강의 주소 : http://www.kocw.net/home/cview.do?mty=p&kemId=1169634
무려 5개월만에 다시 공부하는 네트워크 계층, 그래도 여태 적었던 내용들을 토대로 가볍게 복습하니 내용은 머리에 좀 남는 것 같다.
또 이것 저것 실습하면서 체득된 정보들이 있어서 그런거 같기도 하고
요 근래 10개의 게시글에서 존댓말을 이용해서 해봤는데 , 지금 다시 예전 글들을 읽어봤더니 존댓말로 쓴 것들이 더 잘 안읽히는 것 같더라
그래서 그냥 다시 반말로 하기로 했다.
의식의 흐름대로 공부 할 수 있게
데이터의 전송 단위
- 애플리케이션 레이어 : 메시지
- 트랜스포트 레이어 : 세그먼트 (헤더와 데이터로 이뤄진)
- 네트워크 레이어 :
packet(헤더와 데이터들이 존재함) - 링크 레이어 : 프레임 (헤더와 데이터들)
각 데이터는 상위 레이어의 정보들이 담긴다.
IP Header
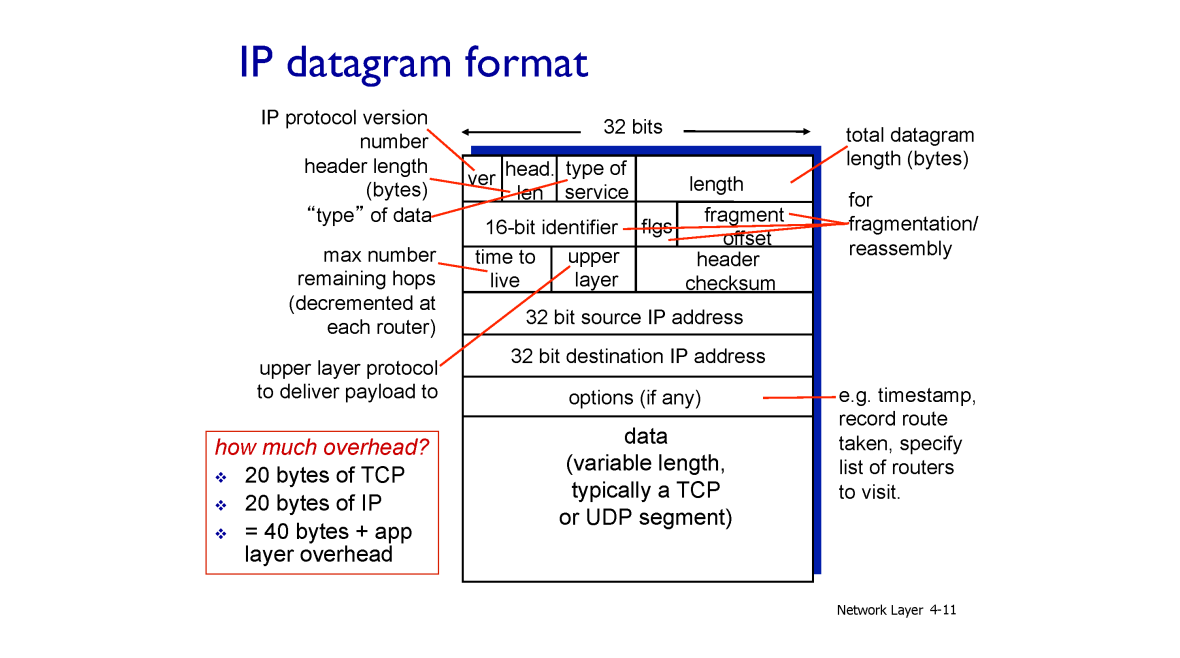
data:TCP , UDP Segmentver: 현재IP version은 4length:Packet의 길이- ⭐
source IP Address , destination IP Address:Sender의IP주소 ,Receiver의IP주소 (32비트의 데이터) check sum: 에러를 판별하기 위한 비트time to live:packet이 라우터들을 거칠 때 마다time to live를 하나씩 줄인다. 즉 건널 수 있는 라우터의 수
왜
time to live가 필요한데 ?
packet routing이 잘못 되어packet이 정처없이 라우터들을 떠돌며 네트워크의 혼잡도를 높히는 것을 방지하기 위해서
-
upper layer: 상위 레이어의 통신 종류 (TCP or UDP) , 어차피data에 있는 것은 상위 레이어에서 내려온 정보이기 때문 -
identifier , flag , fragment: 다음 시간에 ..
각 header 들은 모두 20 byte 씩 갖는다. Packet 엔 IP header , TCP / UDP header 가 존재하기 때문에 packet 의 용량은 data + 40byte 이다.
IP Address
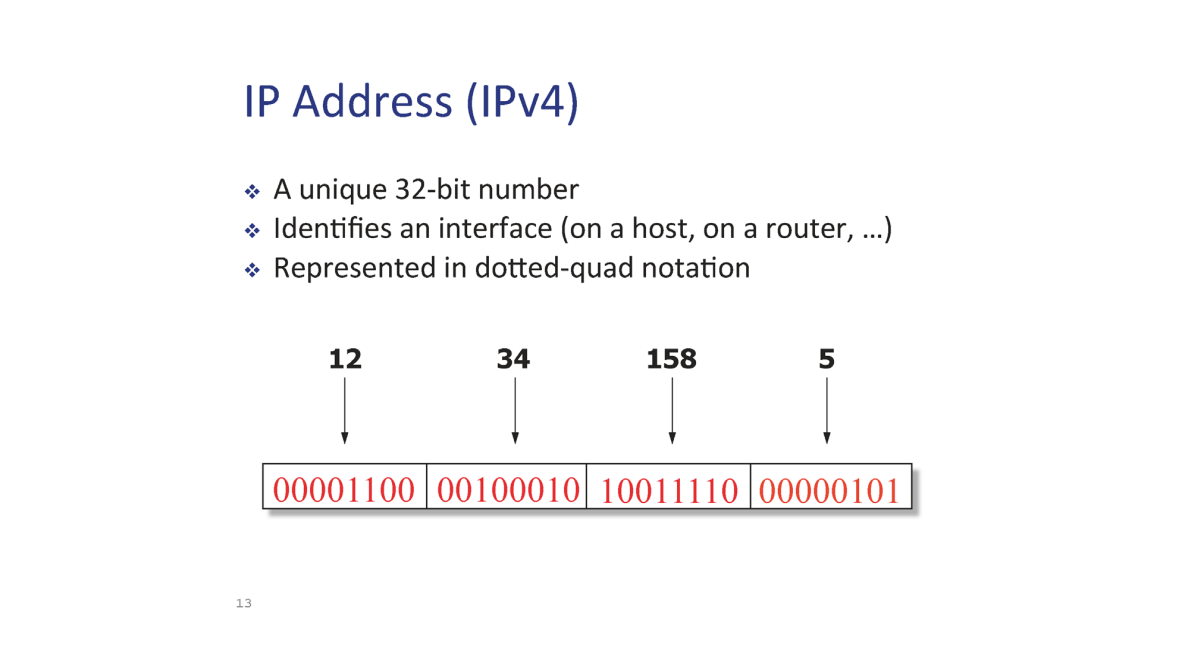
IP Address 는 32 bit 의 주소 체계를 갖는다.
이 때 읽기 편하게 8 bit 씩 나누고 십진수로 해석해 부른다. (컴퓨터는 그냥 이진수로 판별)
IP 는 각 컴퓨터의 Network Interface 를 가리키는 주소이다. 만약 Interface card 가 여러개면 여러개의 IP 주소를 가질 수 있다.
라우터가 그 대표적인 예시
Groupgin Related Hosts
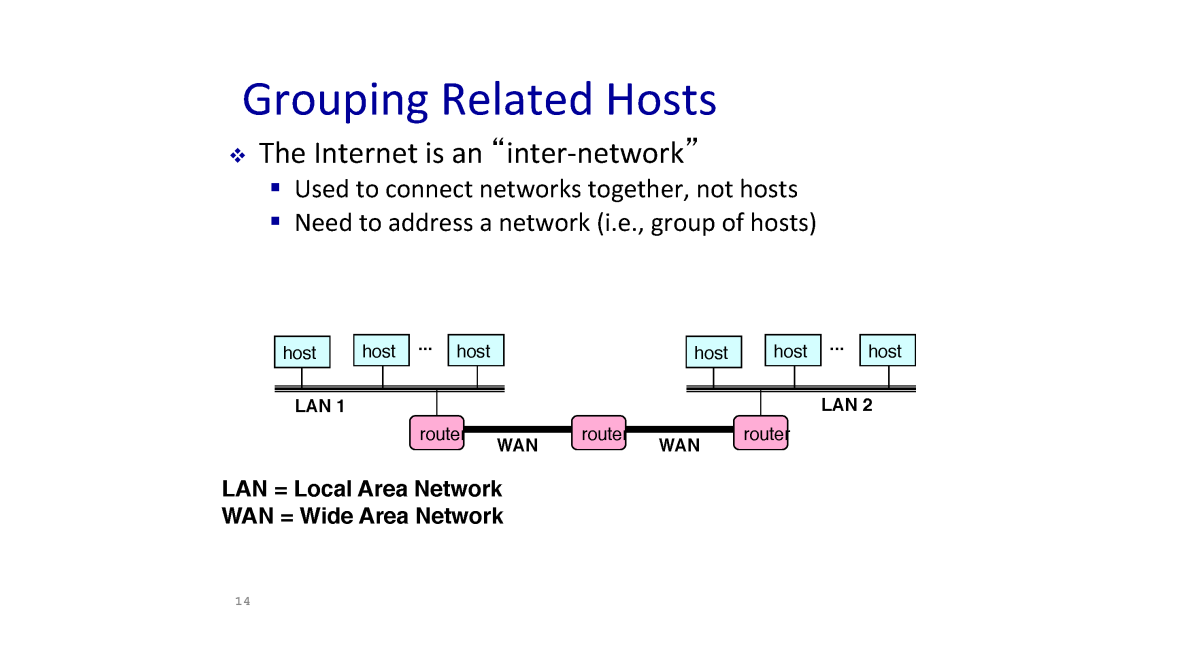
IP 주소는 지역적 특성에 맞게 그룹핑 되어 할당된다.
이유는 지역적인 응집도에 따라 Router 의 forward table 을 생성하여 효과적인 forwarding 을 하기 위해서
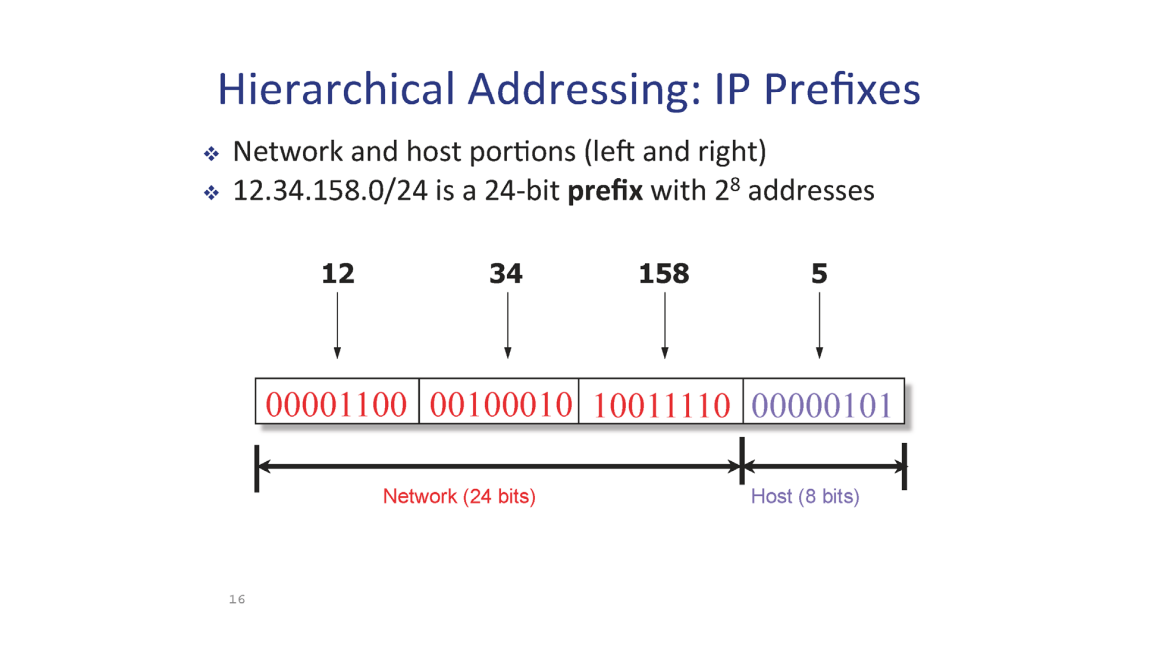
이 때 24 bit 는 IP Prefix or network ID , 나머지 8 bit 는 호스트를 칭하는 주소이다.
이 때 어디까지가 Prefix 이고 어디까지가 Host Address 인지 인식하기 위한 Subnet Mask 가 존재한다.
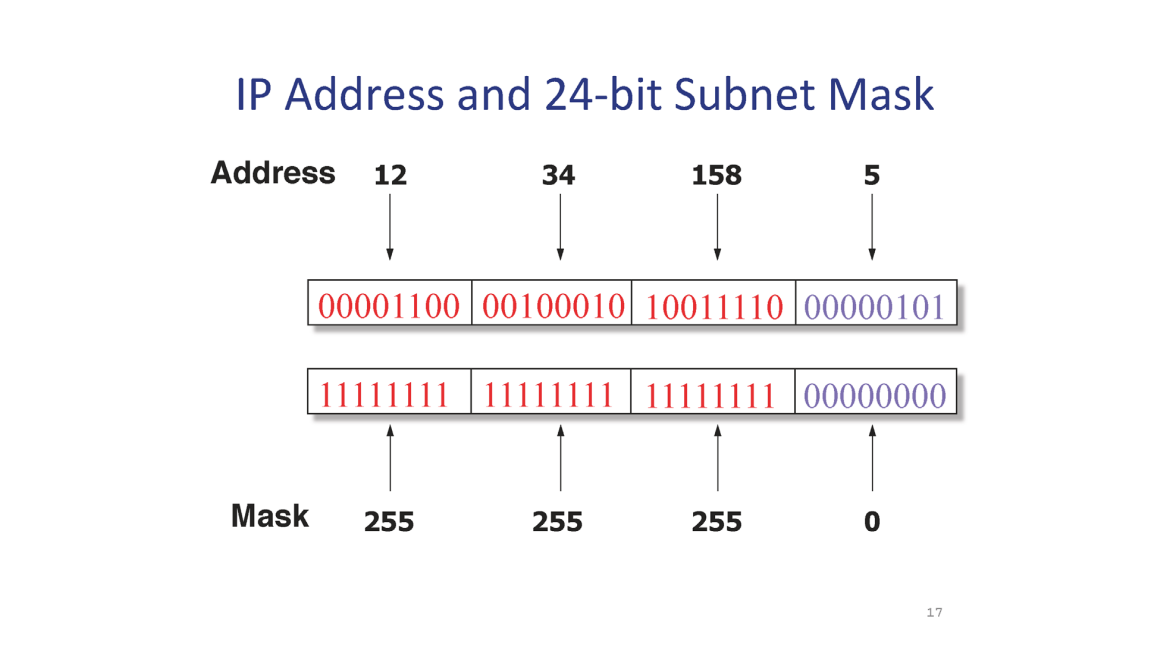
본인의 서브넷 마스크는 본인 네트워크의 호스팅 환경을 가리킨다.
Scalability Improved
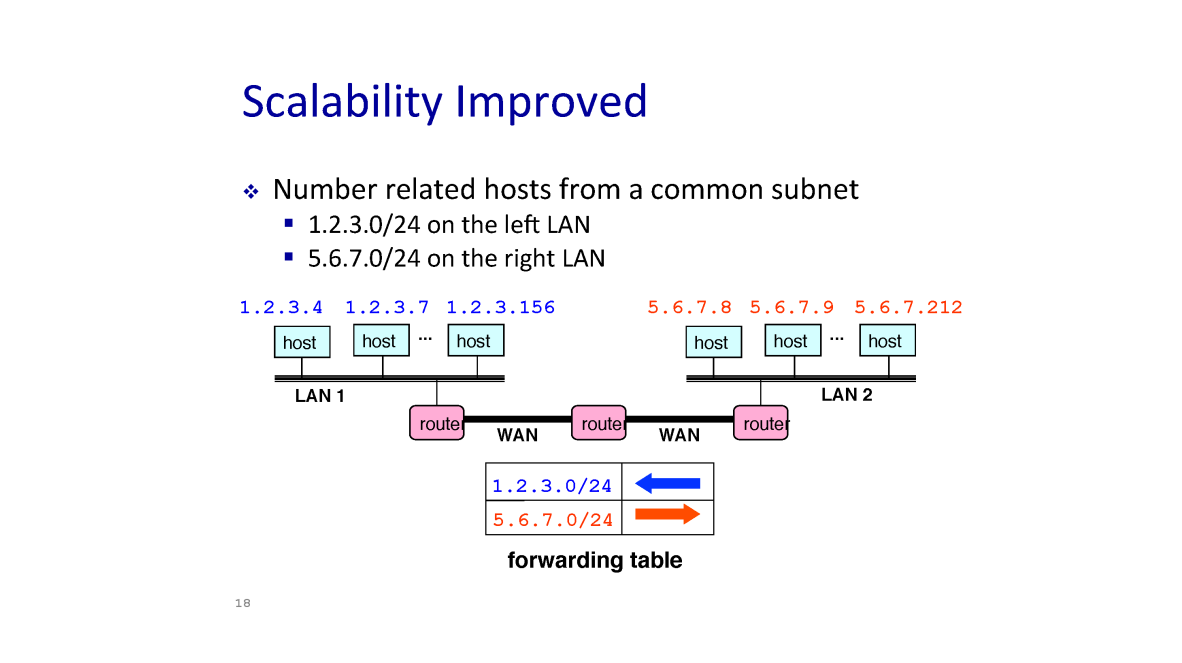
이렇게 지역적 특성에 따라 분류해두면 라우터의 forwarding table 이 매우 단순해진다.
그 뿐 아니라 새로운 호스트가 추가되었을 땐 , HOST IP 만 변경되어 생성하면 되기 때문에 새로운 IP 주소를 찾는 것이 쉽다.
Classful Addressing
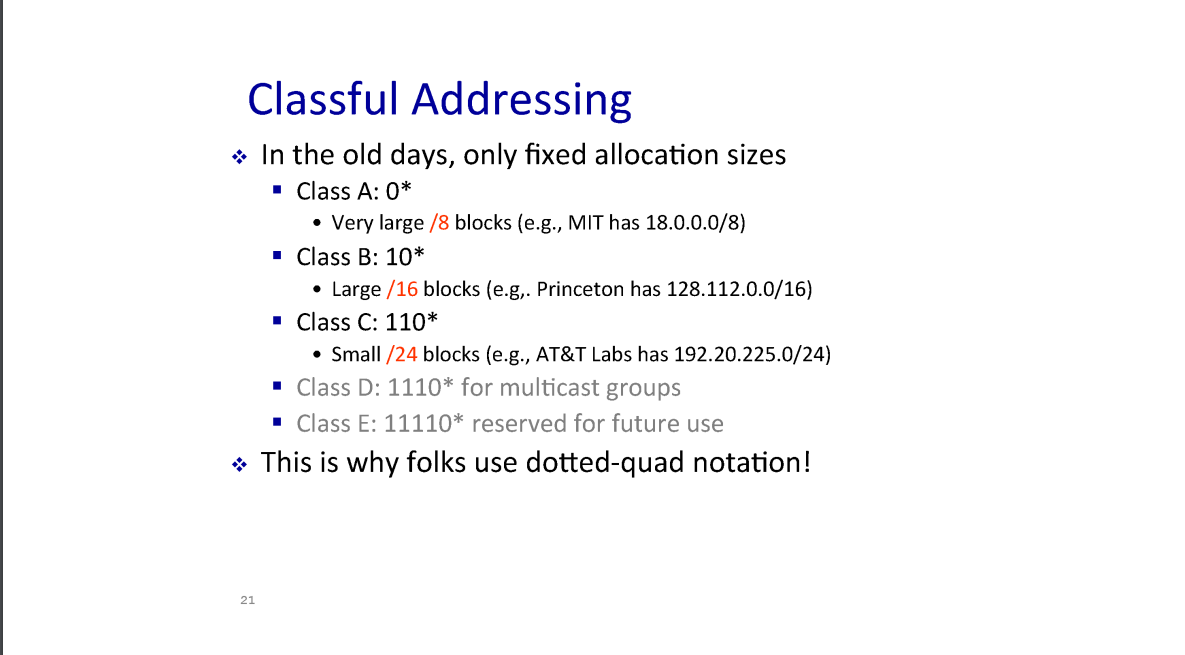
결국 Prefix 가 작을 수록 많은 HOST 들에게 네트워크를 제공 할 수 있었다.
그래서 과거엔 클래스 별로 prefix 의 크기를 할당했다.
예를 들어 Class A 의 prefix 는 8 bit 이기 때문에 명의 HOST 를 할당 할 수 있었다.
너무 크죠 ? 그래서 낭비가 너무 심했습니닷
그리고 인터넷 선구자들이 홀라당 큰 자리들을 다 선점했습니다너무 불공평하고 비효율적이야 ~~!!

그래서 90년대 중반에 Class 기반으로 제거하고 자유롭게 prefix 의 길이를 다르게 하여 할당 할 수 있게 변경되었다.
Logest Prefix Match forwarding

이전 Routing Table 에서 forwarding table 을 보고 가장 길게 매칭 되는 곳으로 forwarding 시킨다고 하였다.
근데 알고리즘의 이름의
Cute algorithm이네 귀엽다
CUTE알고리즘이 뭔가 했더니Congestion Control Using Threshold Evaluation를 의미하는 거였다.
TCP의congestion controll처럼Threshold를 이용하여packet loss가 일어나면 전송하는 패킷의 양을 감소시키는 알고리즘이다.
IP Addressing : CIDR

현재의 IP Address 는 CIDR 로 클래스 없이 Prefix 를 자유롭게 할당 가능한 주소 체계를 가지고 있다.
이 때 prefix 주소 / prefix 의 비트 수 를 의미한다.
Subnet
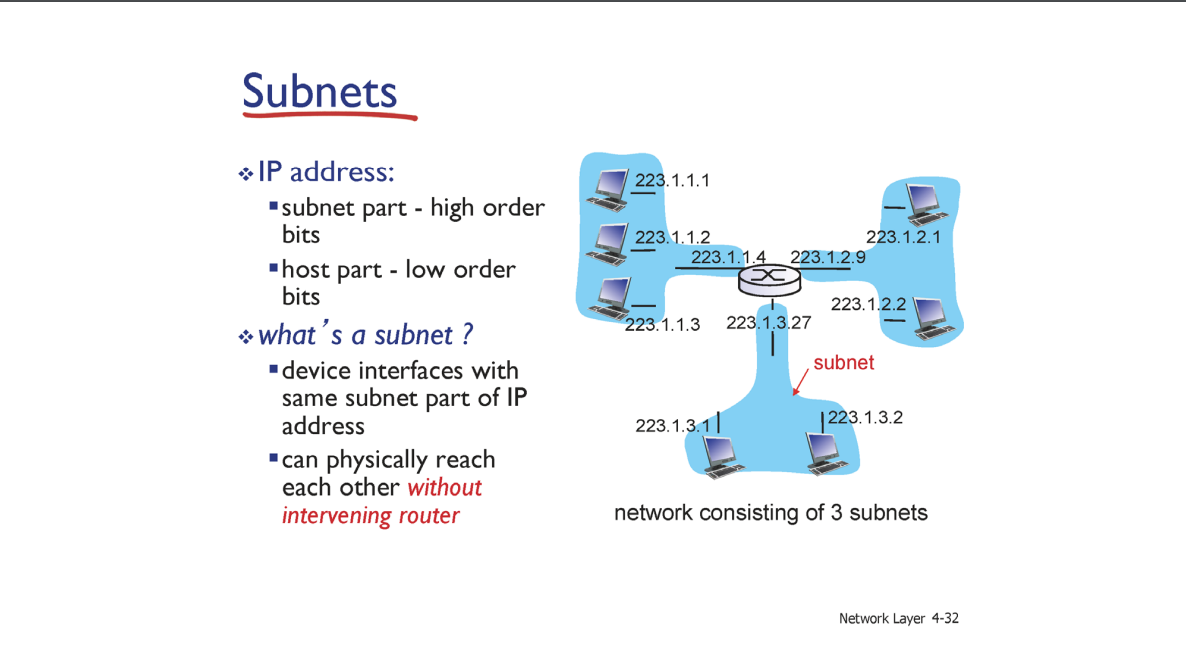
Subnet 이란 라우터를 거치지 않고 접근 가능한 호스트들의 집합을 의미한다.
생각해보면 prefix 를 칭하는 Subet 을 보면 prefix 는 같은 로컬 응집성을 갖는 호스트들이 공통적으로 갖는 주소이다.
그렇다면 각 Subnet 들을 잇는 Router 의 prefix 는 어떨까 ?
Router 는 여러개의 네트워크 소켓을 갖고 있기 때문에 각기 다른 prefix 를 가진 네트워크를 가진다.
위 예시를 보면
223.1.까지는 맞는거 아닌가 .. 싶은데223.1까지 같은건forwarding하기 위해 갖는Router만의 주소체계일 뿐 각기 다른Subnet들과prefix는 다르다.
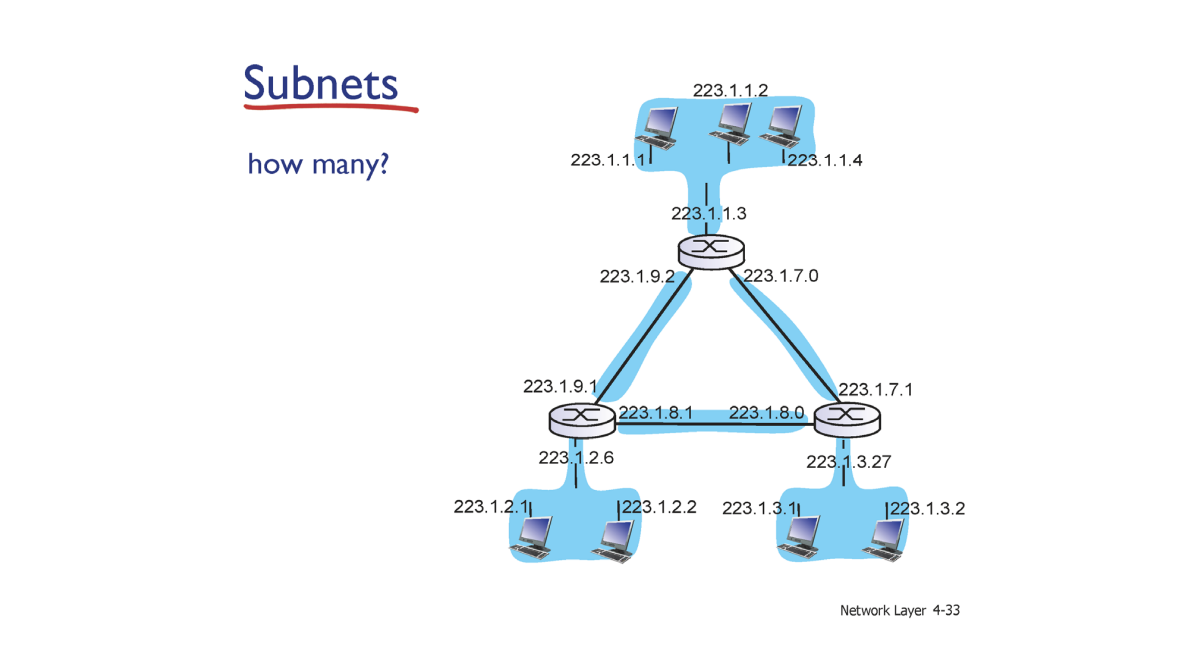
다만 라우터끼리도 다른 라우터를 거치지 않더라도 같은 prefix 를 갖지 않기 때문에 Subnet 이라 할 수 없다.
Network Translate

IP v4 는 32bit 의 주소 체계를 갖는다고 하였다.
이 때 개 이상의 네트워크가 전 세계에 존재 할 수 있다. (약 40억개)
하지만 전세계의 네트워크의 개수는 개 이상 일 수 있다.
생각해보자 클라이언트와 서버 뿐 아니라 라우터들도 IP 주소를 갖기도 하고 한 클라이언트가 여러개의 디바이스를 가질 수 있기 때문이다.
그래서 IP v6 도 개발됐었다. 무려 주소 공간이 개나 갖는 주소 체계를 말이다. (전 세계의 모래알 개수보다 많다고 한다.)
그래도 여전히 IP v4 를 사용한다.
왜 ? 쌈@뽕한 재활용 기법이 존재하기 때문이다.
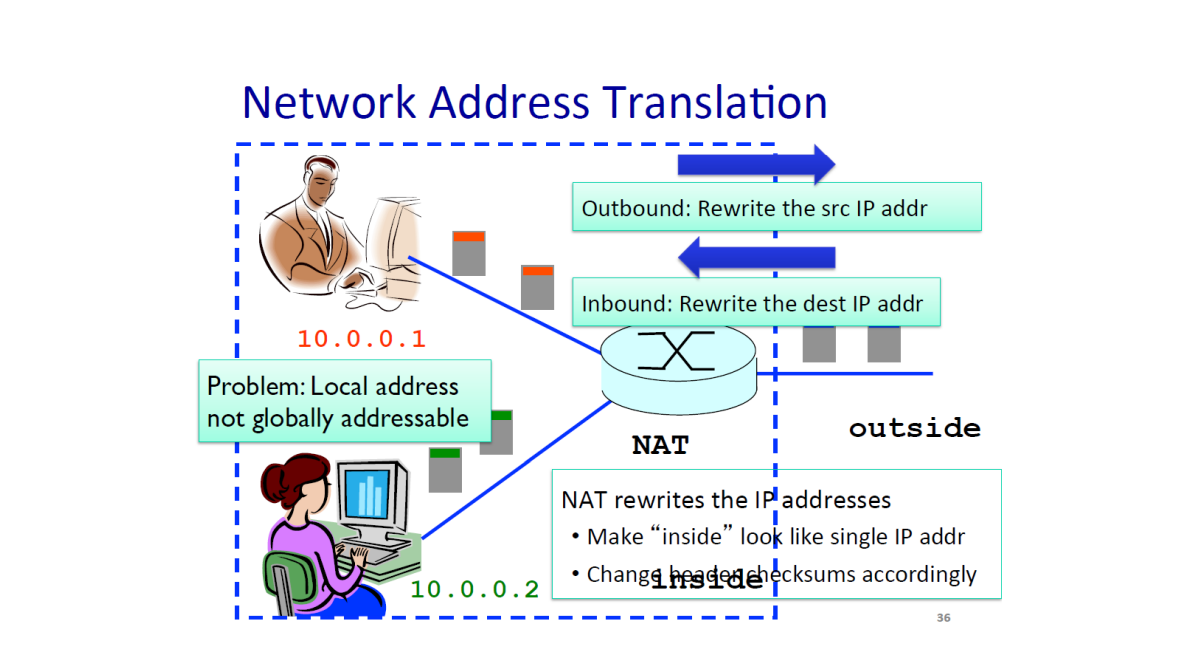
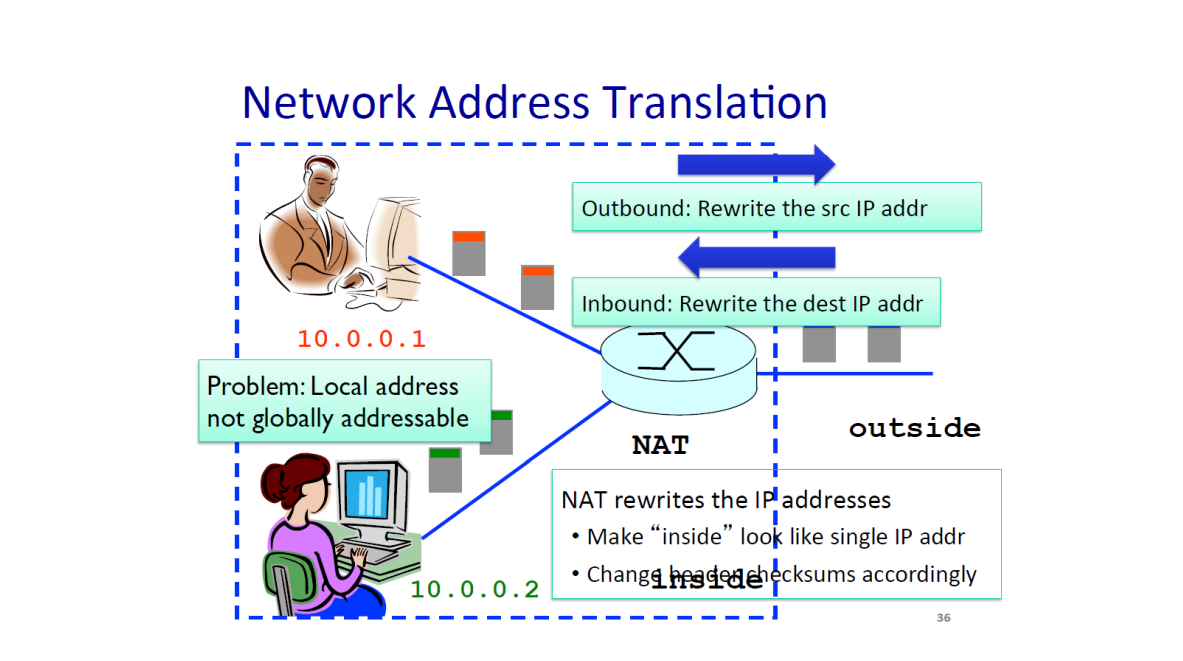
Network Address Translaton (NAT) 를 이용하여 각 호스트들은 , 가장 최근의 Router 이전까지만 서로 유니크하면 된다.
이에 같은 지역에 존재하는 Host 들 끼리만 서로 다른 아이피 주소를 갖도록 하고
Router 를 통해 다른 지역으로 이동 할 땐, 다른 IP 주소로 변경하여 네트워크를 통하도록 한다.
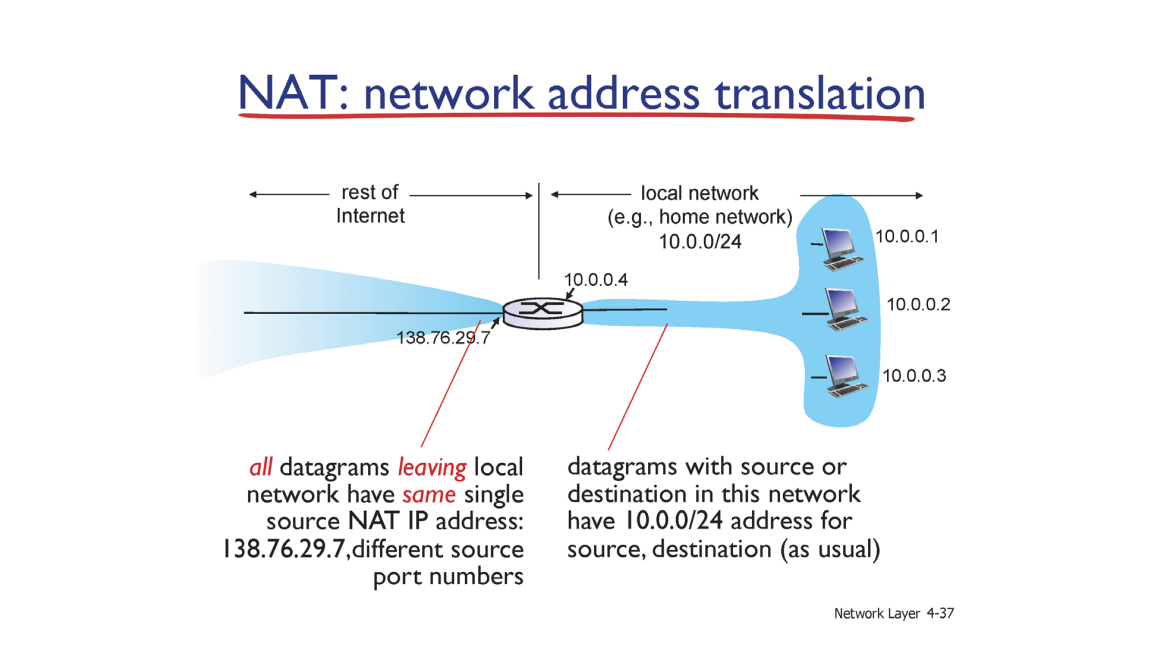
즉 , inbound , outbound 할 때 IP address 를 변환하여 사용한다는 것이다.
Router 까지는 변환된 IP 주소를 이용하고 Router 에서 Host 로 이동 할 때는 Host 를 가리키는 IP 주소와 포트번호를 이용해 식별한다.

하지만 생각해보자 , IP Address translation 을 한다는 것은 상위레이어에서 지정한 IP Address 를 변경하는 layer biolation 이 일어난 것이다.
또한 Server 측 입장에선 NAT 를 사용 할 수 없다. 왜 ?
Server는 프로토콜 별 지정된Port번호를 이용해야 한다.Server의IP address는 항상 일정해야 하기 때문이다.Server는 클라이언트의IP Address를 통해 보안이나 문제가 있을 경ㅇ를 대비해야 하는데NAT는 추적을 어렵게 한다.- 그리고 어차피 서버의
Socket과 클라이언트는 1:1 연결인데,NAT를 이용해도 라우터와 서버는 1:1 연결이다. 그렇게 하기보단 그냥 클라이언트와 1:1 연결을 하는 것이 낫다.
