리다이렉션이란 리소스를 요청한 서버가 아닌
다른 서버로부터 리소스에게 제공을 받는 것을 의미한다.
제공받기 위해 다시 요청을 보내기도 한다.
그럼 이런 리다이렉션은 왜 필요할까 ?
- 서버의 부하로 인한
HTTP통신 장애를 예방하여 신뢰 할 수 있는HTTP트랜잭션을 수행하기 위해 - 지연을 최소화 하기 위해
- 네트워크 대역폭을 절약하기 위해
이러한 문제들을 해결하기 위해 이전 챕터에서 보았듯
서버들은 동일한 리소스를 가진 많은 서버들을 서버팜 형태로 가지고 있다.
리다이렉션의 주 과제는 부하균형이다.
리다이렉션 프로토콜의 개요
이후 설명할 내용들을 간략하게 살펴보자
리다이렉션의 목표는 HTTP 메시지를 가급적 빠르게 부하가 적거나 빠른 통신이 가능한 웹 서버로 보내는 것이다
이를 위한 방법으로
- 브라우저에서는 클라이언트의 메시지를 자동으로 프록시 서버로 보내도록 설정한다.
DNS는 원 서버의 주소가 아닌 동일한 리소스를 가진 다른 서버의 주소를 준다.- 라우터들은 요청을 동적으로 리다이렉션하기 위해 라우팅 한다.
- 웹 서버 자체에서 클라이언트를 다른 서버로 리다이렉트 시킨다.
일반적인 리다이렉션 방법
HTTP 리다이렉션
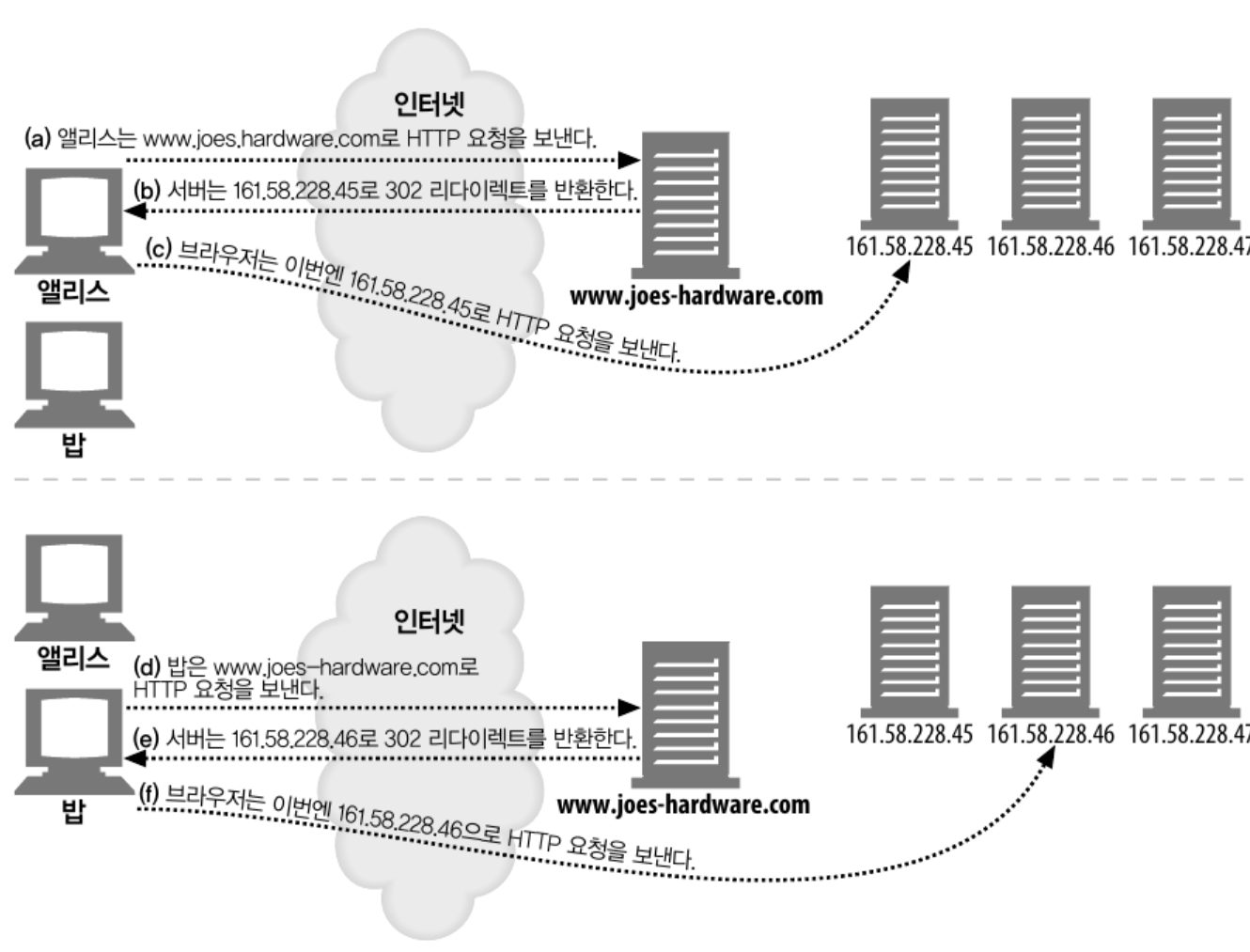
HTTP 리다이렉션은 HTTP 를 이용하여 클라이언트의 요청을 리다이렉션을 시키는 방법이다.
예를 들어 원서버에 요청을 보낸 리소스를 클라이언트가 요청하였을 때
원 서버는 리소스를 보내기 보다 상태코드 302 와 함께 부하가 적은 서버의 주소를 보낸다.
그럼 클라이언트는 부하가 적은 다른 서버에게 요청을 보낸다 .
이러한 HTTP 리다이렉션은 몇 가지 단점이 존재한다.
- 원서버는 어떤 서버로 리다이렉션 시킬지 결정해야 한다.
- 페이지에 접근 할 때 마다 두 번의 왕복이 필요하기 때문에 사용자가 더 오래기다려야 한다.
- 만약 리다이렉트 서버가 고장나면 사이트도 고장난다.
이러한 약점 때문에 보통 몇몇개의 다른 리다이렉션 기법과 함께 조합하여 사용한다.
DNS 리다이렉션
DNS 는 하나의 도메인에 여러 아이피 주소가 결부되는 것을 허용한다.
리다이렉션이 가능한 여러 서버 주소들을 DNS 에 등록해놓음으로서
하나의 서버가 아닌 여러 서버로 요청을 분산 시키는 방법이 있다.
때마침
DNS에 대한 내용을 어제 공부하였다 !
DNS 조회(DNS Lookup)
그럼 여러개의 서버들을 어떻게 이용하여 클라이언트들의 요청을 분산 시킬까 ?
DNS Round Robin
라운드 로빈은 가장 단순한 방법으로 요청은 서버 리스트의 가장 앞의 서버가 처리하고 서버가 요청을 처리 할 때 마다 서버 리스트의 가장 마지막으로 돌아간다.
이는 평균적인 서버들의 부하 정도를 동일하게 하는 것이 가능하다 .
DNS Caching
Round Robin 방법은 부하를 순환시킨다는 장점이 존재하지만
요청마다 서버가 변환하기 때문에 클라이언트와의 연결을 유지하는 것이 불편하다.
커넥션 이야기가 아니라 한 클라이언트를 한 서버가 책임지는게 아닌
여러 서버가 한 클라이언트를 상대한다.
대부분의 클라이언트는 한 서버에서 번 이상 리소스를 요청한다.
그래서 대부분의 서버는 한 클라이언트를 담당하는 서버가 존재하는 것이 더 편하다.
클라이언트의 정보를 관리하는게 편해진다.
그로 인해 DNS Caching 을 이용한다. DNS Caching 은 클라이언트와 연결된 서버를 기억하고 해당 클라이언트가 재이용 할 때는 이전에 이용했던 서버와 연결 시킨다.
손님 전용 서버 대령하겠습니다
라운드로빈과 DNS Caching 을 함께 사용하여 평균적으로 부하를 모든 서버에 잘 분산 시킬 수 있다.
부하 균형 알고리즘
부하 균형 알고리즘은 웹 서버의 부하 수준을 판단하고 로드가 적은 웹 서버를 서버 리스트의 가장 앞단에 둔다.
이를 통해 DNS 에서 서버의 주소를 요청 할 때 가장 부하가 적은 서버를 제공 할 수 있다.
근접 라우팅 알고리즘
웹 서버의 팜들이 지리적으로 분산되었을 경우 DNS 는 클라이언트 근처의 웹 서버로 보내는 시도를 할 수 있다
CDN~~
결합 마스킹 알고리즘
네트워크의 건강 상태를 모니터링 하고 요청을 네트워크 장애에 따라 피해서 라우팅을 할 수 있다.
일반적으로 서버 추적 알고리즘을 실행하는 경우
서버의 부하 수준을 통해 라우팅
여러 서버들의 장애 수준을 관리하는 authoriative server 가 존재하며
해당 서버가 부하나 장애 수준에 따라 DNS 주소를 관리한다.
이는 단점이 존재하는데
authoriative server 를 이용하면 클라이언트의 주소는 신경쓰지 않고 오로지 서버들의 주소와 부하수준만으로 판단하여 주소를 제공한다는 점이다.
임의 캐스트 어드레싱
이번엔 여러 지리적으로 흩어져있는 다양한 서버들이 모두
다른 IP 주소가 아닌 동일한 IP 주소를 가지고 있는 임의 캐스트 어드레싱이다.
이는 클라이언트 측에 가까이 있는 백본 라우터의 최단거리 라우팅 능력에 의지한다.
서버는 1.1.1.1 이란 주소로 요청을 보내면 해당 요청은 백본 라우터에게 향하고
백본 라우터는 본인과 가장 가까이 있는 1.1.1.1 서버에게 요청을 보낸다.
어떻게 이런 것이 가능할까 ?
그것은 라우터는 라우팅 테이블에서 조건에 부합하면서 가장 자신과 가까운 라우터와 연결되기 때문이다.
그렇기에 여러 서버들은 백본 라우터에게 자신을 라우터라고 속여
라우팅을 받는다.
아이피 맥 포워딩
라우터를 지나는 패킷은 여러 계층들의 출발지와 목적지 주소를 가지고 있다.
예를 들어 TCP/IP 레이어가 이해 할 수 있는 포트 번호와 IP 주소를 가지고 있으며
Physical / Data 레이어가 이해 할 수 있는 Media Access Control,(MAC) 주소등을 가지고 있다.
이 때 MAC 주소와 포트 번호를 통해
특정 MAC 에서 온 패킷이면서 포트 번호가 80 번인 패킷들은 (HTTP 통신) 다른 곳으로 포워딩 시키는 방법이 존재한다.
포워딩 시키는 주체는 서버에서 준비한 포워딩 기능을 수행하는 스위치다.
단점이 존재하는데 이는 점 대 점으로만 가능하기 때문에 포워딩받을 서버는 포워딩 시키는 스위치와 한 홉 거리에 위치해야 한다는 것이다.
점대점이라는 것과 한 홉 거리 ?
- 점대점이란 중간에 통하는 다른 라우터 없이 1:1로 대응되어야 한다는 것이다.
- 한 홉 거리라는 단위는 패킷이 이동할 때 들르는 라우터의 개수가 하나라는 것이다.
아이피 포워딩
아이피 포워딩은 MAC 과 포트 번호가 아닌
출발지와 도착지 IP 만을 이용해 포워딩 한다.
아이피 포워딩이 아이피 맥 포워딩보다 좋은 점은 몇 홉 거리든 상관이 없다는 점이다.
다만 아이피 포워딩을 사용하기 위해서는 라우터 대칭성을 지켜야 한다.
HTTP 1.0 이후부터는 TCP Connection 을 지속적으로 유지 시키는 것이 가능하기 때문에
스위치를 지나 연결된 클라이언트와 원 서버는 항상 스위치를 지나 연결되어야 한다.
클라이언트는 현재 스위치와 커넥션을 맺고 있고 서버 또한 스위치와 커넥션을 맺고 있기 때문이다.
커넥션을 유지시키기 위한 방법은 두 가지 존재한다.
완전 NAT
NAT (Network Address Transformation) 은 패킷의 출발지와 도착지 주소를 변경하는 것을 의미한다.
패킷의 출발지와 도착지 주소를 변경함으로서
서버는 패킷을 스위치로 보낼 수 있다.
하지만 이는 출발지의 주소가 클라이언트의 주소가 아니기 때문에 클라이언트의 주소를 알 수 없다는 단점이 존재한다.
반 NAT
Half NAT 는 도착지의 주소만 변경하고 클라이언트의 주소인 출발지 주소는 변경하지 않는다.
이렇게 되면 서버는 클라이언트의 주소를 획득 할 수 있다.
하지만 이는 커넥션 유지를 위해 스위치와 서버 사이에
스위치를 지나는 경로가 아닌 다른 더 빠른 경로가 존재하면 안된다.
만약 존재한다면 서버의 패킷은 스위치를 지나지 않고 다른 라우터들을 통해 클라이언트에게 향할 것이다.
네트워크 구성요소 제어 프로토콜
네트워크 구성요소 제어 프로토콜은
패킷을 전달하는 라우터나 스위치와 같은 네트워크 구성 요소들과 (NE, (Network Element)) 리소스를 제공하는 웹 서버나 프록시 캐시와 같은 SE (Sever Element) 들이 대화하는 프로토콜을 의미한다.
부하 균형을 유지하기 위해 NE 와 SE 는 지속적으로 통신을 주고 받고
통신 결과에 따라 리다이렉션 한다.
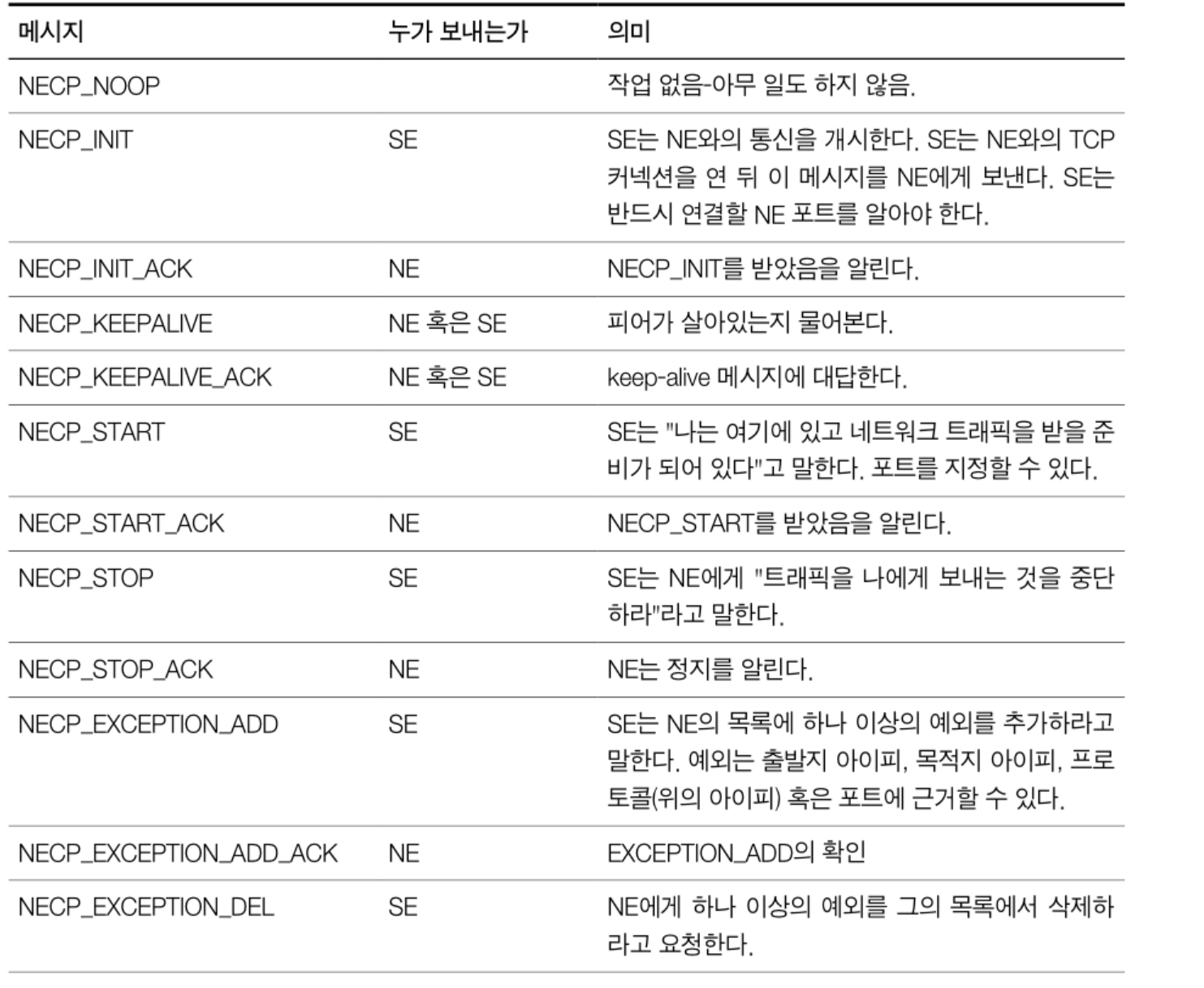
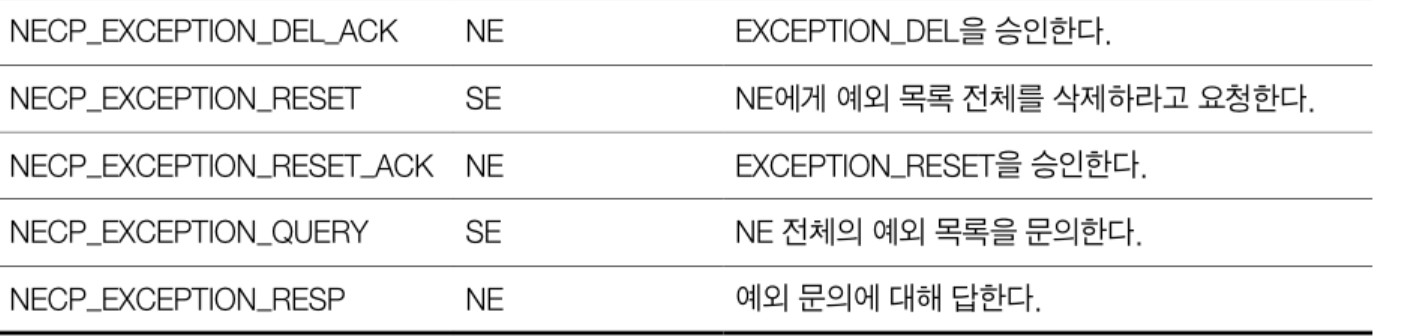
다음은 통신에 사용되는 메시지, 누가 보내는가, 의미에 대한 테이블이다.
캐시 리다이렉션 방법
캐시 리다이렉션 방법은 라우터들과 캐시들 사이의 대화를 관리하여 라우터가 캐시의 상태를 검사하고 특정 트래픽을 캐시 서버에 보낸다.
WCCP 리다이렉션
WCCP (Web Cache Communication Protocol) 는 라우터와 캐시 서버들이 서로 통신 할 수 있도록 설정하고
상태에 따라 트래픽을 분산시킨다.
WCCP 를 지원하는 그룹을 설정하고
그룹은 라우터들과 캐시 서버들로 구성된다.
캐시서버는 꾸준하게 라우터에게 자신의 트래픽 상태를 알리고 (heart beat)
라우터는 설정값에 따라 캐시서버에게 트랙션을 포워딩 한다.
이 때 라우터는 캐시서버에 패킷을 보낼 떄 포워딩을 위해 패킷을 한 번 더 캡슐화 한다.
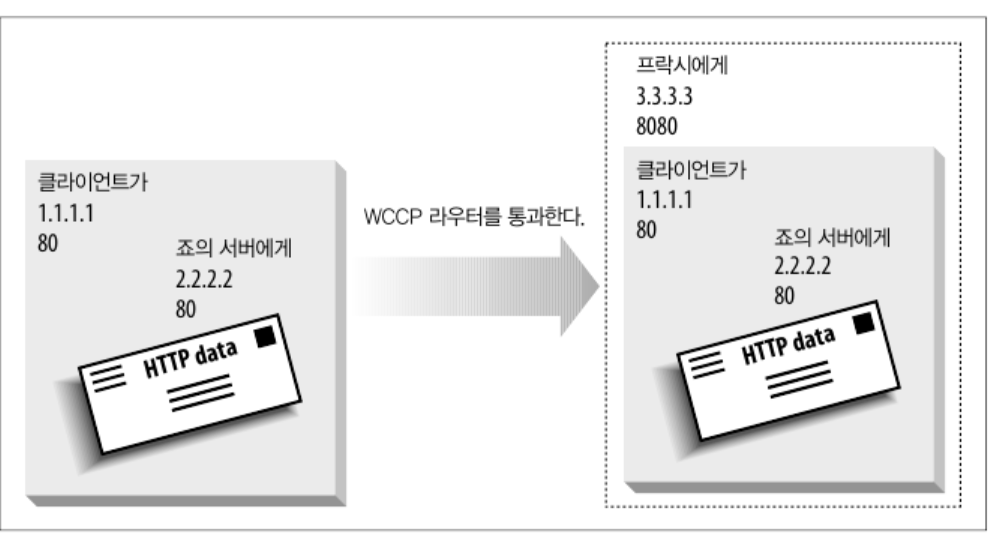
이러한 캡슐화를 GRE (Generic Router Encapsulation) 이라 한다.
라우터에서 캐시 서버로 보내진 해당 패킷은 캐시 서버에서 처리 가능할 경우에는 처리하고
처리 불가능 할 경우엔 원 서버로 포워딩 하기 위해 돌아온다.
원서버로 돌아올 때는 캡슐화되지 않은 패킷을 보낸다.
캐시서버는 라우터들에게 지속적인 통신을 보내 본인이 살아있음을 꾸준하게 알리며
만일 이런 heart beat 가 수신되지 않을 경우 라우터는 캐시서버가 트래픽이 몰린 것으로 간주 , 트래픽을 보내는 행위를 당분간 끊을지에 대한 연락을 한다.
인터넷 캐시 프로토콜
ICP (Internet Cache Protocol) 는 캐시들이 형제 캐시들이 일어난 캐시 적중을 찾아볼 수 있도록 한다.
요청을 받은 캐시 서버는 본인 뿐이 아닌 형제 캐시 서버들에게도 질의를 하며
캐시가 적중된 형제 캐시서버가 존재한다면 형제 캐시 서버와 HTTP Connection 을 맺는다.
본인이 존재할 경우엔 본인이 요청을 처리한다. 본인의 캐시가 미적중일 때 원서버로 요청을 보내는 것보다 형제 캐시에게 보내는 것이 훨씬 좋다.
캐시 배열 라우팅 프로토콜
캐시 배열 라우팅 프로토콜인 CARP 는 웹 클라이언트의 요청이 인터넷으로 가기 전
트랙션을 가로채 캐시된 사본을 제공한다.
이렇게 인터넷으로 가는 트랙션들을 가로채는 캐시 서버들은 트래픽이 늘어나 부하가 늘어날 수 밖에 없는데
이를 위해 프락시 서버를 여러대로 늘리는 것이다.
CARP 는 위에서 설명한 ICP 의 상위 버전으로
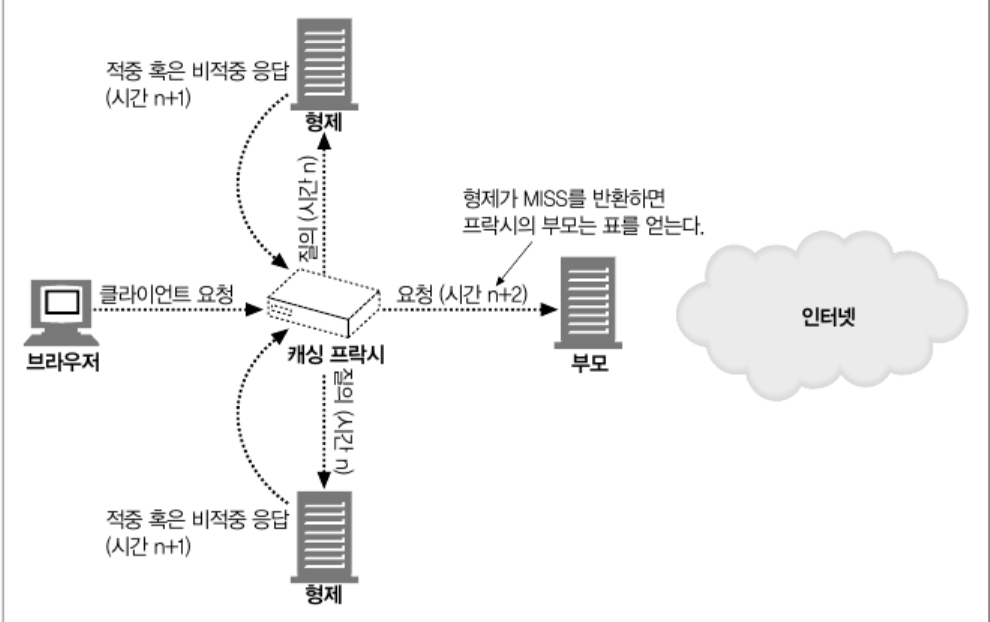
ICP 는 형제 캐시 서버에도 쿼리를 보내야 하기 때문에 응답 시간이 필연적으로 지연 될 수 밖에 없다.
이런 지연이 발생하는 이유는 모든 프록시 서버가 동일한 리소스 캐시를 가지고 있기를 기대했기 때문이다
하지만 CARP 는 특정 웹 객체들을 캐싱 할 프록시 서버를 지정해두기 때문에
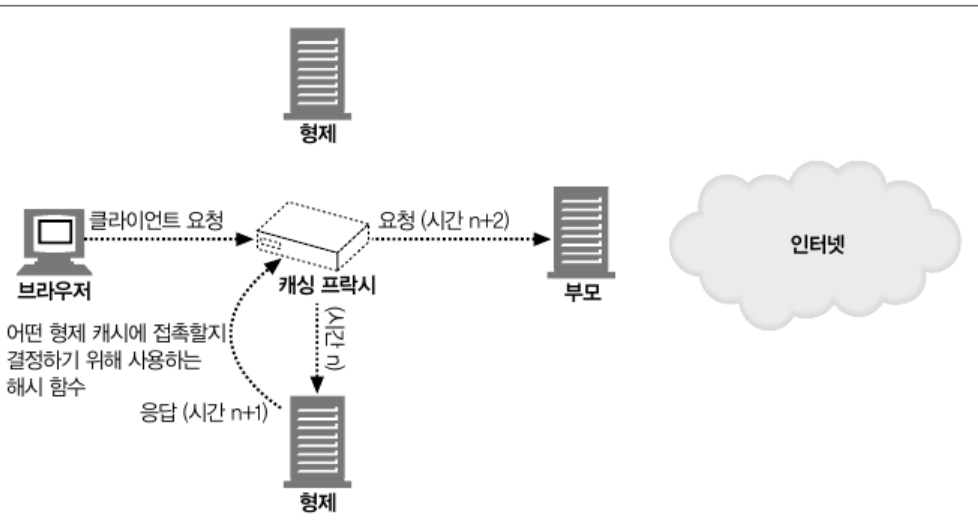
특정 웹 객체에 대한 프록시 서버에게만 질의를 하면 된다.
웹 객체와 프록시 서버는
hash function을 통해 맵핑되어 있다.
다만 이는 장단점이 존재한다.
장점
특정 리소스를 특정 프록시 서버만 캐싱하면 되기 때문에 불필요하게 동일한 리소스들을
모든 서버가 가지고 있을 필요가 없으며 질의 시간이 짧다.
단점
하지만 특정 캐시 서버의 트래픽이 늘어나면 캐시를 이용 할 수 없다.
