mlflow 서비스를 처음 시작하다보니 다소 헷갈리는 부분이 있다. 프레임워크 문서를 먼저 읽어보지 않고 시작을 해서 그런 것 같기도 하다.
헷갈렸던 부분을 정리하고 오늘은 mlflow ui와 mlflow server에 대해서 간단히 살펴보고자 한다.
먼저 MLflow는 github 를 가면 아래와 같이 네 가지 component로 이루어져 있다고 한다.
MLflow Tracking: 기계 학습 실험에서 매개변수, 코드 및 결과를 기록하고 대화형 UI를 사용하여 이를 비교할 수 있는 API.
MLflow Projects: Conda 및 Docker를 사용하여 재현 가능한 실행을 위한 코드 패키징 형식으로, 다른 사람들과 ML 코드를 공유할 수 있습니다.
MLflow Models: 모든 ML 라이브러리에서 동일한 모델을 Docker, Apache Spark, Azure ML 및 AWS SageMaker와 같은 플랫폼에서 배치
및 실시간 스코어링에 쉽게 배포할 수 있도록 하는 모델 패키징 형식 및 도구.
MLflow Model Registry: MLflow Models의 전체 수명 주기를 공동으로 관리하기 위한 중앙 집중식 모델 저장소, API 세트 및 UI.
chatGPT 번역
여기서 첫 번째 component인 MLFlow Tracking에 대해서 주로 사용을 해보았으며 이 중에서 헷갈렸던 내용을 먼저 정리하였다.
첫번째로 헷갈리는 부분은 mlflow ui 와 mlflow server 다.
mlflow하면 가장 먼저 떠올랐던 것은 ui였다. 그리고 내 머리속에서는 이 ui에서 바로 학습의 주요 메트릭들을 관찰하고 비교해볼 수 있을 것이라는 아이디어가 가장 인상깊게 남아 있었다.
내가 하고 싶은 것은 따라서 주요 메트릭을 관찰할 수 있는 가장 쉬운 방법이 무엇인가 하는 것이었다.
먼저 mlflow를 설치하고, mlflow를 이용한 학습을 수행한다.
예를 들자면 아래와 같이 mlflow.start_run() 을 이용하여 시작할 수 있다. 아래는 각 mlflow.log_param 을 이용해서 파라미터를 기록하는 스크립트이다. metric의 경우에는 epoch 또는 batch 마다 기록될 수 있도록 train 함수 내부에 mlflow.log_metrics({"loss": loss.item()}, step=batch_idx) 와 같이 기록하고 싶은 metric을 인자로 넣어서 작성해주면 된다. step 인자는 batch_idx 또는 epoch를 사용하거나 하면된다. step 인자가 없으면 단지 시간의 순서대로만 표시되므로 step을 사용해주도록 하자.
with mlflow.start_run() as run:
mlflow.log_param("lr", scheduler.get_last_lr()[0])
mlflow.log_param("gamma", gamma)
mlflow.log_param("seed", seed)
mlflow.log_param("batch_size", batch_size)
mlflow.log_param("test_batch_size", test_batch_size)
mlflow.log_param("log_interval", log_interval)
for epoch in range(1, epochs + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
학습은 평소와 다름없이 시작되고 위 스크립트에서 사용된 log_param, log_metric 메써드에서 기록을 하게 된다.
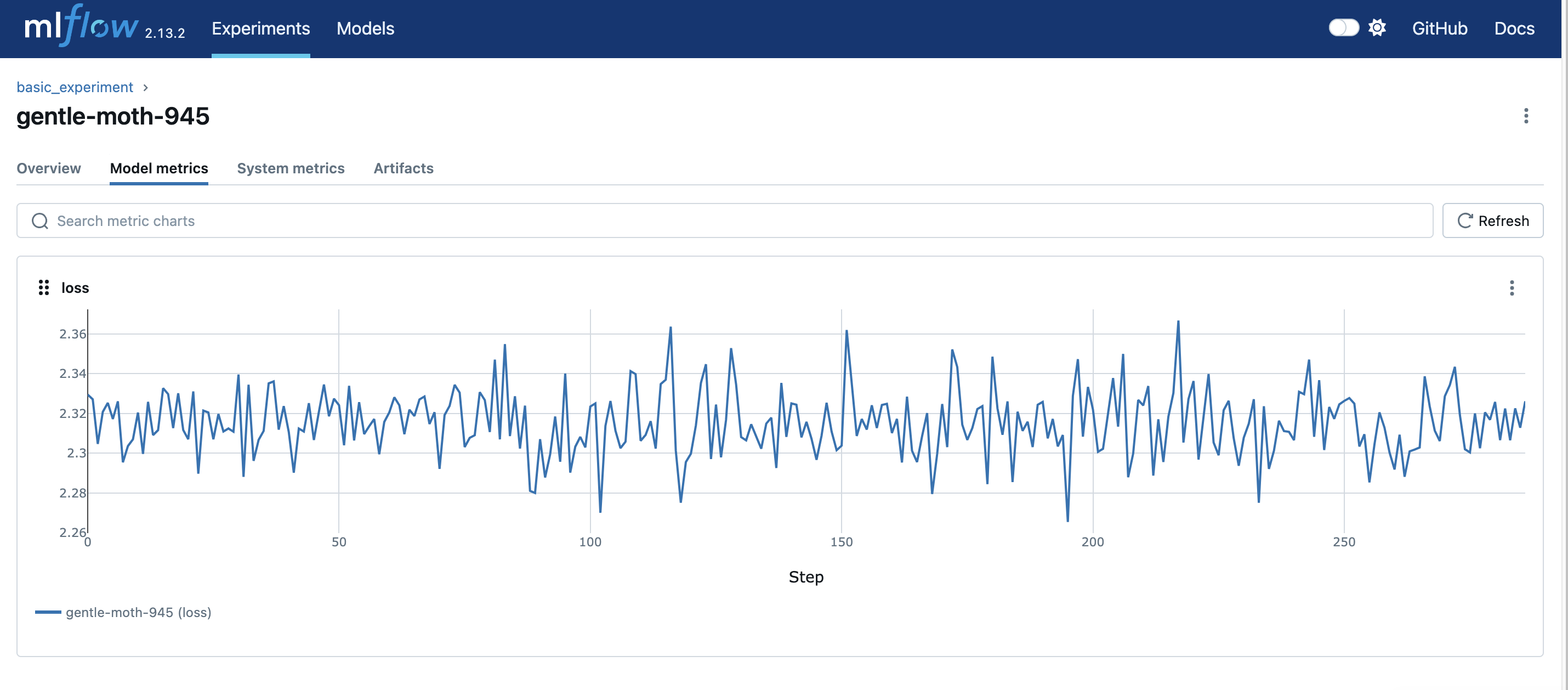
학습이 종료된 이후 다음 명령어를 통해서 localhost:<지정포트>로 접근할 수 있다.
mlflow ui --port 5000 (포트는 원하는 포트로 지정가능)이때 mlflow ui는 project 안에 해당 run으로 인해 만들어진 .mlruns/ 폴더에 저장된 meta 정보를 활용하여 ui dashboard에서 보여준다. 이 때 ./mlruns 각 폴더 아래로 run id 개념의 식별자가 생성되고 그 아래로 모델의 artifact들과 meta.yaml 파일이 생성되어 보여줄 수 있는 것이다.
다음으로 약간 다른 모습의 mlflow server를 이용하는 방법이다. mlflow 서버는 local 저장소에 ./mlruns를 생성하고 그 아래 run의 정보를 담는 것과 조금 다르다. 다음 에피소드에서 소개하도록 하겠다.
