강의 링크 : http://www.kocw.net/home/m/cview.do?cid=6166c077e545b736
회고

인터넷의 구성 요소
- edge : 서버와 클라이언트
- core : 라우터
인터넷은 circuit 기반이 아니라 packet 기반의 통신 방법을 쓰며
서버와 클라이언트는 packet단위로 데이터를 보내고 라우터에선 packet을 독립적인 단위로 처리하여 전송한다.
문제가 되는 상황은
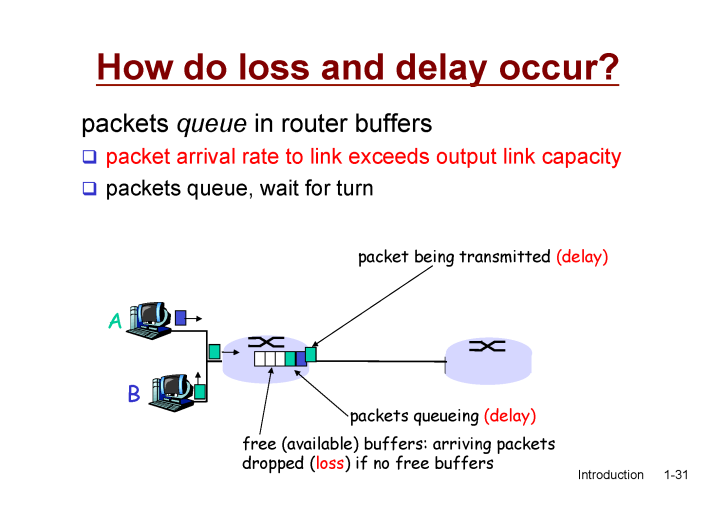
시간적으로 라우터가 처리 할 수 있는 용량보다 많은 packet이 들어올 경우 문제가 발생한다.
그럴 경우엔 임시 공간에 packet 을 둬 처리 할 수 있을 때 까지 기다림 (queueing delay)
만약 buffer 에도 용량이 없을 경우엔 유실이 발생한다.(packet loss)
라우터는 packet 을 받으면 헤더 정보를 보고 보낸 곳, 받을 곳에 대한 정보를 확인한다.
packet이 라우터의 버퍼에 들어와서 가장 앞까지 이동하는 딜레이 (queing delay)- 라우터의 버퍼의 맨 앞에서 링크까지 도달해 전송되기 까지 (
packet의 시작부터 끝까지) 보내지는 딜레이 (transmission delay) 가 존재한다.
Aplication layer
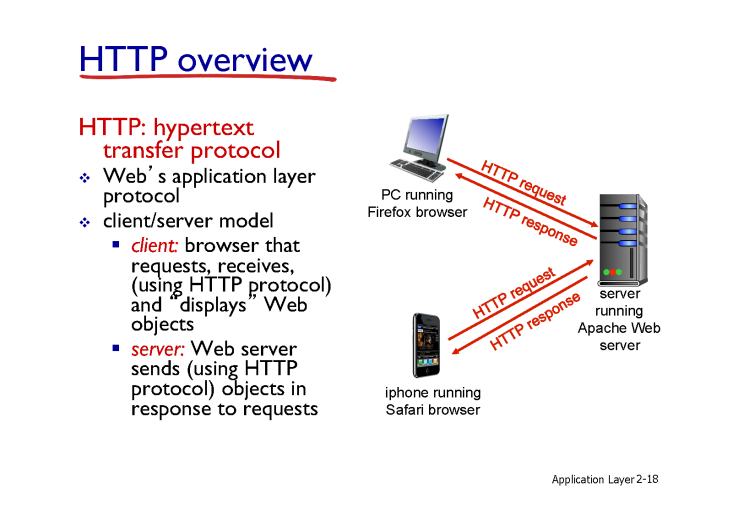
HTTP 프로토콜은 단순하게 request , response 로 이뤄지며
클라이언트가 서버에게 request 를 보내면 서버는 response 를 보내며 packet을 전달한다.
두 커넥션은 TCP 통신을 이용하여 데이터의 무결성을 유지한다.

HTTP connection 은 서로의 TCP 연결을 데이터를 주고 받을 때 마다 새로 연결하는 non-persistent HTTP 가 있고, 통신이 끝날 때 까지 연결을 유지하는 persistent HTTP 가 존재한다.

그렇다면 서버와 클라이언트의 통신이 걸리는 시간은 얼마나 될까 ?
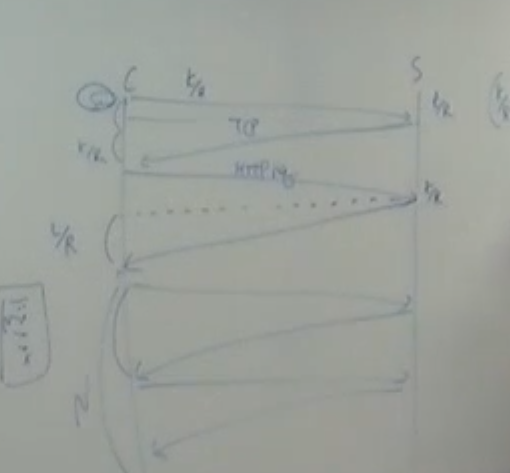
- 통신이 시작 될 때
3 way handshaking을 한다.- 첫 번째 통신에서 클라이언트는 서버에게
SYN bit : 1과보내고자 하는 Seq#를 보낸다. - 두 번째 통신에선 서버가 클라이언트에게
SYN bit : 1과보내고자 하는 Seq#를 보낸다. + 클라이언트가 보낸SYN bit 와 Seq# 에 대한 ACK를 보낸다. - 세 번째 통신에서 클라이언트가 서버에게로부터
SYN bit , Seq# 에 대한 ACK와
첫 번째packet이 서버 측으로 전송된다 .
- 첫 번째 통신에서 클라이언트는 서버에게
handshaking이 끝났으면 클라이언트는 서버로부터N개의 요소가 있는HTML요소를 받는다.
그러면 클라이언트는 서버에게N번의request를 보낸다.- 서버는 클라이언트측에게 서버로부터
N개의 요소들을response를 보낸다.
추가 공부 할 내용
DNS따로 더 공부하기
Transport layer
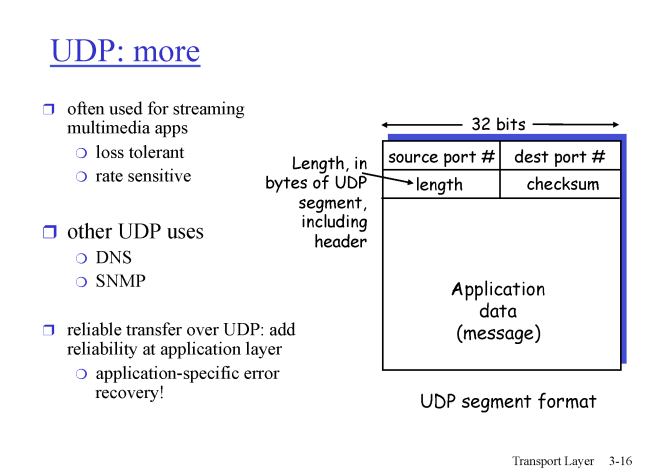
UDP
UDP 는 데이터의 완전성을 보장하지 않지만 빠르게 전송한다.
헤더 영역에는 source port , dest port , length , checksum 이 존재하여 보내는 측과 받는 측의 port # 를 통해 데이터를 전송한다.
이 때 UDP 는 기본적인 오류를 checksum 을 통해 확인하고 , multiplexing , demultiplexing 을 지원한다.
multiplexing , demultiplexing
Aplication layer측에서는 메시지 단위로 데이터를 보내는데 이를Transport layer에서 프로세스 별로 받은 데이터를packet단위로 하나의 세그멘테이션을 만들어 전송하는 것이multiplexing이라 한다.
multiplexing을 통해 다양한 프로세스가 동시에 데이터를 전송 할 수 있다.받은 측에서 하나의 세그멘테이션인
packet을 적절한 프로세스에게 분할하여 전달 하는 것이demultiplexing이라 한다.packet안에 들은 데이터 별로dest port#가 존재하기 때문에 적절한 프로세스에게 데이터를 분할하여 전송 할 수 있다.
추가 공부 해야 할 것
UDP 는 언제 사용될까 ?
TCP 통신

TCP 통신은 Reliable Data Transfer를 보장한다.
packet error: 서버측이 기대하는packet이 아닌 다른packet을 전송 받은 경우
- 어떻게 확인하나 ?Error detection ,feedback: 서버측은 클라이언트로부터 받은packet을 이용해 다음에 받을packet의 넘버를ACK #로 보낸다.ACK#가 아닌 다른packet을 전송 받은 경우엔 잘못된packet이 온거니packet errorretransmission, seq#: 클라이언트 측에선 서버로부터 받은feedback을 토대로ACK#에 맞는packet을 재전송 한다. 또한feedback을 위해 클라이언트는 서버에게packet을 보낼 때 해당packet의seq#를 같이 보낸다.
packet loss:recevier측에서 받기를 기대하는packet이 오지 않는 경우
- 어떻게 확인하나 ?Timeout:sender가 보낸packet의 seq#에 대하여receiver에게로부터ACK#가 일정 시간 오지 않을 경우packet loss로 간주
Timeout이 발생하면sender는 해당packet을retransmission한다.
Real world TCP protocol
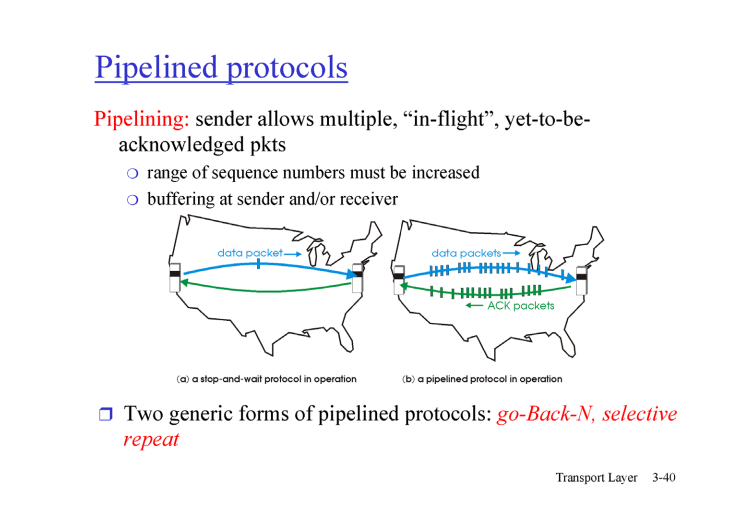
Reliable Data Transfer 를 하기 위해서 하나의 packet 을 전송하고 feedback 을 받는 것은 너무나 오랜 시간이 걸려 실세계에서는 Pipelined protocol 을 사용한다.
Pipelined protocol
여러 개의 패킷을 동시에 전송하고, 수신 측에서도 여러 개의 패킷을 동시에 받아 처리하는 프로토콜
여러개의 packet 을 주고 받기 위한 두 가지 방법이 있는데 그것은 go-Back-N , Selective repeat 가 존재한다.
Go-Back-N
센더는 리시버에게 보낼 여러가지의 packet 을 순차적으로 보내며, 보내는 packet 의 수를 window size라고 한다.
sender 가 보낸 window에 맞춰 receiver 는 ACK 를 보낸다.
이 때 recevier가 보내는 ACK 는 cumulative ACK를 보낸다.
sender가 보내는seq#는window에 존재하는 첫 번째 패킷의seq#
recevier가 보내는ACK#는 다음에 받기를 기대하는 첫 번째 패킷의seq#
sender 는 ACK# 를 받고 안받고 상관없이 시간에 맞춰 우루루 패킷을 보낸다.
이 때 packet error , loss 가 발생 할 경우 발생한 packet # 에 맞춰 윈도우를 재구성하고 해당 윈도우부터 재전송을 시작한다.
장점으로는 구현이 매우 단순하지만 단점으로는 loss , error 가 발생했을 시 이미 전송한 패킷들도 다시 재전송 해야 하기 때문에 오버헤드가 심함
Selective Repeat
Selective Repeat 를 구현하기 위해서 양 측 모두 sender buffer , recevier buffer가 존재한다.
recevier는 sender 로 부터 받은 packet들을 담는 recevier buffer 를 구성하고 받은 packet 들을 차례로 recevier buffer에 담는다.
패킷이 유실되지 않고 모두 전송 받았을 경우엔 recevier buffer에 담긴 패킷들을 프로세스에게 전달하고
유실된 경우엔 유실된 부분만 retransmission 받아 프로세스에 전달한다.
전달 후에는 window size 에 맞춰 recevier buffer 가 이동한다.
유실된 패킷에 대해서만 재전송 받으면 되기 때문에 오버헤드가 적다.
하지만packet별로 타임아웃을 가져야 하고, buffer 가 존재해야 하기 때문에 메모리적 단점이 존재한다. 구현도 복잡하다.
하지만 오버헤드의 위험이 적다.
TCP : Overview
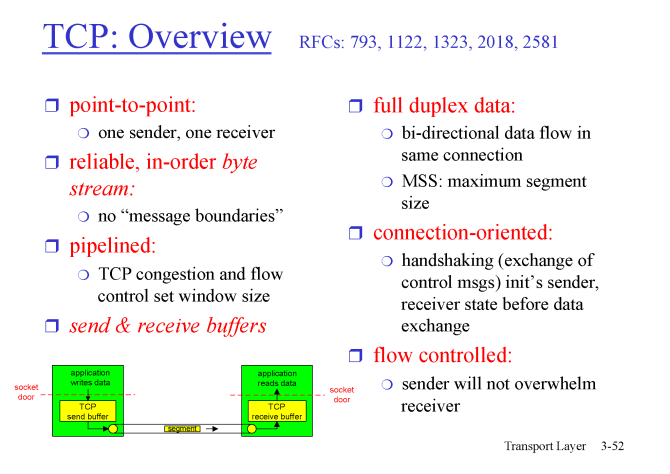
point to point: header 부분에source , dest #뿐이 아니라port #도 있어 소켓별로 독립적으로 1:1 연결이 된다.reliable:feedback을 통해error , loss를 해결하기 때문에 데이터 전송이 신뢰성 있다.pipelined:packet을 우루루 쏟아 부음full duplex data:sender , recevier가 단방향이 아닌 서로 양방향으로 데이터를 전송함connection-oriendted: 연결을 통해 서로의buffer를 연결함flow controlled: 데이터를 주고 받을 때 서로의 상황에 맞게flow를 조절함
TCP segment structure
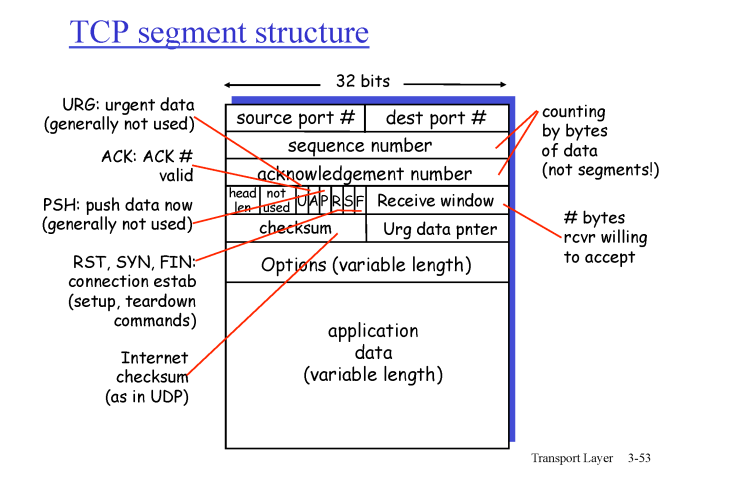
source port # , dest port # 외에도 서로 피드백을 위한 seq # , ACK# 가 존재하고 3-way-handshaking을 위한 SYN bit 가 존재한다.
3-way-handshaking이후엔SUYN bit : 0
또한 받을 수 있는 window size를 담기 위한 recevie window가 존재함
flow-control을 위함
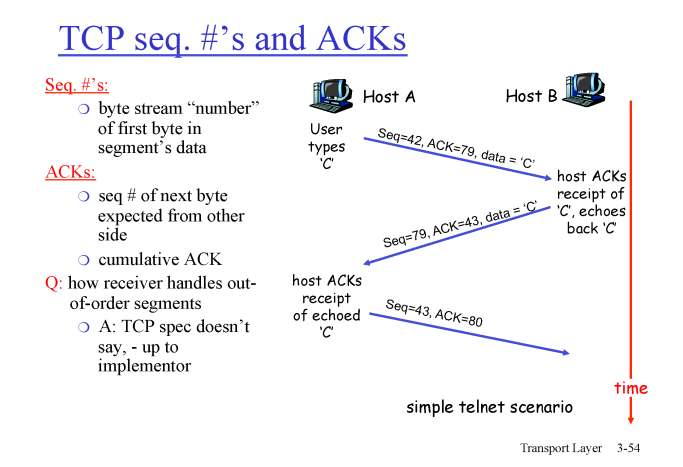
ACK 는 cumulative ACK 이기 때문에 받은 Seq# 에 다음 Seq# 를 ACK로 보낸다.
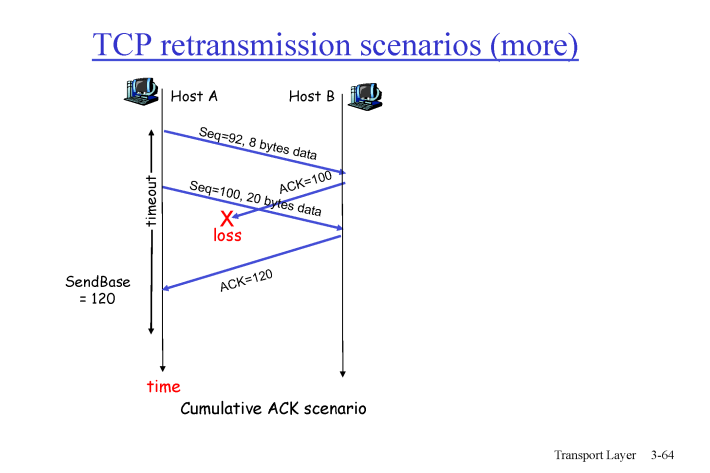
cumulative ACK 에 해당하지 않은 Seq# 가 오면 리시버는 패킷을 받지 않고 받고 싶은 ACK 만 보낸다.
-> 이를 통해 packet loss , error 를 판단한다.
Fast Retransmit

timeout 이전 동일한 ACK 가 몇 번 이상 날라오면 어떤 패킷이 유실되었음을 의미하는 거다.
그렇기에 동일한 ACK 가 몇 번 이상 날라오면 재전송하는 매커니즘
TCP congestion control
flow control 할 때는 recevier 의 buffer 의 수용 공간에 따른 컨트롤이 있다.
recevier가ACK를 보낼 때ACK뿐이 아니라수용 가능한 buffer도 보내져 거기에 맞춰flow control
이 때 리시버의 버퍼 뿐이 아니라 네트워크의 혼잡도에 따라서도 congestion control 을 시행해야 한다.
처음 센더가 리시버에게 데이터를 보낼 때의 메커니즘은
-
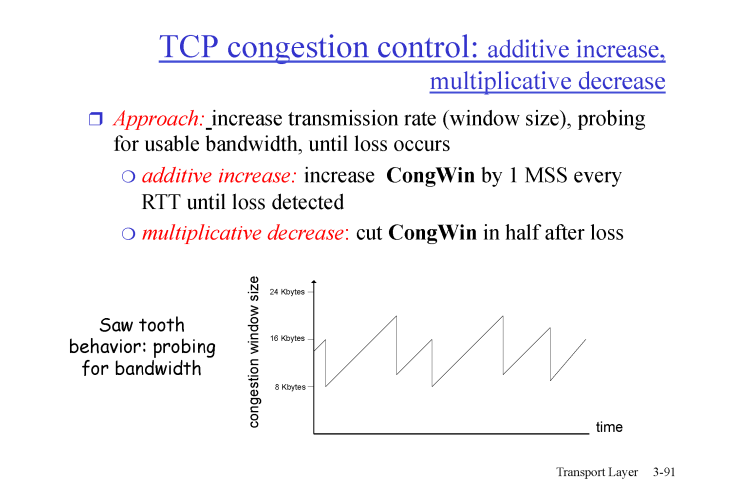
임계점까지 매우 낮은 윈도우 사이즈로 패킷을 보내기 시작해 지수적으로 증가시킨다.
이 때의 윈도우 사이즈를
MSS(Maximum segment size)라고 한다. -
임계점 이후부터는 패킷 로스가 일어날 때 까지 선형적으로 보낸다.
-
패킷 로스나 에러가 발생할 경우 다시 1번으로 돌아간다.
- 돌아 갈 때 임계점은 로스나 에러가 발생한 경우의 1/2 로 낮춘다.> 기하급수적으로 늘릴 임계점을 낮춰야 네트워크의 혼잡을 낮출 수 있다.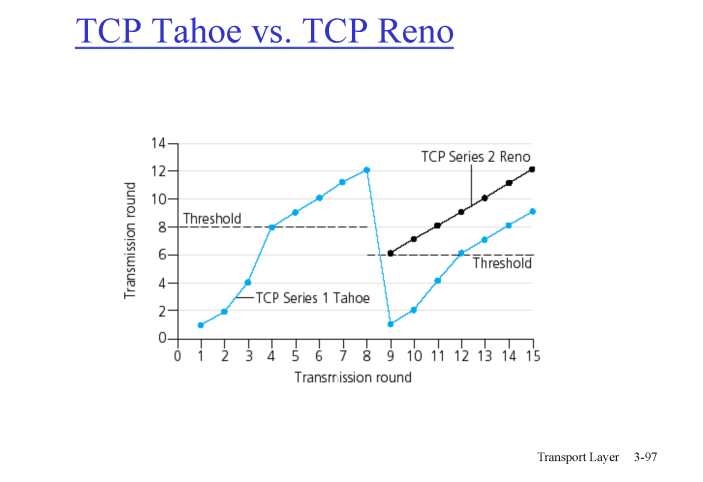
이 때 timeout 이 발생한 경우엔 네트워크의 혼잡이 심하기 때문에 1번으로 돌아가야 한다. 그것이 TCP Tahoe
만약 동일한 ACK 가 3번 이상 발생할 경우엔 네트워크의 혼잡이 심한 것은 아니지만 문제가 있는 것이기에 낮춘 임계점부터 시작하여 패킷을 윈도우 사이즈를 선형적으로 증가시키며 전송한다. 그것이 TCP Reno

Network Layer

여태 application layer , transport layer 가 어떻게 작동하는지에 대해서만 알 수 있었다.
그 안에서 어떤 경로로, 어떻게 작동하는지에 대해서는 몰랐지만 network layer에 대한 내용을 통해 자세히 알아 볼 수 있다.
어떻게 보낼 것이고, 오류가 났을 때는 어떻게 일어나는가에 대한 내용을 배울 예정이다.
IP (Internet protocol)에 대해서 배워보자
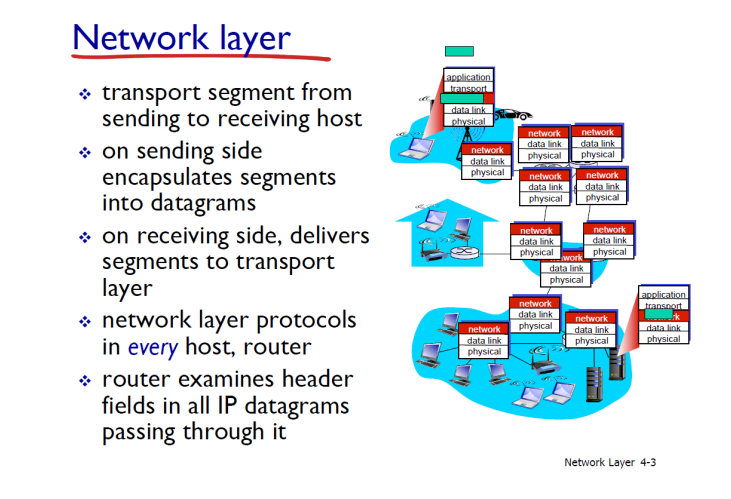
네트워크 엣지끼리의 통신은 네트워크 코어에 존재하는 라우터들을 통해서 데이터 전송이 일어난다.
여태까지의 설명은 선형적으로 데이터가 전송되는 것으로 보였지만 사실은 복잡한 라우터들을 통해 전송한다.
Two Key network-layer function
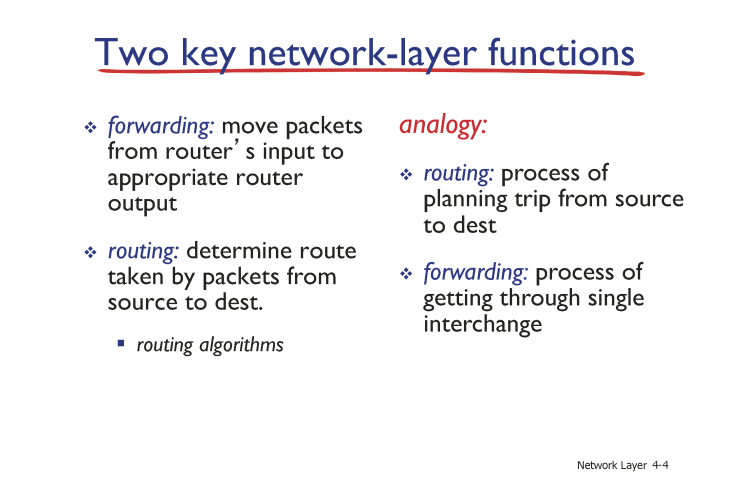
그림을 보며 확인하자
Interplay between routing and forwarding
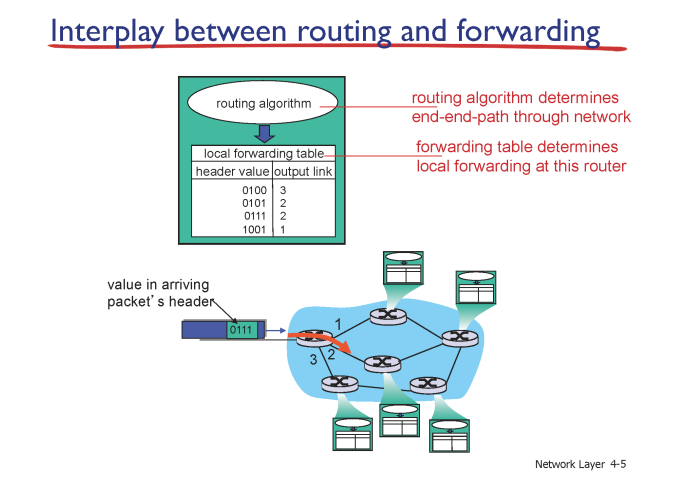
결국 라우터에서 하는 일은 패킷이 들어오면 dest port# 까지 전달하는 것이다.
들어온 packet header 에는 dest #가 적혀있다.
라우터가 할 일은 단순히 두가지다.
- 목적지를 확인한다.
- 목적지까지 가기 위한 루트를 판단한다.
어떻게 판단하는데 ?- 라우터 안에 테이블(
forwarding table)이 존재한다. (목적지까지 가기 위한 루트 [몇 번의 인터페이스를 통과해라]) - 위 이미지에서 들어온 패킷이 dest#가 0101 이라면 2번 라우터로 전달하면 된다.
- packet 의 목적지와 라우터의 테이블을 보고 아웃 링크를 결정하는 것을
forwarding이라고 한다.
- 라우터 안에 테이블(
라우터는 죽을 때 까지
forwarding만 하는거야 ~
그럼 그 forwarding table 은 어떻게, 누가 만드는데 ?
바로 routing algorithm 을 통해 forwarding table 을 만드는 것이다.
Datagram forwarding table
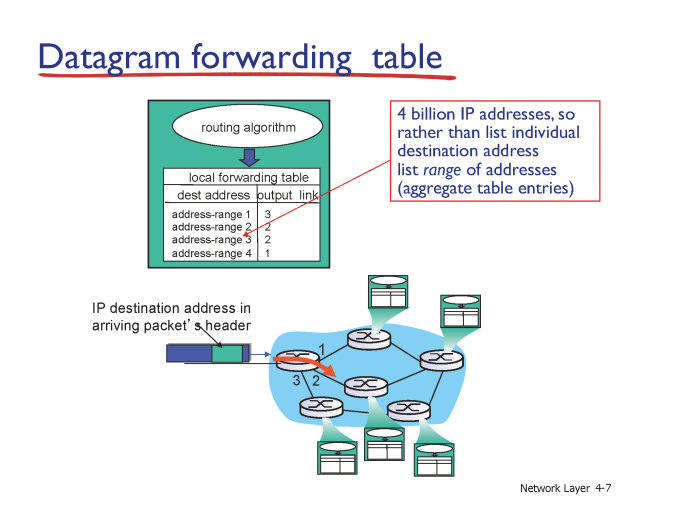
dest # 까지 일일히 하나하나 table 을 생성하면 너무나도 많은 양의 table이 생성 될 뿐 아니라 탐색에도 많은 시간이 걸린다.
그렇기 때문에 forwarding table 은 세세한 table 이 아닌 범위를 통해 두루뭉실하게 테이블을 구성한다.
어떤 범위부터 어디까진 몇번 링크, 어떤 범위부터 어디까진 몇번 링크 ... 이렇게
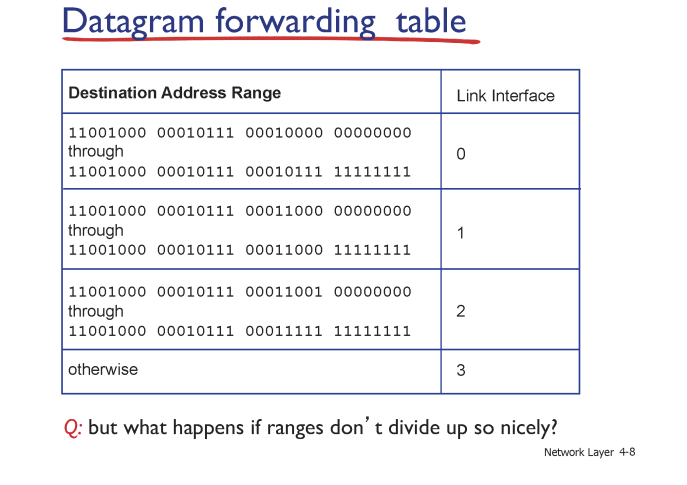
이런식으로 말이다.
Longest prefix matching

비트로 되어 있는 IP 주소가 있을 때 예시를 통해 살펴보자
***로 되어 있는 것은 앞에 있는 주소가 동일하면,*로 표기된 곳의 번호는 뭐가 됐든 상관 없다는 것이다.
첫 번째 DA 는 0번 링크, 두 번째 DA는 1번 링크로 들어간다.
만약 어떤 링크에든 매칭이 될 경우엔 가장 유사한 , 가장 길케 매칭이 되는 것 으로 보낸다.
이를 Longest prefix matching 이라고 한다.
