아 .. 처음에는 술술 읽히길래 쉽다 쉬워 이러면서 읽었는데
본격적인 내용이 들어가니 상당히 맵다
맵다 매워 ...
다채로운 웹서버
웹서버는 HTTP 요청을 처리하고 응답을 제공한다.
다양한 형태와 기능의 웹서버들이 존재하지만 가장 근본적으로, HTTP 요청에 대한 리소스를 클라이언트에게 돌려준다는 점은 동일하다.
웹서버 점유율
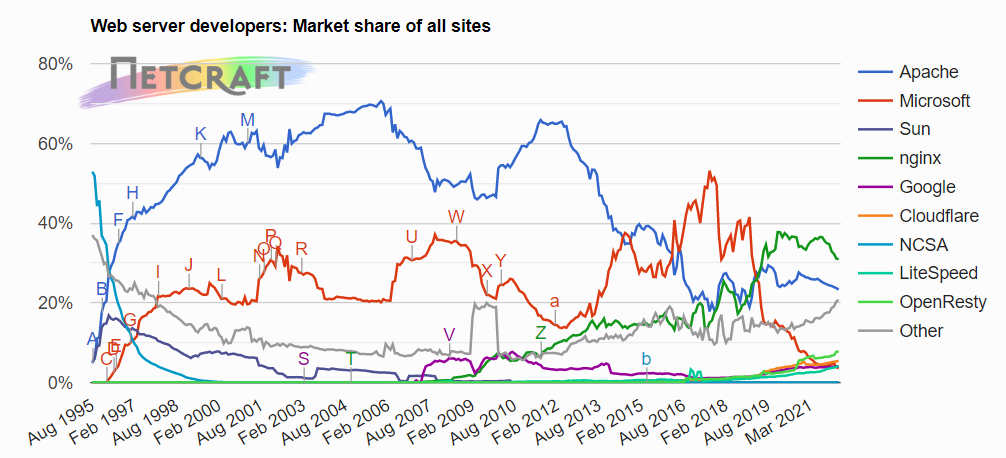
책은 2014년을 기준으로 37%는 마이크로소프트 웹서버, 35%는 아파치 웹서버, nginx 서버가 14% 였지만
2022년 기준 리서치 결과에서는 nginx , 아파치 순으로 높았다.
사실 나는 저 서버들이 무엇을 의미하는지는 모르나, 대세가 바뀌었음을 알 수 있다.
Nginx
Nginx(엔진엑스)는 높은 성능과 확장성을 갖춘 오픈 소스의 웹 서버 및 리버스 프록시 서버입니다. Nginx는 경량이면서도 많은 연결을 동시에 처리할 수 있어 웹 서버로 매우 인기가 있습니다. 주로 정적 콘텐츠 서빙, 리버스 프록시, 로드 밸런싱 등의 기능을 수행하며, 성능, 안정성, 그리고 높은 동시 접속 처리 능력이 특징입니다.
진짜 웹 서버가 하는 일
매우 복잡하지만 공통적으로 하는 일들이 있다.
-
커넥션을 맺는다.
클라이언트의 접속을 받아들이거나, 원치않는 클라이언트라면 연결을 닫는다. -
요청을 받는다.
클라이언트의 HTTP 요청 메시지를 네트워크로부터 읽어들인다. -
요청을 처리한다.
요청 메시지를 해석하고 행동을 취한다. -
리소스에 접근한다.
요청 메시지에서 지정한 리소스에 접근한다. -
응답을 만든다.
올바른 헤더를 포함한 HTTP 응답 메시지를 생성한다. -
응답을 보낸다.
응답을 클라이언트에게 돌려준다. -
트랜잭션 로그를 남긴다.
로그 파일에 트랜잭션 완료에 대한 기록을 남긴다.
이제 깊게 들어가서 공부해보자
진짜 너무 매워요
1. 커넥션을 맺는다.
1.1 새 커넥션 다루기
클라이언트가 웹 서버에 TCP 커넥션을 요청하면 웹 서버는 그 커넥션을 맺고 TCP 커넥션에서 IP 주소를 추출하여 커넥션 맞은 편에 어떤 클라이언트가 있는지 확인한다.
이후 커넥션이 맺어지고 받아들여지면 서버는 새 커넥션을 커넥션 목록에 추가하고 준비를 한다.
1.2 클라이언트 호스트명 식별
웹 서버는 역방향 DNS 를 사용하여 클라이언트의 IP 주소를 클라이언트의 호스트 명으로 변환하도록 설정되어있다.
가시적이지 못한 IP 주소들이 나열된 트랜잭션 로그를 보는 것보다 호스트명으로 변환하여 보는 것이 직관적이기 때문이다.
접근 제어와 로깅의 가시성 향상
다만 이는 웹 트랜잭션을 느려지게 할 수 있어 많은 대용량 웹 서버는 호스트명 분석을 꺼두거나 특정 콘텐츠에 대해서 꺼두기도 한다.
1.3 ident 를 통해 클라이언트 사용자 알아내기
몇몇 웹서버는 IETF ident protocol 을 지원한다.
이는 서버에게 어떤 사용자 이름이 HTTP 커넥션을 초기화 했는지 찾아낼 수 있게 해준다.
클라이언트 또한 ident protocol 을 지원한다면 클라이언트는 ident 결과를 위해 TCP 포트 113을 열어 서버와 연결을 준비한다.
이후 서버는 클라이언트가 열은 포트와 커넥션을 맺고, 클라이언트 측에게 사용자 이름을 묻는 간단한 요청을 보낸 후 응답을 수신한다.
이 또한 선택적이며 클라이언트 PC 들이
identd protocol을 지원하는 데몬 소프트웨어를 실행하지 않기도 하며 트랜잭션을 지연시켜 공공 인터넷에서는 잘 동작하지 않는다.
2. 요청을 받는다
클라이언트가 서버측에 요청을 보낼 때는
시작줄과 헤더에 요청문을 보낸다고 하였다.
서버측은 문자열의 나열로 구성된 헤더들을 파싱 하여 요청메시지를 구성한다.
파싱을 위해 요청 메시지의 각 줄바꿈은 CRLF 로 구분하며 파싱 시에는 해당 문자열을 통해 파싱한다.
요청 엔터티가 존재한다면 (post) 헤더에 정의된 content-length 만큼 읽어들인다.
content-length가 필요한 이유
정확한 본문 길이 지정
HTTP 요청은 시작줄과 헤더, 그리고 본문으로 구성됩니다. 본문은 클라이언트가 서버로 보내는 데이터를 포함하고 있습니다. Content-Length 헤더는 이 본문의 길이를 명시적으로 나타내어 서버가 정확히 얼마만큼의 데이터를 읽어야 하는지를 알 수 있게 합니다.
파싱 및 처리의 용이성
서버는 요청을 받아들일 때, 요청 헤더를 CRLF로 구분하여 파싱합니다. Content-Length 헤더를 통해 본문의 길이를 알 수 있기 때문에 서버는 정확히 얼마만큼의 데이터를 읽어야 하는지를 파악할 수 있습니다. 이를 통해 본문을 적절하게 처리할 수 있습니다.
연결의 안정성 및 지속성
Content-Length 헤더를 사용하면 서버와 클라이언트는 요청이나 응답의 끝을 정확하게 인지할 수 있습니다. 이는 HTTP 연결의 안정성과 지속성에 기여합니다. 서버는 정확한 본문의 길이를 알고 있기 때문에 연결을 계속해서 사용하거나 종료할 수 있습니다.
메모리 사용의 최적화
서버는 Content-Length 헤더를 통해 본문의 길이를 알고 있기 때문에 정확한 크기만큼의 메모리를 할당하여 데이터를 처리할 수 있습니다. 이는 메모리 사용의 최적화에 도움이 됩니다.
2.1 메시지의 내부 표현
몇몇 웹 서버는 요청 메시지를 쉽게 다룰 수 있도록 내부 자료구조에 저장한다.
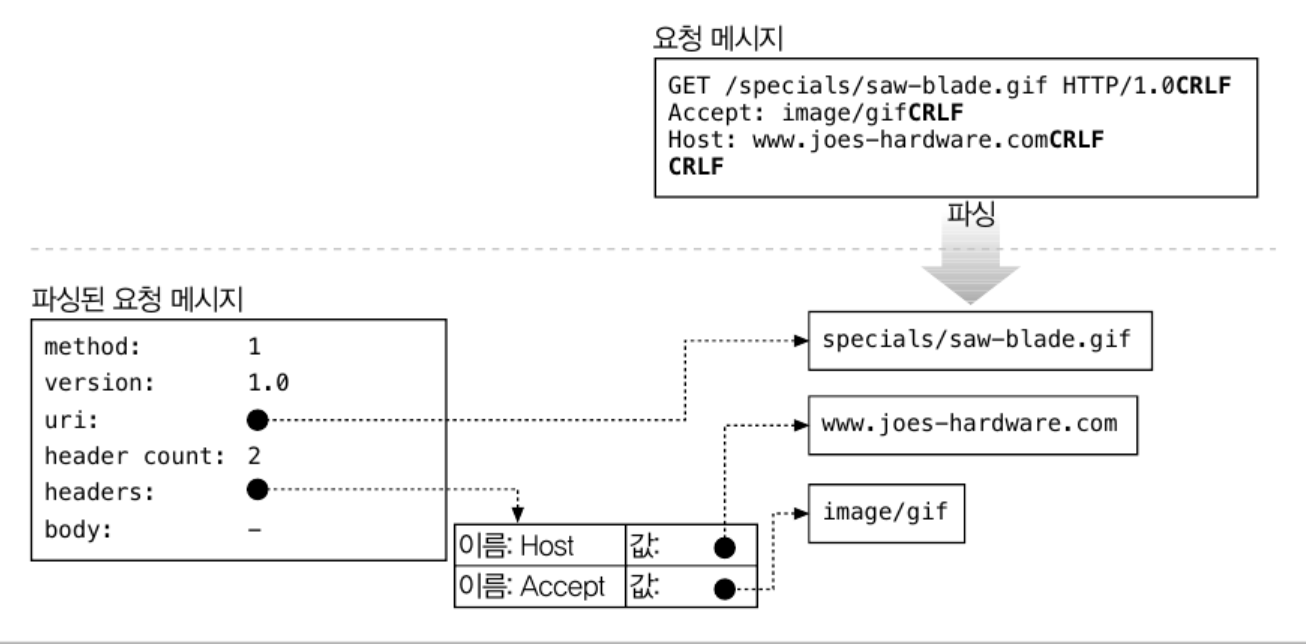
파싱한 문자열을 자료구조에 저장하여 신속하게 접근 할 수 있도록 한다.
2.2 커넥션 입력/출력 처리 아키텍쳐
고성능 웹 서버는 수천개의 커넥션을 동시에 열 수 있도록 지원한다.
하나의 웹 서버에는 수백, 수천개의 클라이언트들이 커넥션을 요청 할 것이기 때문이다.
그럼 수 많은 커넥션 요청들을 웹 서버는 어떻게 처리 할까 ?
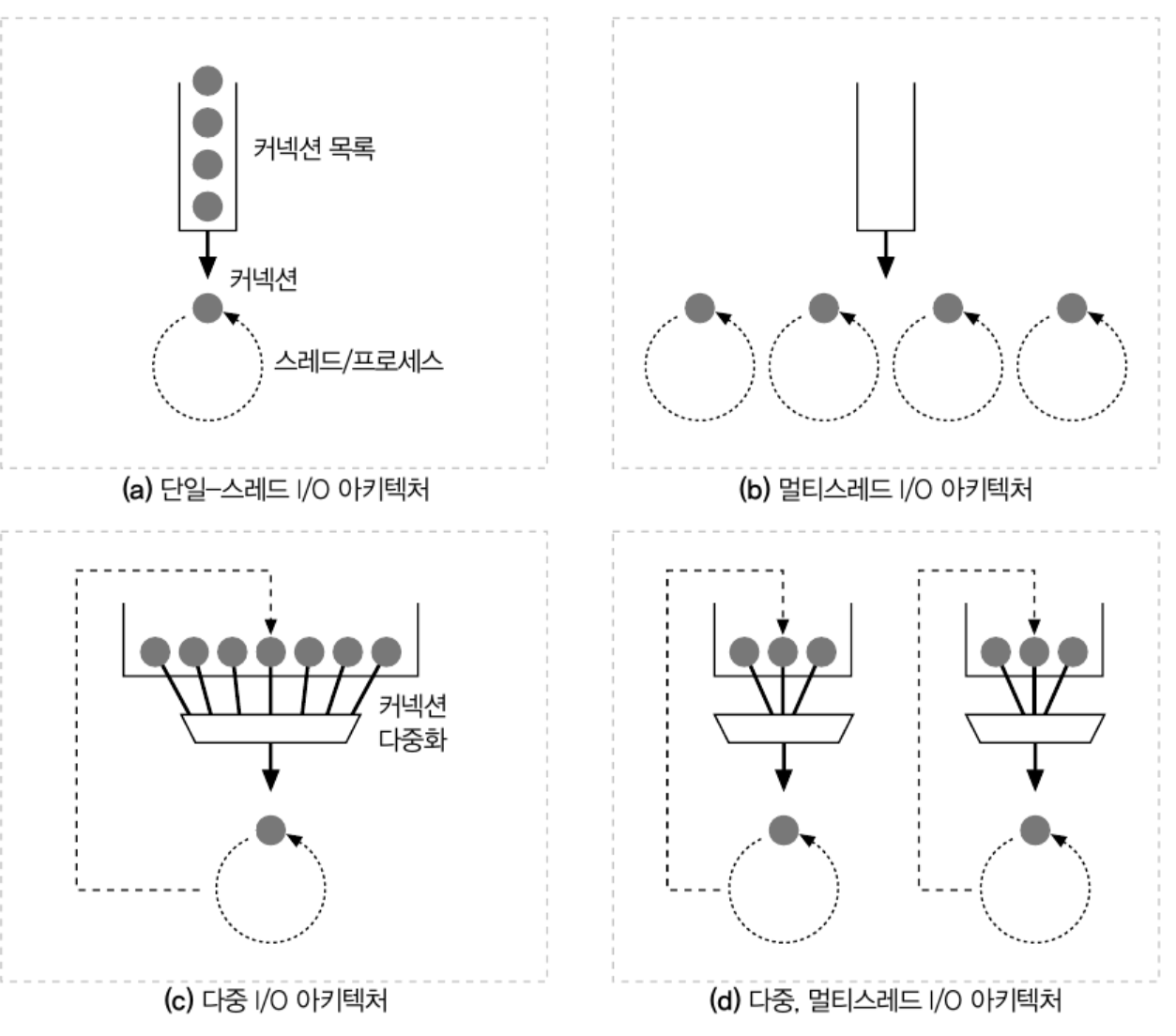
2.2.1 단일 스레드 웹 서버
단일 스레드 웹 서버는 가장 단순한 형태의 웹 서버로 한 번에 하나씩 요청을 처리한다. 트랜잭션이 완료되면 다음 커넥션이 처리된다.
처리 도중 모두 다른 커넥션은 무시된다.
이러한 단순성으로 인해 구현을 쉽지만, 성능 문제가 심각하여 로드가 적은 서버나 진단 도구에서만 적당하다.
2.2.2 멀티프로세스와 멀티스레드 웹 서버
멀티 프로세스 , 멀티 스레드 웹 서버는 여러 요청을 동시에 처리하기 위해 여러 개의 프로세스 혹은 고효율 스레드를 할당한다.
멀티 프로세스와 멀티 스레드 웹 서버는 커넥션에서 일어나는 수 많은 요청을 병렬적으로 치리 할 수 있어 빠른 속도를 지원하지만
커넥션 당 만들어지는 프로세스와 스레드는 커넥션 수가 늘어날 수록 기하급수적으로 늘어난다.
이로 인해 메모리나 시스템 리소스를 많이 소비하여, 최대 개수에 제한을 건다.
2.2.3 다중 I/O 서버 (싱글 스레드)
대량의 커넥션을 지원하기 위해 웹 서버는 다중 아키텍쳐를 채택했다.
다중 아키텍쳐에서 다수의 커넥션이 한 웹 서버에 할당되고 커넥션의 상태에 따라 처리가 수행된다.
모든 커넥션에 리소스를 할당하는 것이 아니라 필요와 상황에 따라 할당 된다는 것이다.
이를 통해 유휴 상태에 있는 커넥션에 매어 있어 리소스를 낭비하지 않는다.
2.2.4 다중 I/O 서버 (멀티 스레드)
여러 개의 스레드를 이용하여 다중 I/O 서버를 병렬적으로 처리한다.
3. 요청을 처리한다
POST , DELETE 를 제외한 대부분의 요청들은 웹 서버에게 리소스를 요구하는 메시지들일 것이다.
그럼 웹 서버는 요청을 처리하기 위해 어떻게 접근할까 ?
3.1 리소스의 매핑과 접근
웹 서버는 리소스 서버이다.
결국 클라이언트가 웹 브라우저를 통해 리소스를 요청하면 적절한 리소스를 클라이언트에게 제공하는 것이 주 목적이다.
웹 서버가 클라이언트에게 리소스를 전달하기 위해선, 요청 메시지에 담긴 URL 에 대해 대응하는 알맞은 컨텐츠나 컨텐츠 생성기를 웹 서버에서 찾아, 컨텐츠의 원천을 식별 해야 한다.
3.2 Docroot
리소스 매핑의 가장 단순한 형태는 요청 URI 를 웹 서버의 파일 시스템 안에 있는 파일 이름으로 사용하는 것이다.
ex :
www.naver.com/index.html이란 요청은 파일 시스템에서어떤 경로/index.html리소스를 달라는 것과 같다.
일반적으로 웹 서버 파일 시스템의 특별한 폴더를 웹 콘텐츠를 위해 예약해둔다.
요청에 따라 전송할 웹 콘텐츠들을 모아둔 폴더의 루트를 문서 루트 혹은 docroot 라고 한다.
웹 서버는 요청 메시지에서 URI 를 가져와 문서 루트 뒤에 붙인다.
ex :
www.naver.com/index.html이란 요청이 들어왔다.
현재index.html은sever/asset/index.html이란 경로에 존재한다면docroot는sever/asset/이다.
사용자가 요청한 리소스와 docroot 를 붙여 웹 파일 시스템에서 리소스를 찾아 매핑한다.
3.3 가상 호스팅된 docroot
한 웹서버에서 2개의 사이트를 호스팅 하고 있다면
호스팅 하고 있는 사이트 별 docroot 를 생성하여 병렬적으로 두 사이트의 리소스를 맵핑 할 수 있다.
HOST주소를 통해 어떤 사이트에서 온 요청인지 식별한다.
3.4 디렉터리 목록
웹 서버는 경로가 파일이 아닌 디렉터리를 가리키는 디렉터리 URL 에 대한 요청을 받을 수 있다.
이 때 웹 서버는 클라이언트가 디렉터리 URL 을 요청했을 때 취할 수 있는 행동이 존재한다.
디렉터리 URL 에 대한 요청 ?
기본적으로 들어오는 요청 URL 은
www.사이트주소.com/어떤 디렉터리 / 리소스.리소스확장자이런식으로 와야하지만 요청이www.사이트주소.com/어떤 디렉터리/까지만 왔을 경우를 말한다.
- 에러를 반환한다
- 디렉터리 대신 특별한 색인 파일을 반환한다.
- 디렉터리를 탐색해서 그 내용을 담은 HTML 페이지를 반환한다.
대부분의 웹 서버는 URL 에 대응되는 파일 디렉터리 안에서 index.html 혹은 index.htm 으로 이름이 붙은 파일을 찾는다.
만약 가지고 있다면 해당 파일을 반환 할 것이다.
3.5 동적 콘텐츠 리소스 매핑
이미 구현 되어 있는 파일인 정적 콘텐츠 리소스가 아니라
요청에 따라 컨텐츠를 생성하는 동적 컨텐츠 리소스도 URI 맵핑 할 수 있다.
동적 컨텐츠
동적 컨텐츠는 요청에 따라 변경되는 컨텐츠로, 서버 측에서 동적으로 생성되어 클라이언트에게 전송된다.
동적 컨텐츠의 예시
- 온라인 상점의 제품 목록
- 사용자 인증 및 프로필 정보
- 게시판 댓글 목록
사용자가 댓글을 작성하면 서버는 해당 글에 대한 최신 댓글을 생성하여 화면에 표시한다.- 실시간 채팅
- 온라인 게임 상태
- 날씨 정보
- 실시간 주식 시세
사용자 또는 시스템의 상태 , 입력, 외부 데이터에 따라 변하는 상황을 동적 콘텐츠를 통해 다룬다.
동적 컨텐츠는 웹 어플리케이션의 유연성과 상호 작용성을 향상 시키는데 사용된다.
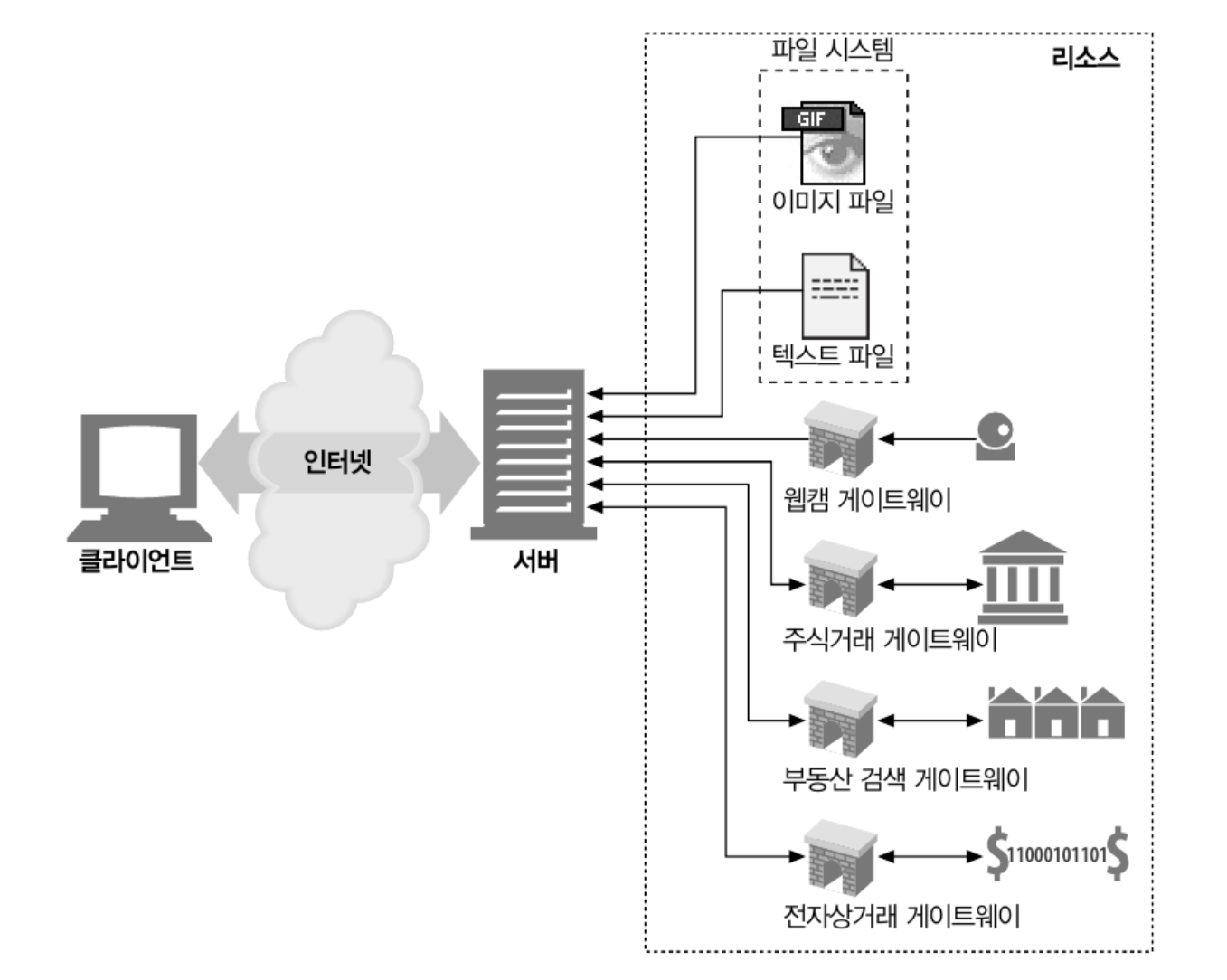
요청에 맞게 콘텐츠를 생성하는 프로그램에 URI 를 맵핑하는 것이다.
ex : 사용자가 주식 시세 요청이 발생 되어
요청 URI를 보내면
웹 서버측에서 주식 시세를 가져오는 어플리케이션과 연결 시켜 해당 어플리케이션으로 컨텐츠를 가져온다.
복잡한 백엔드 어플리케이션과 연결하는 일이 된다.
요청이 들어올 경우 데이터베이스와의 상호작용이나 외부 API 호출 등이 발생 할 수 있다.
웹 서버가 동적으로 생성한 콘텐츠를 담아 클라이언트에게 반환하면 된다.
이처럼 동적 콘텐츠 요청을 처리하여 정적 콘텐츠와 달리 요청한 시점에 따라 변하는 동적인 컨텐츠를 생성하여 제공 할 수 있다.
3.6 서버사이드 인쿨루드 (Sever-Side includes, SSI)
서버사이드 인클루드는 웹 서버에서 동적으로 웹 페이지를 생성하는데 사용되는 기술이다.
주석을 이용하여 주로 사용한다.
<!--#명령어 속성="값" -->처럼 사용하며 명령어는 특정 동작을 지정하고, 속성 = '값' 은 해당 동작에 필요한 추가 정보를 제공한다.
<h2>Welcome to My Website!</h2>
<p>This is the home page content.</p>
<p>Last modified: <!--#echo var="LAST_MODIFIED" --></p>
</section>
<!--주석을 이용해 정적인 웹 페이지에 정보를 자동적으로 넣음-->이처럼 명령어를 통해 동적으로 변하는 정보가 정적인 사이트에 자동으로 담기게 할 수 있도록 한다.
3.7 접근 제어
각각의 리소스에 따라 접근 제어를 할당 할 수 있다.
예를 들어 보안이 필요한 정보는 IP 주소에 따라 다르게 매핑하거나, 리소스에 접근 하기 위해 비밀번호를 물어보거나 하는 등 말이다.
이것은 다음에 공부해봐야겠다.
4. 응답을 만든다
서버가 리소스를 매핑하고 찾아왔다면 응답을 보낼 준비를 해야 한다.
4.1 응답 엔터티
응답 엔터티가 필요하다면 응답 메시지엔 다음과 같은 내용들이 들어간다.
- 응답 본문의
MIME타입을 서술하는Content-type헤더 - 응답 본문의 길이를 서술하는
Content-length헤더 - 실제 응답 본문의 내용
4.2 MIME 타입 결정하기
웹 서버는 MIME 타입을 나타내기 위해 파일 이름의 확장자를 사용 할 수 있다.
가장 흔한 방법이다.
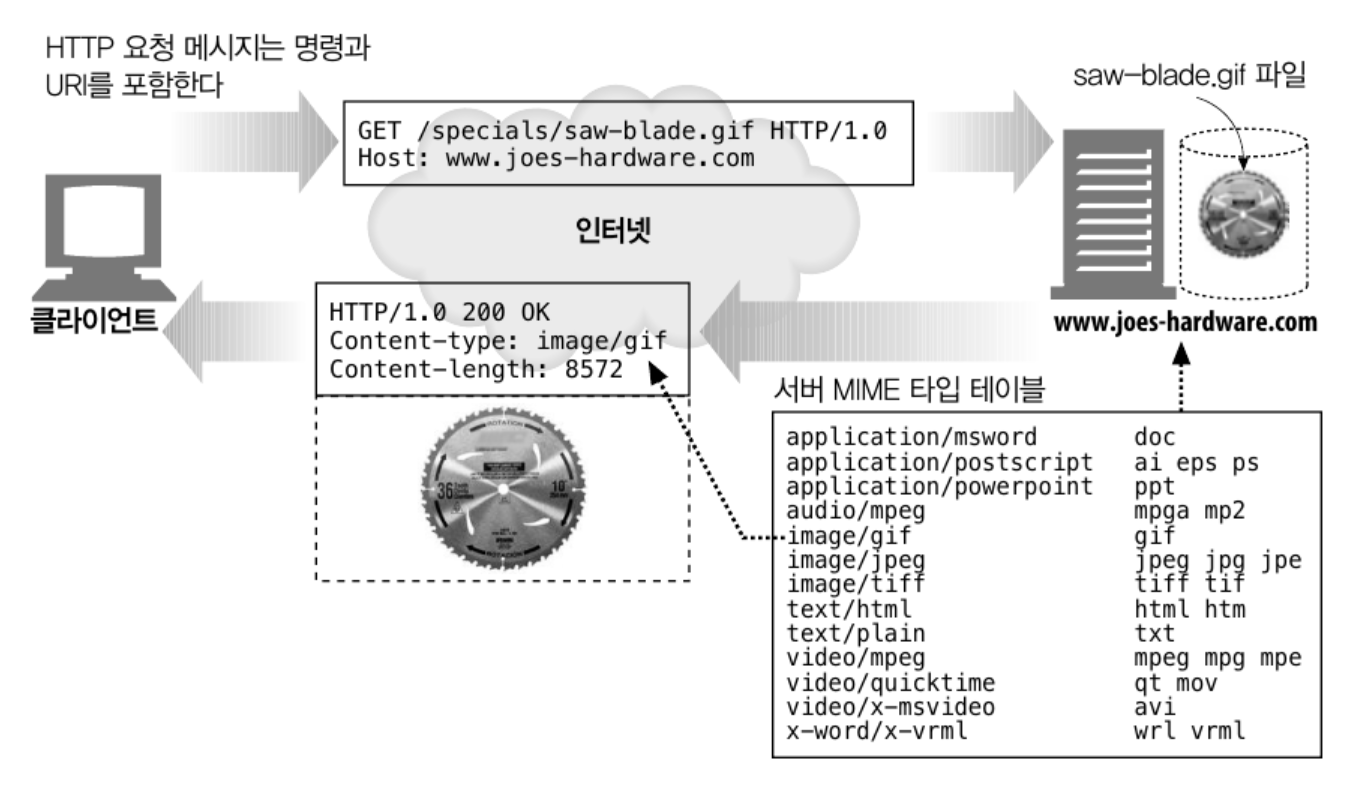
파일 확장자에 맞춰 MIME 타입 테이블을 생성해두고 확장자에 따라 헤더 명을 정한다.
다양한 방법들이 있지만.. 가장 흔한 것만 설명하고 패스 ...
4.3 리다이렉션
웹 서버는 종종 성공 메시지 대신 리다이렉션 응답을 반환한다. (상태 코드 3XX)
클라이언트가 찾고자하는 리소스가 파일 디렉토리에서 옮겨졌거나 다양한 경우가 있다
일어날 수 있는 경우에 따른 리다리엑션들을 살펴보자
4.3.1 영구히 리소스가 옮겨진 경우
리소스가 새 URL 이 부여되어 새로운 위치로 옮겨졌거나 이름이 바뀌었을 수도 있다.
이 때 상태 코드 301 Moved Permantly 상태 코드를 반환하며 새로운 URL 이나 바뀐 리소스 명이 담긴 엔터티를 반환한다.
4.3.2 임시로 리소스가 옮겨진 경우
임시로 옮겨진 경우에도 바뀐 URL 을 클라이언트 측에 보내겠지만
클라이언트 측에서 받은 URL 이 임시적으로 바뀐것임을 알려 줄 수 있도록
상태코드 303 See Other 이나 307 Temporary Redirect 상태 코드를 담아 옮긴다.
4.3.3 URL 증강
종종 문맥 정보를 포함시키기 위해 재 작성된 URL 로 리다이렉트 한다.
예시를 살펴보면 상품이나 검색 엔진에서 클라이언트가 어떤 미리보기 형태를 클릭했다고 해보자
그렇다면 해당 URL 은 미리보기에 매핑되어 있는 URL 이다.
그러면 웹 서버 측에서는 가방의 정보가 담긴 리소스를 클라이언트에게 리다이렉트 하여 전송한다.
example.com/page?id=123 (클라이언트가 요청한 URL)example.com/products/best-product (웹 서버가 클라이언트에게 재전송한 URL)클라이언트는 리다이렉트를 따라가 완전한 정보가 담긴 URL 을 재요청하고 받는다.
이런 종류를 위해 303 See Ohter 와 307 Temporary Redirect 상태 코드를 사용한다.
4.3.4 부하 균형
과부하가 된 서버에 요청을 받으면 서버는 클라이언트를 위해 부하가 덜 걸린 서버로 리다이렉ㄱ트 할 수 있다.
4.3.5 디렉터리 이름 정규화
클라이언트가 디렉터리 이름에 대한 URL 을 요청하는데 만약 끝에 / 를 빠뜨렸다면
웹 서버는 오류를 보내는 것이 아닌 오률르 정정한 URL 로 리다이렉트 한다.
5. 응답을 보낸다
서버는 커넥션 상태를 확인하고 응답을 보낸다.
6. 트랜잭션 로그를 남긴다
트랜잭션이 완료되면, 트랜잭션이 어떻게 수행되었는지에 대한 로그를 로그 파일에 기록한다.
대부분의 웹 서버는 로깅에 대한 여러 가지 설정 양식을 제공한다.
