있겠죠. 또 특정 데이터에만 안좋은 판단을 내릴 수도 있습니다.
하지만 모델을 10개를 사용하여 값의 평균을 사용한다면 랜덤한 요소에 의해 성능이 저하되는 일을 막을 수 있습니다.
제 머리속에는 Noise를 줄이는 방식이라고 생각하고 있습니다.
Voting은 Hard Voting과 Soft Voting이 있습니다.
Hard Voting은 다수결이라고 생각하시면 되겠습니다.
모든 모델이 똑같은 한표를 가지고 Classification을 수행합니다.
Soft Voting은 Weighted Sum을 이용하여 prediction을 수행합니다.
가중치는 개인이 판단해서 합이 1이 되도록 설정하시면 되겠습니다.
뭐 파라미터가 많은 모델이 높은 가중치를 가지도록 설정하거나 하시면 되겠죠.. ㅎㅎ
이외에도 Log probability를 합하여 앙상블하는 Average Log Probability 방법도 Voting의 한 종류라고 볼 수 있겠습니다.
2. Bagging
Bagging(Bootstrap Aggregating)이란, 데이터를 나눠서 여러 모델을 만든 뒤, 마지막에 합치는 앙상블 기법입니다.
데이터셋을 여러개를 만든 뒤(중복 허용) 각 데이터셋마다 하나의 모델을 만들어 병렬로 학습시킵니다.
그리고 마지막에 Hard voting이나 Soft Voting 등을 하는 방식으로 결과를 내는 방법입니다.
Random Forest 모델이 위 방법을 통해 만들어진 대표적인 모델입니다.
3. Boosting
Boosting이란, 잘게 나눈 데이터를 이용하여 작은 모델을 학습시킵니다.
그 이후 평가하여 부족한 부분에 더 강한 가중치를 주어 다음 데이터셋을 순차적으로 학습시키는 학습 방법입니다.
중요한 점은 순차적으로 학습시킨다는 부분입니다.
그리고 하나의 모델을 통해 학습시킨다는 부분이 Bagging과의 큰 차이점이겠죠.
Adagrad나 Gradient Boosting 모델이 Boosting 방법론을 통해 만들어진 대표적인 모델입니다.
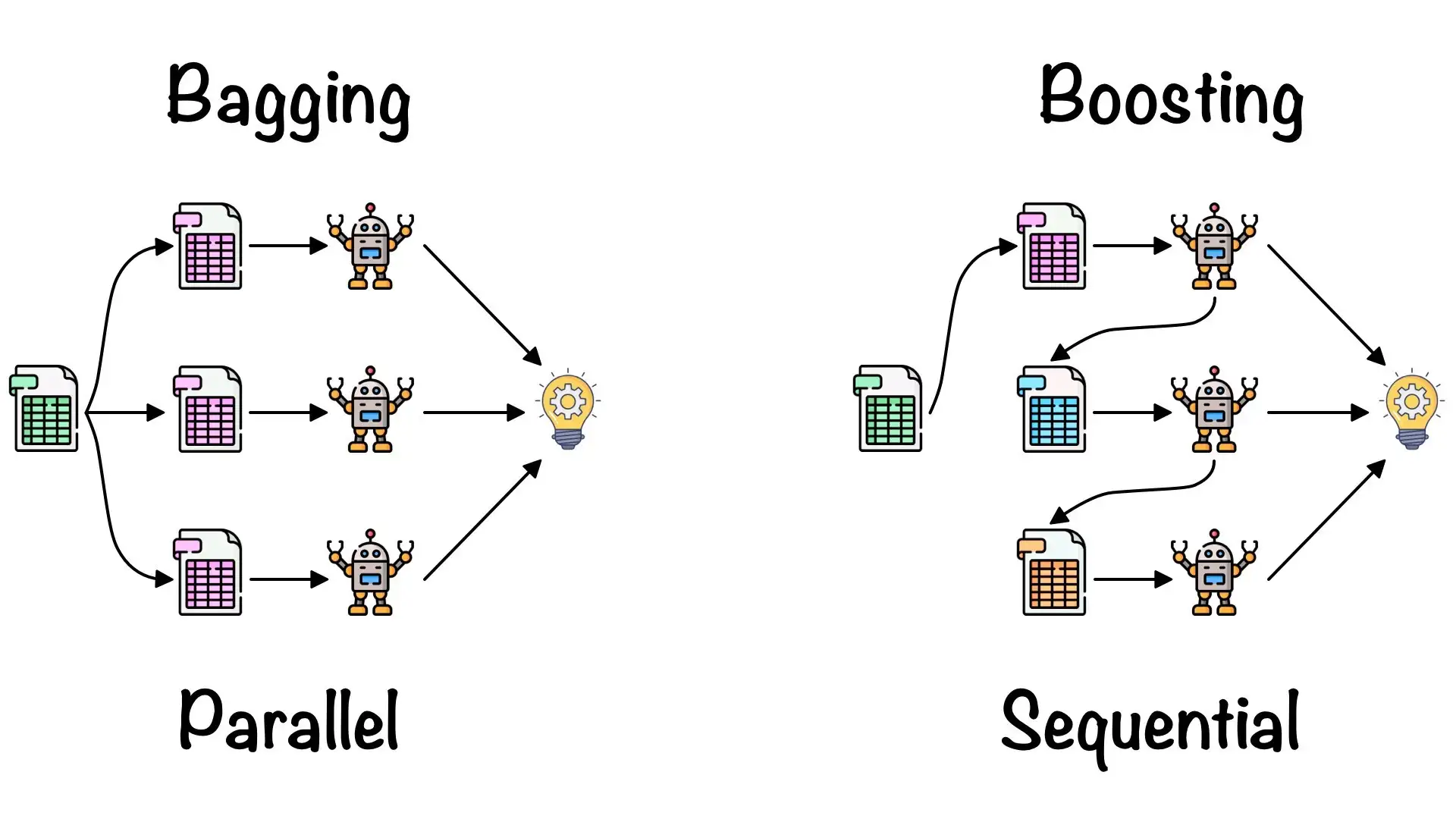
Bagging과 Boosting이 헷갈리는 경우가 많은데, 위 사진이 직관적으로 알 수 있지 싶습니다.
4. MoE (Mixture of Experts)
각 분야에 대해 전문적인 모델들을 모아 Network를 통과시켜 결과를 내는 앙상블 기법입니다.
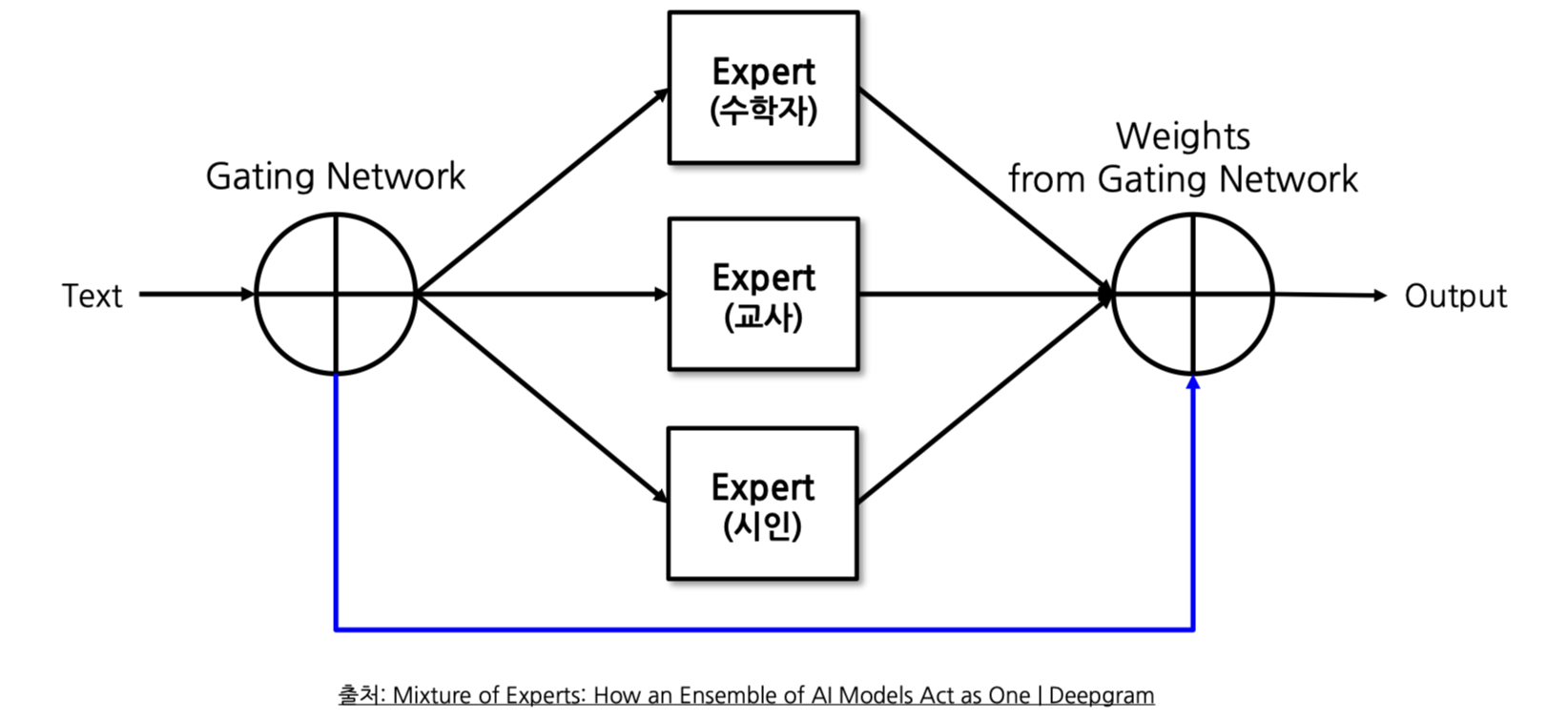
위 사진처럼 특정 분야에 강한 모델들을 모아서 Neural Net을 통과시키는 방법으로 학습시킵니다.
데이터를 통한 학습으로 어느 데이터는 수학 Model의 가중치를 크게 줘야하는구나 어느 데이터는 교사 Model의 가중치를 크게 줘야하는구나 를 조정합니다.
5. Router
MoE의 하위 개념으로 MoE의 구조 중 쿼리를 어느 모델에 보낼지를 정하는 하나의 모듈.
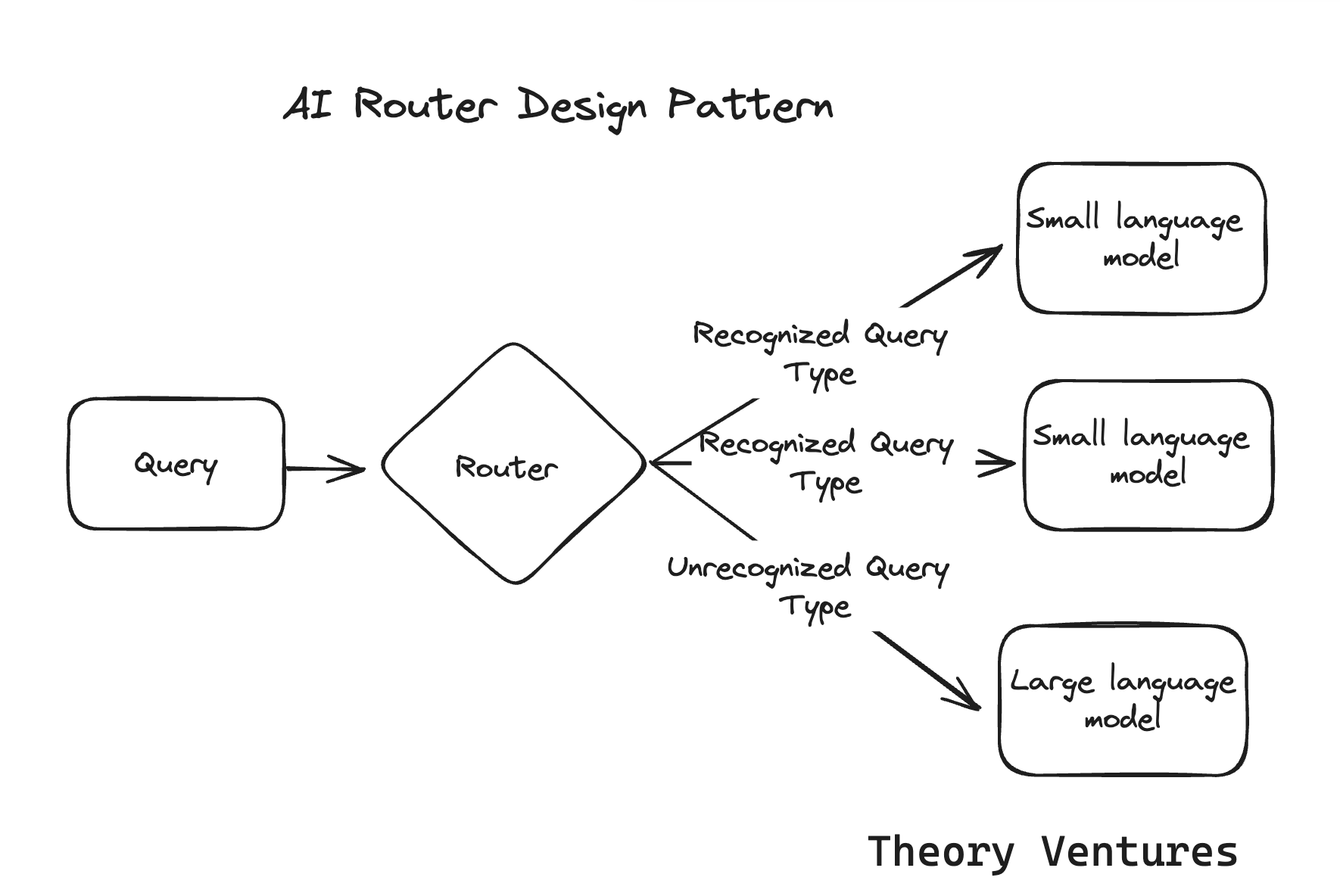
MoE에서 어느 모델로 보낼지 정하는 부분을 Router라고 알고 계시면 되겠습니다.
5. PEFT(Parameter Efficient Fine Tuning)
PEFT란 큰 모델의 파라미터를 전부 학습하지 않고 비교적 작은 Neural Net을 붙여 그 Neural Net만 학습시키거나, 모델 파라미터의 일부분만 바꾼다거나 등의 방법으로 적은 시간 리소스를 들여 기존 모델과 같은 성능을 내는 방법론을 의미합니다.
요즘 대세는 PEFT가 아닐까 싶습니다.
AI모델의 발전이 충분히 이루어졌고, 이러한 모델을 다방면으로 사용하기 위해서는 하드웨어에 탑재하는 것이 중요합니다.
하지만 핸드폰이나 가전제품 등에 LLM(Large Language Model)을 적재하기란 쉽지 않은 일입니다.
그래서 최근에 각광받고 있는 기술이 PEFT입니다.
기존 모델보다 훨씬 적은 파라미터로 기존 모델과 비슷한 Performance를 낼 수 있다는 점에서 안쓸 이유가 별로 없습니다.
PEFT는 다양한 방법으로 이루어집니다.
1. Prefix Tuning
Prefix Tuning이란, 사전 학습 모델의 파라미터를 Freeze시키고 앞부분에만 학습 가능한 파라미터들을 배치하여 Fine Tuning하는 기법입니다.
어떻게 하는거냐면
from transformers import GPT2Tokenizer, GPT2Model
import torch
import torch.nn as nn
class PrefixTuning(nn.Module):
def __init__(self, prefix_length, model_hidden_size, num_layers):
super(PrefixTuning, self).__init__()
self.prefix_length = prefix_length
self.model_hidden_size = model_hidden_size
self.num_layers = num_layers
# 학습 가능한 프리픽스 벡터 생성
self.prefix = nn.Parameter(torch.randn(num_layers, prefix_length, model_hidden_size))
def forward(self, batch_size):
# 프리픽스를 배치 크기에 맞게 확장
prefix_expanded = self.prefix.unsqueeze(0).expand(batch_size, -1, -1, -1)
return prefix_expanded
이렇게 prefix 파라미터들을 지정하고 내뱉는 클래스를 만듭니다.
이후에 input에서 torch.cat(input, prefix[:,0,:,:])으로 합치면
prefix : (batch_size, num_layers, prefix_length, model_hidden_size)
input : (batch_size, sequence_length, model_hidden_size)
합쳐진 input : (batch_size, prefix_length + sequence_length, model_hidden_size)
가 되겠습니다.
2. LoRA(Low-Rank Adaption)
LoRA란 기존 사전 모델의 파라미터는 freeze 시키고 그 옆에 Neural Net을 구축하여 이후 output에서 합쳐지는 방식의 PEFT입니다.
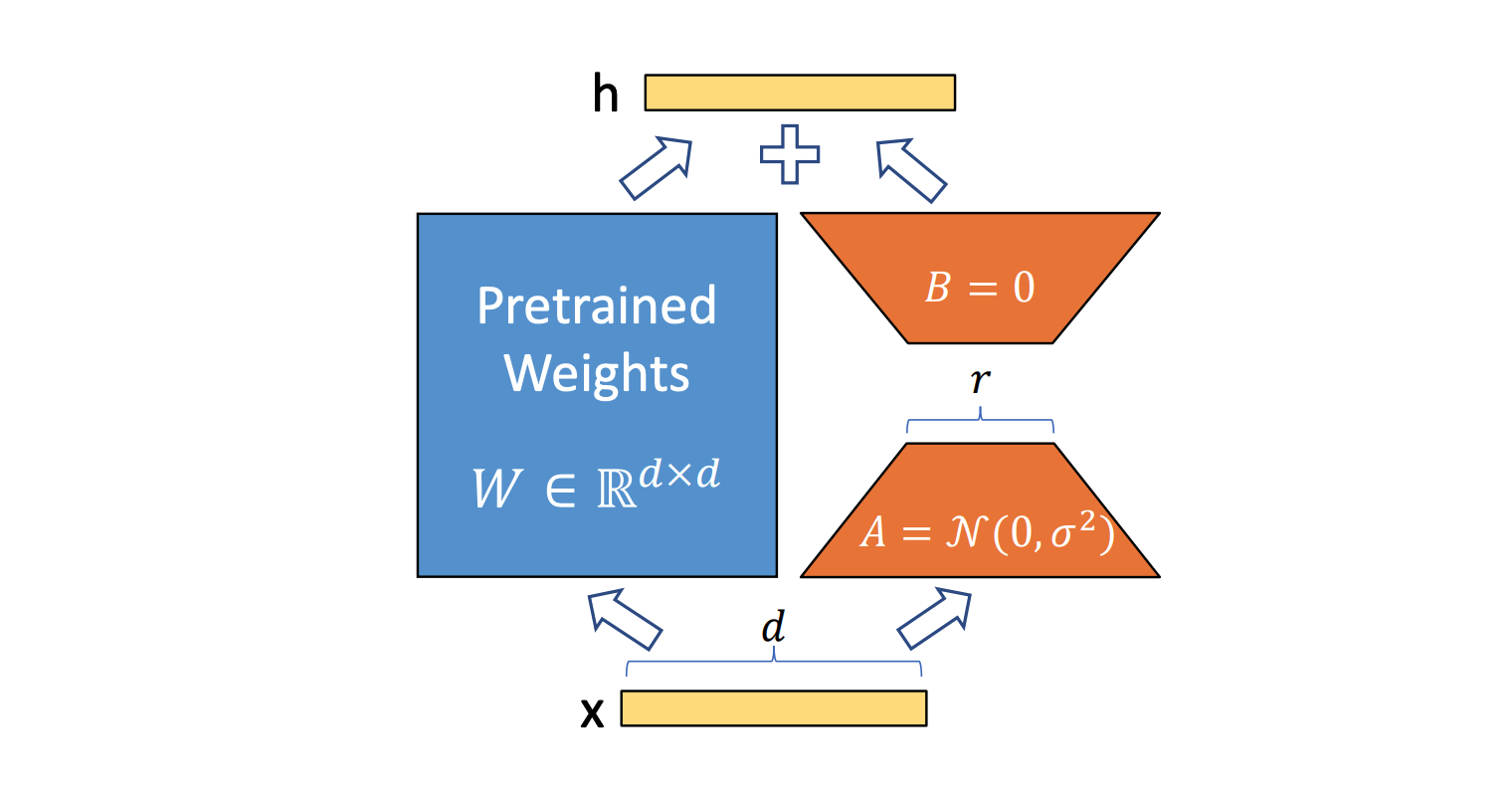
이런식으로 두 Network를 합칩니다. 이 때, 오른쪽에 있는 Network는 r차원으로 줄여졌다 다시 펴지기 때문에 파라미터의 수가 pretrained 모델보다 훨씬 작게 됩니다.
이 부분만을 학습하는 것이지요.
3. ReFT(Representation Fine Tuning)
ReFT란 모델의 파라미터는 고정하고 앞부분의 임베딩 레이어를 학습 가능한 파라미터로 지정하여 학습하는 PEFT 기법입니다.
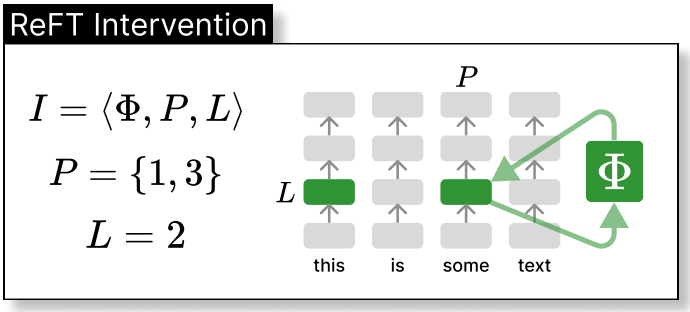
이런 식으로 단어를 표현하는 임베딩 레이어 (nn.Embedding)만 학습 가능한 파라미터로 바꿔 학습시키는 방법입니다.
한 도메인의 데이터로 학습시 다른 도메인에서는 성능이 떨어지는 단점이 있지만, 한 분야에 특화된 경량화 모델을 만드는 데에 유용하게 사용될 수 있습니다.
PEFT를 사용하는 이유?
PEFT를 사용하면 모델의 성능이 비약적으로 상승하진 않지만, 한정된 리소스를 알차게 사용할 수 있다는 장점이 있습니다.
10시간동안 하나의 모델을 학습시키는 것보다 3시간만에 열개의 모델을 학습시키고 앙상블을 하는 방법이 어느 한 Task만 풀이하는데에 있어서는 훨씬 효율적이라고 볼 수 있겠죠.
저도 이번에 한번 PEFT를 사용해 보고 결과를 비교해 봐야겠습니다.
또 할말이 생긴다면 추가적으로 PEFT 부분에 글을 작성해보겠습니다.
'
'
'
사람들이 모델의 성능을 올리기 위해 하는 방법론들은 대부분 다 다룬 것 같습니다.
이번 글에서는 데이터셋에 대해서는 자세히 다루지 않았는데요, 모델의 성능을 올리기 위해서는 적절한 데이터의 전처리도 아주 중요한 부분입니다.
텍스트 데이터건 이미지 데이터건 데이터를 잘 정규화하고 불필요한 부분을 없애는 작업도 같이 병행하면 모델의 성능을 더 올릴 수 있을거라고 생각합니다.
감사합니다 !
