HTTP 요청을 통해 주고 받는 미디어 객체는
주고 받는 패킷이 올바르게 수송되고, 식별되고, 추출되고, 처리되는 것을 보장한다.
구체적으로 말하면 다음과 같은 내용을 보장한다.
- 객체는 올바르게 식별되므로 브라우저나 다른 클라이언트는 콘텐츠를 바르게 처리 할 수 있다. (
Content-Type미디어 포맷과Content-Language헤더를 이용해서) - 객체는 올바르게 압축이 풀릴 것이다. (
Content-Length와Content-Encoding헤더를 이용해서) - 객체는 항상 최신이다. (엔터티 검사기와 캐시 만료 제어를 이용해서)
- 사용자가 원하는 것을 제공 할 것이다. (
Accept관련 헤더를 이용해서) - 네트워크 사이를 빠르고 효율적으로 이동 할 것이다. (범위 요청, 델타 인코딩, 데이터 압축을 이용해서)
- 데이터는 전달되는 동안 내용이 변경되지 않고 온전히 도착 할 것이다. (전송 인코딩 헤더와
Content-MD5체크섬을 이용해서)
해당 내용들을 보장하기 위해 엔터티에 대한 내용이 잘 라벨링 되어야 할 것이며 엔터티는 잘 압축 되어야 할 것이다.
메시지는 컨테이너, 엔터티는 화물
HTTP 를 통해 정보를 주고 받을 때 packet 이라는 컨테이너 안에
엔터티의 정보를 포함한 header 영역과 엔터티를 담은 data 영역으로 나뉘어 packet 을 주고 받는다.
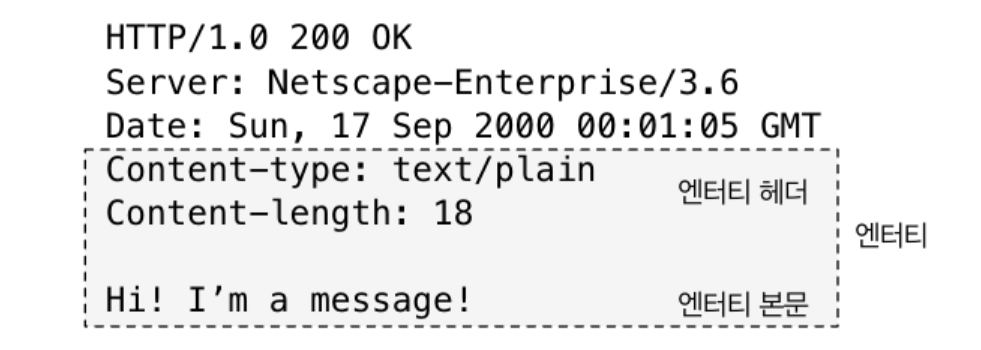
header 영역에 있는 엔터티와 관련된 라벨들을 엔터티 헤더 라고 한다.
엔터티 헤더에는 다음과 같은 헤더 필드가 존재한다.
Content-Type: 엔터티에 의해 전달된 객체의 종류Content-Length: 전달되는 메시지의 길이나 크기Content-Language: 전달되는 객체와 가장 잘 대응되는 자연어Content-Encoding: 객체 데이터에 대해 행해진 변형Content-Location: 요청 시점을 기준으로 객체의 또 다른 위치Content-Range: 엔터티가 부분 엔터티라면 전체에서 어느 부분에 해당하는지를 정의Content-MD5: 엔터티 본문에 대한 체크섬Last-Modified: 서버에서 이 콘텐츠가 생성 혹은 수정된 날Expires: 이 엔터티가 더 이상 신선하지 않을 것으로 간주되기 시작하는 날짜와 시각Allow: 해당 리소스에게 허용되는 메소드들ETag: 엔터티 태그로 인스턴스에 댛단 고유한 검사기Cache-Control: 어떻게 이 문서가 캐시 될 수 있는지에 대한 지시자
엔터티 본문
엔터티 본문은 가공되지 않은 날 데이터만을 담고 있다.
엔터티 영역에는 헤더가 아닌 데이터 그 자체만 존재 해야 한다는 듯이다 .
이에 엔터티 본문에는 엔터티와 관련된 정보를 담고 있지 않기 때문에 엔터티 헤더에서 엔터티에 대한 내용을 기술 할 필요가 있다.
엔터티 본문은 헤더 필드의 끝을 의미하는 CRLF 줄 바로 다음부터 시작한다.

Content-Length
Content-Length 헤더는 엔터티 본문의 크기를 바이트 단위로 나타낸다.
엔터티 본문의 크기를 기술하는 것은 매우 중요하기 때문에
엔터티 본문이 존재하는 모든 메시지에는 필수적으로 있어야 한다.
만약
Content-Type에 인코딩 되어charset = 인코딩 방식이 적혀있을 때에는
엔터티 본문은 인코딩 된 채로 전송된다.
이에Content-Length는 인코딩 된 엔터티 문자의 길이를 나타낸다.
데이터의 무결성을 확인하기 위해
데이터 발신자가 엔터티를 보냈을 때 18비트 길이의 데이터를 보냈으나
수신자는 10비트 길이의 데이터만 받았다면 온전한 데이터를 전달 받지 않았음을 눈치 챌 수 있다.
파싱 및 처리 & 메시지 경계 정의
HTTP 를 통해 전달받은 packet 들을 구문분석 하기 위해서는 \r\n 과 같은 공백을 나타내는 문자열(CRLF)을 통해 구문을 분석하고 \r\n\r\n (이중 CRLF) 를 기준으로 위를 헤더 , 아래를 엔터티 영역으로 구분한다.
이 때 Content-Length 에 기술된 바이트 만큼을 해당 packet 의 엔터티로 인식하고 구문분석 한다.
하지만 만약 Content-Length 가 기술되지 않았다면 엔터티 영역을 만났을 떄 몇 바이트 만큼을 해당 packet 의 엔터티로 봐야 하는지 어려움이 있다.
packet이 하나가 아니라 두 개, 세 개가 연속으로 왔다고 생각해보자
그러면 현재 엔터티와 다음 패킷의 헤더 문자열을 구분 할 수 없다 !
정리해서 말 하자면 Content-Length 가 존재하지 않을 경우 헤더와 데이터 영역 사이의 경계를 결정하기 어려워진다.
이는 패킷이 주고 받았을 때 마다 TCP Connection 을 재연결하지 않고 유지하는 HTTP 1.0 이상부터는 Content-Length 가 필수적인 이유이다.
리소스 관리
Content-Length 는 효율적인 리소스 관리에 도움이 된다 .
들어오는 엔터티 본문을 처리 하기 위한 적절한 양의 메모리를 할당 할 수 있다.
만약 Content-Length 가 없다면 메모리를 과하게 준비하여 메모리를 낭비하는 버퍼 언더플로우나 메모리가 부족하는 언더 플로우와 같은 잠재적인 문제를 방지 할 수 있다.
미디어 타입과 차셋(Charset)
Content-Type 헤더는 엔터티 본문의 MIME 타입을 기술한다.
MIME타입은 인터넷 할당 번호 관리기관에 등록된 표준화 된MIME타입이다.
/을 기준으로 좌측은 주 미디어 타입을 (텍스트, 이미지, 오디오 등) 우측에는 미디어 타입을 더 구체적으로 기술하는 부 타입으로 구성된다. (txt , img , gif 등)
Content-Type 은 엔터티가 문자열로 인코딩 되었다고 할지라도, 인코딩 되기 전의 타입을 기술한다.
멀티파트 폼 제출
Content-Type : multipart/form-data; boundary = [...] 에 대해서 알아보자
우리가 만약 HTML 태그 중 여러가지의 구분이 필요한 문자열을 서버에 전송해야 한다 생각해보자
<form
action="www.example.com/examform"
,
method="POST"
,
enctype="multipart/form-data"
>
<p>what is your naem ? <input type="text" name="submit-name" /></p>
<p>
what files are you sending ? <input type="file" name="submit-file" />
</p>
<input type="submit" value="Send" /><input type="reset" />
</form>여기서 form 태그 안에 있는 내용들을 작성하고 제출 버튼을 눌리면 form 태그 안에 있는 문자열들이 서버로 전송된다.
p태그에 적힌 글들이 전송되는 것이 아닌input태그 내에 기술된 내용들이 전송된다.
이 때 전송되는 정보들인 submit-name , submit-file 등은 구분이 되어야 하는 정보이기 때문에
전송 될 때 구분 지을 문자열을 이용해 구분하여 전송된다.
만일 누군가가 이름을 sally 라고 적고 다양한 파일들을 선택해 보냈다고 가정해보자
그러면 전송되는 엔터티는
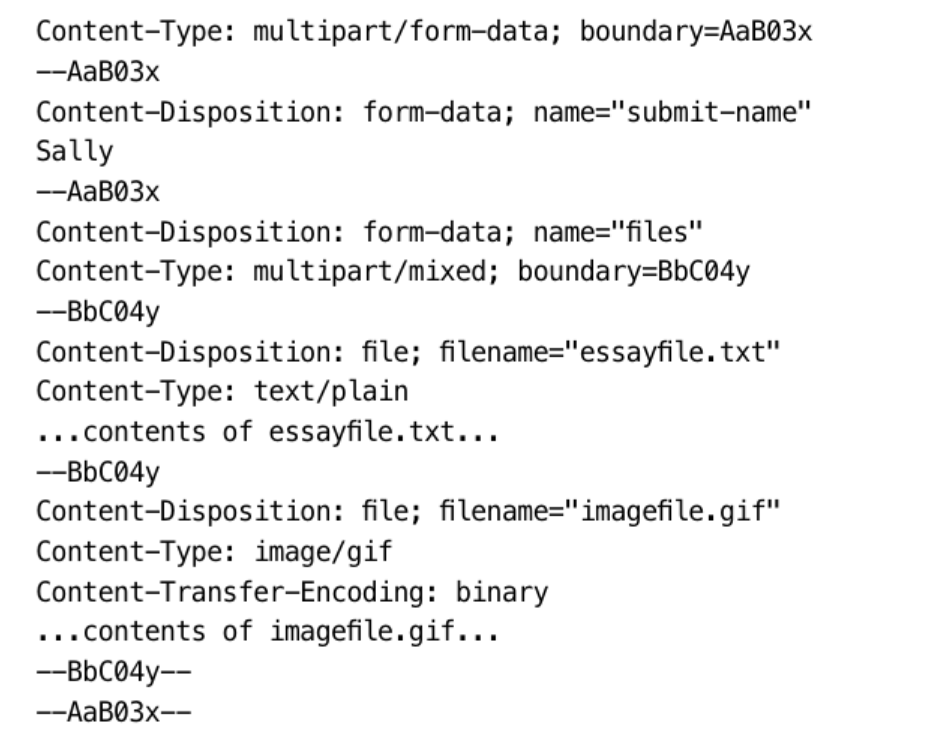
다음과 같이 Content-Type 에 multipart/form-data 라고 기술하고
구분된 문자열의 정보와 구분 문자열을 이용해 구분하여 보낸다.
콘텐츠 인코딩
packet 의 엔터티의 용량이 너무 클 경우 네트워크 대역폭을 많이 잡아먹기 때문에
엔터티를 다양한 방법을 이용해 인코딩 하여 전송하기도 한다.
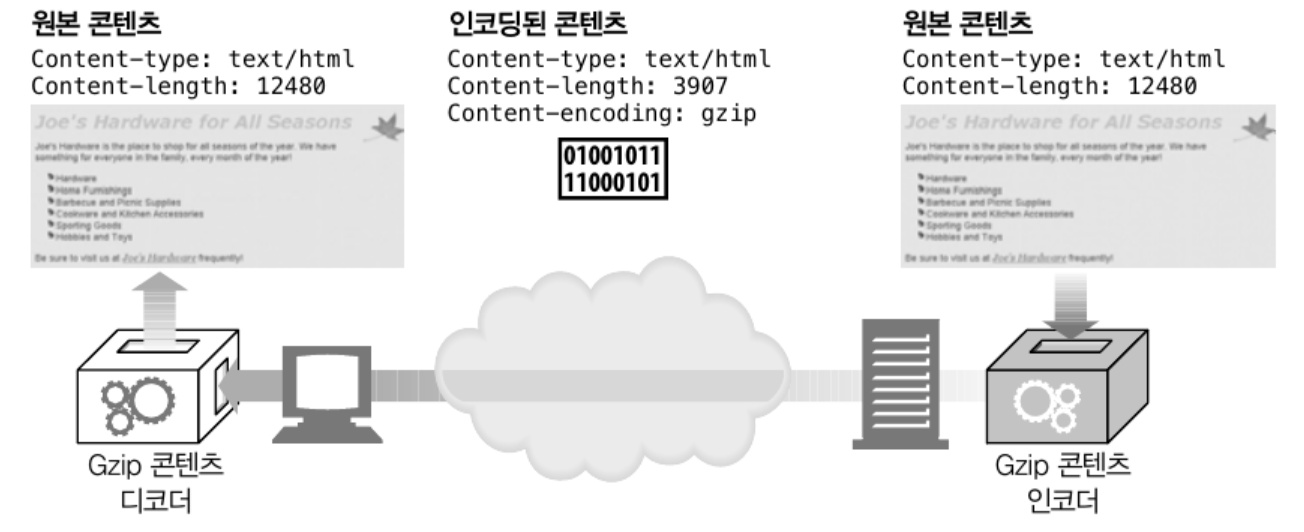
인코딩 될 경우엔 인코딩한 방식을 기술하는 Content-encoding 헤더와 Content-length 를 적어 전송하며, Content-length 는 항상 Content-encoding 이후의 길이를 기술해야 한다.
클라이언트와 서버는 데이터를 주고 받을 때 인코딩 하는 인코더와 원본 데이터로 디코딩 할 수 있는 디코더를 통과 시켜 클라이언트가 원하는 원본 데이터를 전송한다.
이 때 원할환 원본 데이터로의 디코딩을 위해선 Content-Type 이 필요하다.
즉 Content-Type 은 항상 원본 데이터의 타입을 기술해야 한다.
압축을 위한 인코딩 유형이 다양하게 많은데 가장 많이 사용되는 압축 알고리즘은
gzip인코딩 기법이다.
Accept-Encoding 헤더
만약 엔터티를 전송 할 때 인코딩 할 방식을 설정하기 위해 Accept-Encoding 헤더에 인코딩 방법을 기술 할 수 있다.
전송 인코딩 (Transfer-Encoding)
위에서는 발신자가 엔터티의 내용을 인코딩 하는 Content-Encoding 에 대해 기술했다.
Content-Encoding 을 하기 위해서 꼭 필요한 정보는 Content-Type 뿐이 아니라 Content-Length 였다.
Content-Length를 알아야 해석이 가능하니까
그런데 만약 Content-Length 가 정해지지 않는 엔터티라면 어떻게 할까 ?
예를 들어 온라인 스트리밍과 같은 경우는 엔터티의 길이가 유동적으로 계속 변한다.
이럴 때는 Transfer-Encoding 을 이용한다.
Transfer-Encoding 은 이전에 설명했던 청크 와 연관이 깊다.

Transfer-encoding : chunked 로 할 경우에는 엔터티에는 전송 될 인코딩 문자열의 바이트 수와 인코딩 된 문자열을 전송한다.
위 이미지에서
10은 청크 크기, 이후 나오는 공백은CRLF 시퀀스, 엔터티는 청크 데이터 라고 한다.
클라이언트는 Content-Length 의 역할을 해주는 숫자를 통해 받아들일 리소스의 길이를 확인 할 수 있다.
만약 다른
Content-Type과Encoding방식이 사용될 경우에는 콘텐츠 인코딩 때와 같이Content-Type , Content-Encoding헤더가 존재한다.HTTP/1.1 200 OK Content-Type: application/json Transfer-Encoding: chunked \r\n 7\r\n {"key":\r\n 8\r\n "value"}\r\n 0\r\n \r\n처럼 말이다.
정리
엔터티를 포함하는
HTTP메시지에서는Content-Length헤더를 같이 기술함으로서 클라이언트와 서버 간의 데이터 수신을 가능하게 한다.만약
Encoding이 들어갈 경우엔,Content-Encoding과Content-Type을 같이 기술함으로서 인코더와 디코더를 거친 후 원본 리소스를 받을 수 있도록 한다.만약
Content-Length를 미리 알 수 없는 경우에는Transfer-Encoding을 사용한다.
콘텐츠 인코딩과 전송 인코딩의 조합
콘텐츠 인코딩을 먼저 시행 한 후 청크를 이용하여 전송 인코딩을 같이 사용하는 것도 가능하다.
시간에 따라 바뀌는 인스턴스
웹 객체는 정적이지 않다.
우리가 www.naver.com 에 들어갈 경우 정적인 페이지가 아니라 들어갈 때 마다 페이지의 모습은 달라진다.
실시간 뉴스가 변경되거나 페이지에서 검색어 순위가 동적으로 바뀐다거나
이 때 한 홈페이지를 객체로 두고, 변하는 버전의 페이지들을 객체라고 둬보자
www.naver.com이 객체 , 3시에 들어간 페이지, 3시30분에 들어간 페이지 등이 인스턴스가 된다.
우리가 객체에 접근 할 때에는 시간에 따라 원하는 인스턴스가 다를 것이다.
HTPT 통신은 동일한 객체라 할지언정 검사기와 신선도 를 통해서 가장 신선한 인스턴스를 제공한다.
검사기와 신선도
우리가 3시에 네이버에 접속했다고 해보자
그러면 우리의 캐시 서버에는 3시에 접속했던 네이버 (인스턴스) 가 저장되어 있다.
우리가 만약 3시00분 0.0001초에 재접속을 한다면 해당 인스턴스를 캐시 서버에서 받을 수 있다.
하지만 시간이 흘러 5시에 접속한다면 캐시 서버에서는 동일한 인스턴스를 우리에게 제공할까 ?
놉
캐시 서버에서는 캐싱해둔 리소스가 현재도 신선한지 헤더를 통해 확인하고 신선하지 않다면 신선한 리소스를 서버에 요청하여 우리에게 제공한다.
간략하게 살펴보면 다음처럼 같았으며 자세히 공부해보자
신선도
서버는 클라이언트에게 리소스를 제공 하고 캐싱 할 경우, 해당 리소스가 얼마나 오랫동안 캐시해둘 수 있는지인 Expires , Cache-Control 헤더를 제공한다.
Expries에는 언제까지라고 표현하는 절대적인 시간을 포기하고
Cache-Control에는 다양한 지시자를 통해 기준을 표기한다.
Cache-Control 의 다양한 지시어들
| 지시어 | 설명 |
|---|---|
| public | 어떠한 캐시에서도 응답을 캐시할 수 있음을 나타냅니다. 이는 일반적으로 캐시할 수 없는 경우에도 가능합니다. |
| private | 응답이 단일 사용자를 위한 것이며 공유 캐시에 의해 캐시되어서는 안됩니다. |
| no-cache | 캐시에 의해 응답의 일부를 서빙하기 전에 원 서버에 대한 유효성 검사를 강제합니다. |
| no-store | 캐시가 응답 또는 요청의 어떠한 부분도 저장하지 않도록 지시합니다. |
| max-age | 캐시된 리소스의 최대 나이(초)를 지정합니다. |
| s-maxage | 공유 캐시에 대한 `max-age` 지시어를 재정의합니다. |
| must-revalidate | 리소스가 더 이상 유효하지 않을 경우 캐시가 서빙하기 전에 유효성을 검사해야 함을 나타냅니다. |
| proxy-revalidate | `must-revalidate`와 유사하지만 이는 프록시 캐시에만 적용됩니다. |
Expires 는 절대적인 시간을 사용하는데 다양한 프록시와 서버, 클라이언트들의 시간체계가 다를 수 있기 때문에 Cache-Control 의 상대적인 시간 기준을 주로 사용한다.
캐시 서버는 해당 헤더들을 통해 캐싱한 리소스 (인스턴스) 가 객체로부터 신선한지 확인하고 조건에 따라 신선한 인스턴스를 제공하거나, 새로운 인스턴스를 받아온다.
조건부 요청과 검사기
캐시 서버에서 수동적으로 신선도를 검사했다면
이번엔 클라이언트 입장에서 능동적으로 얼마나 신선한지에 대한 조건을 결정 할 수 있다.
요청 메시지헤더에 If-Modified-Since 라는 헤더를 통해
해당 헤더에 적힌 시간 이후로 수정된적 없다면 리소스를 달라며 조건부로 요청 할 수 있다
| 헤더 | 내용 | 예시 태그 |
|---|---|---|
| If-Modified-Since | 리소스가 지정된 시간 이후에 수정되었다면 리소스를 전송합니다. |
<If-Modified-Since: 날짜 및 시간>
|
| If-Unmodified-Since | 리소스가 지정된 시간 이후에 수정되지 않았다면 리소스를 전송합니다. |
<If-Unmodified-Since: 날짜 및 시간>
|
| If-Match | 지정된 엔터티 태그와 일치하는 경우에만 리소스를 전송합니다. |
<If-Match: 엔터티 태그>
|
| If-None-Match | 지정된 엔터티 태그와 일치하지 않는 경우에만 리소스를 전송합니다. |
<If-None-Match: 엔터티 태그>
|
이러한 요청이 들어오면 캐시 서버에 존재하는 검사기는
시간이나 엔터티 태그등을 이용해 캐싱해둔 리소스가 신선한지 검사하고
신선하지 않을 경우엔 원 서버에서 새로 받아오거나 클라이언트에게 에러 상태 코드를 반환한다.
범위 요청
내가 만약 서버에서 4GB 의 비디오를 다운 받다가
3.9GB 에서 요청이 중단되어 재전송을 요청해야 한다고 해보자
만약 범위 요청이 없다면 우리는 처음부터 다시 4GB 를 전송 받아야 한다.
하지만 범위 요청을 이용한다면 3.9GB 이후의 내용부터 요청을 요구 할 수 있다.
이는 Range 헤더와 재요청을 시작할 범위를 바이트 단위로 적음으로서 재전송을 요청 할 수 있다.
델타 인코딩
델타 인코딩은 리소스 중 변경된 부분만 재전송 받는 방법이다.
AJAX와 혼동되어서 생각했었는데 비슷한 개념이지만 조금 다르다.
네이버 객체에서 특정 시점의 인스턴스를 요구 할 때 페이지의 일정 부분만 수정되었을 경우
전체 인스턴스를 보내는 것이 아닌, 수정된 부분에 대한 인스턴스의 일부분만 보내줌으로서 비용을 줄인다.
델타 인코딩을 위해서는 클라이언트측에서 받을 리소스의 신선도를 명시해주고(Expires 와 같은 )
만약 신선하지 않다면 신선한 부분으로 교체해줄 것을 요청 할 A-IM 헤더를 통해 델타를 받아들이겠다는 의사를 밝힌다.
A-IM헤더는Accept-Instance-Manipulation의 줄임말이다.
"인스턴스 조작 형태를 받아들일 수 있으니 모든 인스턴스를 보내지 않고 수정한 후 굳이 다 보낼 필요 없어~!"
그렇다면 서버는 확인 후 신선하지 않을 경우, 캐싱되어 있는 인스턴스에 신선한 부분으로 수정한 후 수정된 인스턴스를 클라이언트에게 전송한다.
이 때 수정된 인스턴스는 새로운
ETag를 갖는다. 새로운 인스턴스니까 !
ETag는 엔터티 태그로 리소스를 구별하는 고유한 식별자이다. 이는 조건부 검사에서 매우 중요한 역할을 한다.
