자바스크립트 배열은 배열이 아니다
아 왜 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
자료구조에서 말하는 배열은 동일한 크기의 메모리 공간이 빈틈없이 연속적으로 나열된 자료구조를 말한다.
이러한 배열을 밀집 배열 (dense array) 이라고 한다.
이런 밀집 배열은 각 요소가 동일한 데이터 크기를 가지며 빈틈없이 연속적으로 이어져있으므로 인덱스를 통한 접근하는 연산은 만에 된다.
검색 대상 요소의 메모리 주소 = 배열의 시작 메모리 주소 + 데이터 타입 크기 * 인덱스
하지만 모두 연속된 공간에 존재하기 때문에 끝부분이 아닌 인덱스에 값을 추가하거나 삭제하면 밀집 배열 형태를 유지하기 위해 변화가 있는 인덱스 이후의 인덱스들을 하나씩 옮겨줘야 해서 의 시간 복잡도를 가진다.
하지만 자바스크립트의 배열은 연속적으로 이어져있지 않아도 된다. 이러한 배열을 희소 배열 이라고 한다.
자바스크립트의 배열은 일반적인 배열의 동작을 흉내 낸 특수한 객체이다.
const arr = [1, 2, 3];
console.log(Object.getOwnPropertyDescriptors(arr));
/**
{
'0': { value: 1, writable: true, enumerable: true, configurable: true },
'1': { value: 2, writable: true, enumerable: true, configurable: true },
'2': { value: 3, writable: true, enumerable: true, configurable: true },
length: { value: 3, writable: true, enumerable: false, configurable: false }
}
*/배열 내 프로퍼티를 살펴보면 인덱스에 해당하는 프로퍼티에, value 값이 들어있는
오히려 객체에 가까운 형태임을 알 수 있다.
이처럼 자바스크립트는 인덱스 역할을 하는 프로퍼티로는 문자열 형태를 가지며
프로퍼티의 값에는 어떤 값이든 들어갈 수 있다.
const arr = [0, '가', true, , undefined, null];
console.log(arr); // [ 0, '가', true, <1 empty item>, undefined, null ]
console.log(Object.getOwnPropertyDescriptors(arr));
/**
{
'0': { value: 0, writable: true, enumerable: true, configurable: true },
'1': { value: '가', writable: true, enumerable: true, configurable: true },
'2': { value: true, writable: true, enumerable: true, configurable: true },
'4': {
value: undefined,
writable: true,
enumerable: true,
configurable: true
},
'5': { value: null, writable: true, enumerable: true, configurable: true },
length: { value: 6, writable: true, enumerable: false, configurable: false }
}
*/심지어 빈공간이나 undefined 마저도 말이다.
배열처럼 표현한 객체이기 때문에 최적화 하여 구현하였다.
const arr = [];
console.time();
for (let i = 0; i < 10000; i++) {
arr[i] = i;
}
console.timeEnd(); // default: 0.352ms
const obj = {};
console.time();
for (let i = 0; i < 10000; i++) {
obj[i] = i;
}
console.timeEnd(); // default: 0.735ms두 배 이상 빠르다.
length 프로퍼티와 희소 배열
배열은 Array 를 contructor 로 가지며 프로퍼티로 length 를 갖는다.
배열의 길이는 최대 까지 가능하다.
내부 프로퍼티인 length 는 값이 추가 될 때 마다 1개씩 올라가며 삭제 되면 1개씩 줄어든다. length 의 최소 값은 0이다.
const emptyArr = [];
const arr = [1, 2, 3];
console.log(emptyArr.length); // 0
console.log(arr.length); // 3자바스크립트는 희소 배열이라고 하였기 때문에 빈공간이 존재 할 수 있다.
const arr = [1, 2, , 4, 5];
console.log(arr); // [ 1, 2, <1 empty item>, 4, 5 ]
console.log(Object.getOwnPropertyDescriptors(arr));
/**
{
'0': { value: 1, writable: true, enumerable: true, configurable: true },
'1': { value: 2, writable: true, enumerable: true, configurable: true },
'3': { value: 4, writable: true, enumerable: true, configurable: true },
'4': { value: 5, writable: true, enumerable: true, configurable: true },
length: { value: 5, writable: true, enumerable: false, configurable: false }
}
*/동적으로 length 값을 변경하는 것이 가능하다.
const arr = [1, 2, 3, 4, 5];
arr.length = 10;
console.log(arr); // [ 1, 2, 3, 4, 5, <5 empty items> ]
arr.length = 3;
console.log(arr); // [ 1, 2, 3 ]
arr.length = 5;
console.log(arr); // [ 1, 2, 3, <2 empty items> ]배열의 길이보다 긴 length 를 사용하게 되면 배열의 빈자리가 늘어나게 되며
줄이게 되면 기존 있던 원소가 제거된다.
한 번 제거된 원소는 다시 나타나지 않는다.
const arr = [1, 2, , 4, 5];
console.log(arr.length); // 5위에서 살펴봤든 희소 배열 형태에 따라 빈 값에는 인덱스 역할을 하는 프로퍼티가 존재하지 않지만 길이 값에는 존재하는 모습을 볼 수 있다.
배열 생성
배열은 Array 를 통해 생성된다고 하였기 때문에 생성자 함수, 함수, 배열 리터럴 등을 이용해서 생성 할 수 있다.
const arr = new Array(10);
console.log(arr); // [ <10 empty items> ]
const arr2 = new Array(1, 10);
console.log(arr2); // [1, 10]생성자를 이용해 생성 할 때는 인수를 한 가지만 넣을 경우 인수 만큼의 빈자리를 가진 배열이 완성된다.
이 때 인수는 0 이상의 정수만 넣을 수 있다.
Array.of
ES6 에서 도입된 Array.of 는 인수를 요소로 받는 배열을 생성한다.
const arr = Array.of(10);
console.log(arr); // [ 10 ]
const arr = Array.of('string');
console.log(arr); // [ strirng ]Array.from
Array.from 은 유사배열 객체나 이터러블 객체를 인수로 전달 받아 배열로 변환한다.
인덱스로 프로퍼티 값에 접근 할 수 있고
length프로퍼티를 갖는 객체를 유사배열 객체라고 한다.
이터러블 객체는Symbol.iterator메소드를 구현하여for of로 순회 할 수 있으며 스프레드 문법과 배열 디스트럭터링 할당의 대상으로 사용 할 수 있는 객체를 말한다.
const arr = Array.from({ length: 3, 0: 'a', 1: 999 });
console.log(arr); // [ 'a', 999, undefined ]length 프로퍼티에 맞춰 배열을 생성하고 유사배열 객체의 프로퍼티에 따라 값을 지정한다.
const arr = Array.from({ length: 5, 0: 'a', 2: 999, name: 'lee ', 555: 25 });
console.log(arr); // [ 'a', undefined, 999, undefined, undefined ]인덱스 역할을 할 수 없는 프로퍼티는 무시한다.
const arr = Array.from({ length: 3 });
console.log(arr); // [ undefined, undefined, undefined ]
const arr2 = Array.from({ length: 3 }, (_, i) => i);
console.log(arr2); // [ 0, 1, 2 ]다음처럼 length 프로퍼티만 있는 경우엔 undefined 만 담긴 배열을 만들지만 콜백 함수를 두 번째 인수로 넣어줌으로서 사용 할 수 있다.
(_,i) => i 같은 경우, from 은 첫 번째 인수에 존재하는 객체의 인덱스와 값을 받는다.
해당 코드는 값을 배열에 리턴 하도록 하는 콜백 함수이다.
배열 요소의 추가와 갱신
배열에 새로운 값을 추가하거나 갱신하는 것이 가능하다.
const arr = [1, 2, 3];
console.log(arr.length);
arr[arr.length] = 4; // 4번째 값에 4번째 추가
console.log(arr); // [ 1 ,2 , 3, 4]
arr[arr.length * 2] = 5;
console.log(arr); // [ 1, 2, 3, 4, <4 empty items>, 5 ]
arr[0] = 0;
console.log(arr); // [ 0, 2, 3, 4, <4 empty items>, 5 ]배열의 인덱스를 이용해 값을 추가하거나 수정하는 것이 가능하다.
이 때 인덱스에 정수 형태의 숫자가 아닌 값을 넣으면 인덱스에 들어간 값이 인덱스 역할을 하는 것이 아니라 프로퍼티 역할을 하게 되어
프로퍼티가 추가된다.
const arr = [1, 2];
arr[1.1] = 3;
arr['foo'] = 4;
console.log(arr); // [ 1, 2, '1.1': 3, foo: 4 ]
console.log(arr.length); // 2
console.log(arr[3]); // undefined이 때 들어간 프로퍼티는 length 에 영향을 미치지 않는다.
또한 자바스크립트 배열의 인덱스는 프로퍼티 역할을 한다고 하였기 때문에
보기에 배열에 3번째 값은 4 여야 할 것 같지만 조회할 수 없어 undefined 가 나온다.
배열 요소의 삭제
배열은 객체의 형태를 따르기 때문에 인덱스 값을 제거하는 delete 가 가능하다.
const arr = [1, 2, 3];
delete arr[1];
console.log(Object.getOwnPropertyDescriptors(arr));
/**
[ 1, <1 empty item>, 3 ]
{
'0': { value: 1, writable: true, enumerable: true, configurable: true },
'2': { value: 3, writable: true, enumerable: true, configurable: true },
length: { value: 3, writable: true, enumerable: false, configurable: false }
}
*/
console.log(arr.length); // 3
하지만 이는 프로퍼티를 삭제하긴 하지만 length 값을 변경시키지 않기 때문에 이용하지 않는 것이 좋다.
const arr = [1, 2, 3];
arr.splice(0, 1);
console.log(arr); // [ 2, 3 ]splice 메소드를 사용해 splice(제거를 시작할 인덱스, 마지막으로 제거할 인덱스) 를 이용해 삭제하는 것이 가능하다.
배열 메소드
배열 메소드엔 원본 배열을 변경하는 메소드와 새로운 배열을 생성하여 반환하는 메소드가 있다.
| 메소드 | 설명 | 원본 변경 여부 |
|---|---|---|
concat | 배열을 합쳐 새로운 배열을 반환한다. | 원본 변경 안 함 |
filter | 주어진 함수의 조건을 만족하는 요소로 새로운 배열을 반환한다. | 원본 변경 안 함 |
map | 주어진 함수를 이용하여 각 요소를 변환한 새로운 배열을 반환한다. | 원본 변경 안 함 |
slice | 시작 인덱스부터 끝 인덱스까지의 요소를 선택하여 새로운 배열을 반환한다. | 원본 변경 안 함 |
splice | 배열의 일부를 삭제 또는 대체하고 그 위치에 새로운 요소를 추가하여 배열을 변경한다. | 원본 변경 함 |
forEach | 각 요소에 대해 주어진 함수를 실행한다. | 원본 변경 안 함 |
push | 배열의 끝에 하나 이상의 요소를 추가하고, 변경된 배열의 길이를 반환한다. | 원본 변경 함 |
pop | 배열의 마지막 요소를 제거하고 반환한다. | 원본 변경 함 |
shift | 배열의 첫 번째 요소를 제거하고 반환한다. | 원본 변경 함 |
unshift | 배열의 앞에 하나 이상의 요소를 추가하고, 변경된 배열의 길이를 반환한다. | 원본 변경 함 |
sort | 배열의 요소를 정렬한다. | 원본 변경 함 |
reverse | 배열의 순서를 뒤집는다. | 원본 변경 함 |
indexOf | 주어진 요소를 찾아 첫 번째 인덱스를 반환하고, 찾지 못하면 -1을 반환한다. | 원본 변경 안 함 |
lastIndexOf | 주어진 요소를 뒤에서부터 찾아 첫 번째 인덱스를 반환하고, 찾지 못하면 -1을 반환한다. | 원본 변경 안 함 |
includes | 주어진 요소가 배열에 포함되어 있는지 여부를 확인한다. | 원본 변경 안 함 |
join | 배열의 모든 요소를 문자열로 결합하여 반환한다. | 원본 변경 안 함 |
toString | 배열의 모든 요소를 문자열로 변환하여 반환한다. | 원본 변경 안 함 |
isArray | 주어진 값이 배열인지 여부를 확인한다. | 원본 변경 안 함 |
사용하다보면 익숙해진다.
Array.isArray
생성자 함수의 정적 메소드로 해당 객체가 Array 라면 true , 아니라면 false 를 반환한다.
const arr = [];
const obj = {};
console.log(Array.isArray(arr)); // true
console.log(Array.isArray(obj)); // falseArray.prototytpe.indexof
Array 의 프로토타입 메소드는 배열 객체에서도 사용 가능하다.
배열에서 인수로 전달 된 값의 인덱스를 반환하고 , 존재하지 않는다면 -1 을 반환한다.
중복되는 요소가 있을 시엔 첫 번째 인덱스만 반환한다.
const arr = [1, 1, 2, 3];
console.log(arr.indexOf(1)); // 0
console.log(arr.indexOf(4)); // -1이처럼 특정한 값이 존재하는지, 안하는지를 확인하는데 장점이 존재한다.
const arr = ['orange', 'banana'];
if (arr.indexOf('apple') === -1) {
arr.push('appele');
}
console.log(arr); // [ 'orange', 'banana', 'appele' ]하지만 존재하지 않을 경우 -1 을 반환하기 때문에 반복문에서 조건을 달아줘야 했다.
-1은falsy한 값이 아니다.
그래서 ~! ES7 에서 추가된 includes 를 활용하면 더 편리하다.
const arr = ['orange', 'banana'];
console.log(arr.includes('orange')); // true
console.log(arr.includes('apple')); // false| 메소드 | 설명 | 반환 값 |
|---|---|---|
indexOf |
주어진 요소를 배열에서 찾아 첫 번째 인덱스를 반환하고, 찾지 못하면 -1을 반환한다. | 해당 요소의 인덱스 또는 -1 |
includes |
주어진 요소가 배열에 포함되어 있는지 여부를 확인한다. | true 또는 false (Boolean) |
Arrray.prototype.push
push 는 원본 배열을 수정하며, 인수로 전달받은 모든 값을 원본 배열의 마지막 요소로 추가한다.
const arr = [1, 2, 3];
arr.push(4);
const result = arr.push(5, 6, 7); // push 한 후 length 를 return
console.log(arr); // [1,2,3,4,5,6,7]
console.log(result); // 7하지만 성능 면에서 좋지 않다.
그 이유는 결국 Array.prototype 까지 올라가서 추가해야 하기 때문에 오버헤드가 존재하기 때문이다.
그래서 그냥 index를 이용하거나 스프레드 문법을 이용해 추가해주자
const arr = [1, 2, 3];
arr[arr.length] = 4;
const newarr = [...arr, 5, 6, 7];
console.log(newarr); // [1,2,3,4,5,6,7]Array.prototype.pop
pop 은 마지막 인덱스에 해당하는 값을 제거한다.
const arr = [1, 2, 3];
const value = arr.pop();
console.log(arr);// [1,2]
console.log(value); // 3push 와 pop 을 통해 자료구조인 스택을 구현 할 수 있다.
사실 구현 안해도 이미 배열 자체가 스택이다.
class Stack {
#arr;
constructor(arr = []) {
if (!Array.isArray(arr)) {
throw new TypeError(`배열을 넣어주세용`);
}
this.#arr = arr;
}
append(value) {
this.#arr.push(value);
}
pop() {
return this.#arr.pop();
}
}Array.prototype.unshift
unshift 는 받은 인수 값을 배열의 선두에 요소로 추가하고 변경된 length 프로퍼티 값을 반환한다.
unshift 는 직접 배열의 값을 변경한다.
const arr = [1, 2];
const length = arr.unshift(3, 4);
console.log(arr); // [3,4,1,2]
console.log(length); // 4Arrray.prototype.shift
shift 는 원본 배열에서 첫 번째 요소를 제거하고 제거한 요소를 반환한다.
원본 배열이 빈 배열이면 undefined 를 반환한다.
이 또한 직접적으로 변경한다.
const arr = [1, 2];
const value = arr.shift();
console.log(value); // 1파이썬의 deque 구현하기
이걸 이용해서 자료구조인 큐 또한 구현 할 수 있다고 하긴 했다.
그런데 그렇게 큐를 구현한다 해도 맨 앞 부분을 제거하는 연산의 시간 복잡도는 이다.
챗 지피티한테 파이썬의 deque 같은 모듈은 없냐 물어봤드니 없다고 한다.
그래서 필요하면 직접 구현하랜다.
더 물어보니 deque 모듈도 결국 양방향 리스트로 만든 거라고 해서 양방향 리스트를 구현해봤다.
function Node(value) {
this.key = value;
this.next = null;
this.prev = null;
}
class Deque {
constructor() {
this.head = null;
this.tail = null;
this.length = 0;
}
isEmpty() {
return this.length === 0;
}
append(value) {
const node = new Node(value);
if (!this.tail) {
this.head = node;
this.tail = node;
} else {
this.tail.next = node;
node.prev = this.tail;
this.tail = node;
}
this.length += 1;
}
appendleft(value) {
const node = new Node(value);
if (!this.head) {
this.head = node;
this.tail = node;
} else {
this.head.prev = node;
node.next = this.head;
this.head = node;
}
this.length += 1;
}
pop() {
if (!this.length) {
return null;
}
const removedItem = this.tail;
if (this.length === 1) {
this.head = null;
this.tail = null;
} else {
this.tail = this.tail.prev;
this.tail.next = null;
}
this.length -= 1;
return removedItem.key;
}
popleft() {
if (!this.length) {
return null;
}
const removedItem = this.head;
if (this.length === 1) {
this.head = null;
this.tail = null;
} else {
this.head = this.head.next;
this.head.prev = null;
}
this.length -= 1;
return removedItem.key;
}
printArrray() {
let node = this.head;
while (node.next !== null) {
process.stdout.write(`${node.key} => `);
node = node.next;
}
process.stdout.write(`${node.key}\n`);
}
}
let deque = new Deque();
deque.append(1);
deque.append(2);
deque.append(3);
deque.append(4);
deque.append(5);
deque.printArrray(); // 1 => 2 => 3 => 4 => 5
console.log(deque.popleft()); // 1
console.log(deque.pop()); // 5
deque.appendleft(99);
deque.printArrray(); // 99 => 2 => 3 => 4Array.prototype.concat
concat 은 인수로 전달된 값을 원본 배열의 마지막 요소로 추가한 새로운 배열을 반환한다.
const result = [1, 2].concat([3, 4]);
console.log(result); // [1,2,3,4]push 와 차이점은 concat 은 원본 배열을 변경하지 않은 채 새로운 배열을 생성한다는 것이다.
하지만 이는 ES6 의 스프레드 문법으로 대체 할 수 있다.
const result = [...[1, 2], ...[3, 4]];
console.log(result); // [ 1, 2, 3, 4 ]Array.prototype.splice
splice(제거 시작 인덱스, 제거할 요소 개수 , 제거하고 채울 값(옵션)) 으로 사용한다.
const arr = Array.from({ length: 10 }, (_, i) => i);
arr.splice(0, 5);
console.log(arr); // [ 5, 6, 7, 8, 9 ]
arr.splice(0, 2, 999, 999);
console.log(arr); // [ 999, 999, 7, 8, 9 ]만약 제거할 요소 개수를 0으로 하고 채울 값만 넣으면 중간에 값을 삽입 할 수 있다.
const arr = Array.from({ length: 10 }, (_, i) => i);
arr.splice(0, 1, 999, 999);
console.log(arr); // [ 999, 999, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]만약 첫 번째 인수만 사용하면 제거를 시작할 인덱스부터 모든 요소를 제거 한다.
const arr = Array.from({ length: 10 }, (_, i) => i);
arr.splice(1);
console.log(arr); // [0]Array.prototype.slice
slice는 (복사를 시작할 인덱스 , 복사를 종료할 인덱스) 를 인수로 받는다.
이후 배열의 인덱스를 복사한 새로운 배열을 반환한다.
const arr = [1, 2, 3, 4, 5];
const Newarr = arr.slice(2, 5);
console.log(Newarr); // [ 3, 4, 5 ]인수를 모두 생략하면 배열 자체를 복사하나 얕은 복사를 사용하기 때문에
loadsh 모듈을 이용하는것이 좋다.
Array.prototype.join
join 메소드는 배열의 모든 요소를 문자열로 변환한 후 인수로 받은 문자열을 구분자로 연결한 문자열을 반환한다.
const arr = [1, 2, 3, 4, 5];
console.log(arr.join()); // 1,2,3,4,5
console.log(arr.join('')); // 12345
console.log(arr.join('|')); // 1|2|3|4|5Array.prototype.reverse
원본 배열의 순서를 반대로 뒤집는다.
이 때 원본 배열은 변경된다.
Array.prototype.fill
인수로 전달받은 값을 배열의 처음부터 끝까지 해당 요소로 채운다.
인수를 세가지 받으며 첫 번째 인수는 채울 값, 두 번째 인수는 채우기를 시작할 인덱스, 세번째 인수는 채우기를 종료할 인덱스이다.
Array.prototype.flat
flat은 중첩되어 있는 배열을 평탄화 한다.
인수로는 몇 겹을 평탄화 시킬지를 정하며 infinity 로 설정할 경우 모두 1차원으로 flatten 시킨다.
const arr = [1, 2, [3, [4, [5, 6, 7]]]];
console.log(arr.flat(1));
console.log(arr.flat(2));
console.log(arr.flat(Infinity));[ 1, 2, 3, [ 4, [ 5, 6, 7 ] ] ]
[ 1, 2, 3, 4, [ 5, 6, 7 ] ]
[
1, 2, 3, 4,
5, 6, 7
]배열 고차 함수
이 부분이 가장 중요한 것 같다.
최대한 함수형 프로그래밍 방식으로 코드의 가독성을 높일 수 있도록 콜백 함수를 자주 이용하는 자바스크립트 언어 특성상 제대로 이해하고 넘어가야 할 것 같아서 이틀이나 걸렸다.
고차 함수는 함수를 인수로 전달 받거나 함수를 반환하는 함수이다.
고차 함수는 외부 상태의 변경이나 가변 데이터를 피하고 불변성을 지향하는 함수형 프로그래밍에 기반을 두고 있다.
최대한 조건문과 반복문을 제거하여 복잡성을 해결하고 , 변수의 생성과 사용을 억제하여 상태 변경을 피하려는 프로그래밍 패러다임을 이용해야 한다.
순수 함수를 통해 부수 효과를 최대한 억제하는 것이 함수형 프로그래밍의 주 목적이다.
Array.prototype.sort
const arr = ['d', 'c', 'b', 'a'];
arr.sort();
console.log(arr); // [ 'a', 'b', 'c', 'd' ]sort 는 원본 객체를 변경하며 정렬된 배열을 반환한다. 기본적으로 오름차순으로 요소를 정렬한다.
자바스크립트의 sort 는 조금 특별한 점이 있는데 이는 어떤 타입의 값이든
문자열로 변경한 후 유니코드 포인트의 순서를 따른다는 것이다.
이 때 유니코드 포인트는 자리수에 대한 큰 인식이 없기 때문에
const arr = [1, 2, 3, 10];
arr.sort();
console.log(arr); // [ 1, 10, 2, 3 ]10이 2보다 작은 숫자로 판단되는 문제가 발생한다.
따라서 숫자 요소를 정렬 할 떄엔 정렬 순서를 정의하는 비교 함수를 인수로 전달해야 한다.
비교 함수는 양수나 음수 또는 0을 반환해야 하며, 비교 함수의 반환값이 0보다 작으면 함수의 첫 번째 인수를 우선하여 정렬하고, 0이면 정렬하지 않으며, 0보다 크면 두 번째 인수를 우선화 하여 정렬한다.
const arr = [1, 3, 10, 2];
arr.sort((a, b) => a - b);
console.log(arr); // [ 1 , 2 , 3 , 10]해당 코드에서 sort 가 진행되는 방식은 다음과 같다.
const arr = [1, 3, 10, 2];
arr.sort((...rest) => console.log(rest));[ 3, 1 ]
[ 10, 3 ]
[ 2, 10 ]들어오는 인수를 확인하면 두 개의 인수가 들어오며, 첫 번째 인수는 1번째 값, 두 번쨰 인수는 0 번째 값이 들어오며 배열의 끝까지 탐색한다.
const arr = [2, 1, 10, 3];
arr.sort((a, b) => a - b);팀 소트 정렬 방식을 이용했다는데 아직 정렬 알고리즘들에 대해서 공부하지 않았기 때문에 자세히 공부하고 적어봐야겠다.
만약 배열 내의 객체들을 프로퍼티 별로 정렬해야 한다면
const todos = [
{ id: 4, content: 'Javascript' },
{ id: 20, content: 'Html' },
{ id: 1, content: 'Css' },
];
function compare(key) {
return (a, b) => (a[key] > b[key] ? 1 : a[key] < b[key] ? -1 : 0);
}
todos.sort(compare('id'));
console.log(todos);
/**
[
{ id: 1, content: 'Css' },
{ id: 4, content: 'Javascript' },
{ id: 20, content: 'Html' }
]
*/처럼 콜백 함수를 생성하여 사용하는 방법도 있다.
Array.prototype.forEach
조건문과 반복문의 사용을 제거하여 복잡성을 해결하고 변수의 사용을 억제하여, 최대한 함수형 프로그래밍 패러다임을 따라야 한다.
조건문과 반복문은 코드의 흐름을 읽기 어렵게 하기 때문이다.
배열의 반복문을 해결하기 위한 방법이 forEach 메소드로서, 이는 배열의 값들을 탐색한다.
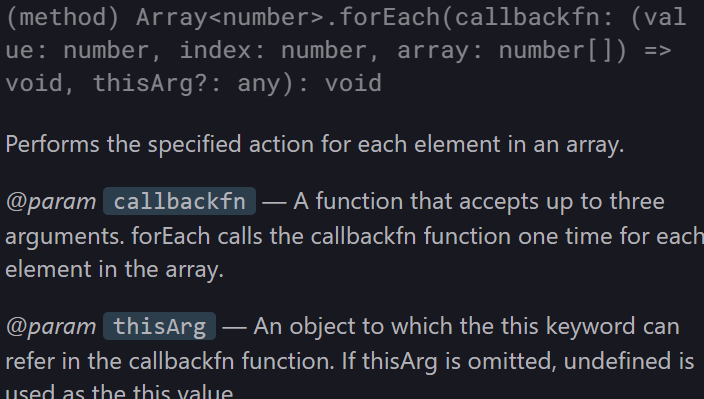
최대한 공식 문서에 있는 내용들을 이해할 수 있도록 노력해보려고 한다.
메소드 시그니처를 해석해보자
forEach(callbackfn: (value: number, index: number, array: number[]) => void, thisArg?: any): voidcallbackfn : (value : number , index : number , array : numer[]) => void : forEach
에서 => 를 기준으로 좌측은 콜백 함수와 그곳에 필요한 매개 변수들과 매개변수의 타입을 나타낸다.
=> 우측으론 반환되는 값을 의미하는데 void 는 비어있다는 뜻으로 따로 반환되는 값이 없으며 콜백 함수를 실행한다는 역할만 한다는 것을 의미한다.
array : number[] 라고 적혀있는 것은 데이터 타입이 number 가 들어있는 배열 이란 뜻이다.
결국 forEach 에 필요한 매개 변수는 두 가지로 callbackfn 과 thisArg? 이다.
thisArg?: any 가 의미하는 것은 콜백 함수내에서 참조 할 this 를 바인딩 해주는 것인데 ? 가 붙은 것은 Optional 이란 것임으로 사용해도 되고 사용하지 않아도 되며 , 가능한 데이터 타입은 any 라고 한다.
일반 함수와 화살표 함수를 이용해서 forEach 를 사용해보자
일반 함수 이용하기
const arr = [1, 2, 3, 4, 5];
// 배열의 값들을 2배씩 해서 생성 하고 싶어
// 일반 함수를 이용해서 하기
let newArr = [];
arr.forEach(function double(number) {
newArr.push(number * 2);
});
console.log(newArr); // [ 2, 4, 6, 8, 10 ]화살표 함수 이용하기
const arr = [1, 2, 3, 4, 5];
// 배열의 값들을 2배씩 해서 생성 하고 싶어
// 일반 함수를 이용해서 하기
let newArr = [];
arr.forEach((item) => newArr.push(item * 2));
console.log(newArr); // [ 2, 4, 6, 8, 10 ]와우 굿 ㅋㅋ
그럼 forEach 는 인수로 값과 인덱스 뿐이 아니라 array(this) 자체는 왜 줄까 ?
그것은 원본 배열을 수정하기 용이하게 하기 위함이다. 콜백 함수로 호출된 일반 함수의 this 는 전역 객체를 가리키기 때문에 this 에 해당하는 것을 직접 바인딩 해줘야 했다.
class Numbers {
newArr = [];
multiply(arr, factor) {
arr.forEach(function (item) {
this.push(item * factor);
}, this.newArr); // this 를 바인딩 시켜주었다.
}
}
const numbers = new Numbers();
numbers.multiply([1, 2, 3], 2);
console.log(numbers.newArr); // [ 2, 4, 6 ]하지만 화살표 함수는 렉시컬 환경에 따라 this 가 바인딩 되기 때문에 바인딩 시켜줄 필요가 없다.
class Numbers {
newArr = [];
multiply(arr, factor) {
arr.forEach((item) => this.newArr.push(item * factor));
}
}
const numbers = new Numbers();
numbers.multiply([1, 2, 3], 2);
console.log(numbers.newArr); // [ 2, 4, 6 ]와우 굿 ㅋㅋ
forEach같은 경우엔for문 처럼break , continue등을 제공하지 않으며 희소배열의 경우에는 순회하지 않는다.
그로 인해for문에 비해 성능은 비교적 떨어지나 가독성이 올라가기 때문에 사용 하는 것을 권장한다.
Array.prototype.map
이전 forEach 같은 경우엔 반환 값을 주지 않았다면 map 은 반환 값들로 구성된 새로운 배열을 반환한다.
이 때 원본 배열은 변경되지 않는다.

forEach 와 같은 콜백함수를 받으며 최종 반환 값으로는 U[] 를 주는 것을 볼 수 있다.
U는 제네릭 타입 변수로서 메소드가 반환하는 배열의 요소 타입을 의미한다.
그러니 어떤 반환 값을 뱉는 콜백 함수를 이용하여 새로운 배열을 생성한다는 것이다.
const arr = [1, 2, 3, 4, 5];
const newArr = arr.map((item) => item * 2);
console.log(newArr); // [ 2, 4 , 6 , 8 , 10]
console.log(arr); // [1 , 2 , 3 , 4 , 5]Array.prototype.filter
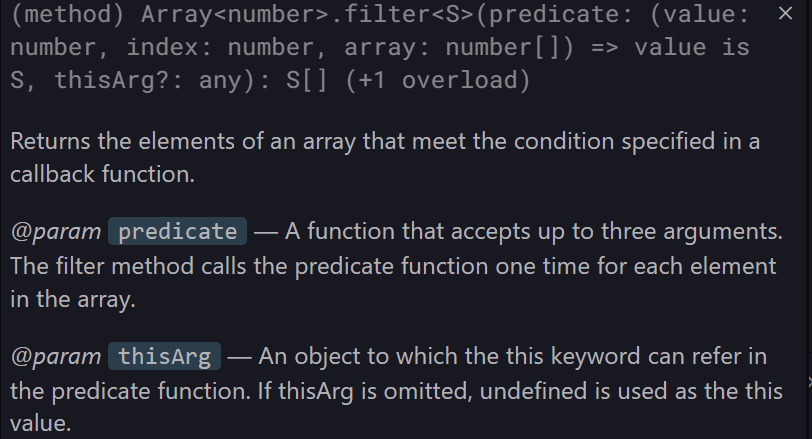
콜백 함수로 반환 값이 value is S ? 라는 boolean 값을 뱉는 predicate 함수를 콜백 함수로 받는다.
이후 반환 값으로 데이터 타입이 S 인 배열을 return 한다.
아 ~ 콜백함수는 불리언 타입으로 조건에 따라서 true / false 값을 뱉는 콜백 함수여야겠구나
데이터 타입이
S나U나 이런건 제네릭 데이터 타입으로, 배열의 원소에 따라 동적으로 결정되는 데이터 타입을 의미한다.
const arr = [1, 2, 3, 4, 5];
// 홀수인 애들만 가져와야지 ~!!
const oddArr = arr.filter((item) => item % 2);
console.log(oddArr); // [1 , 3 ,5]이를 통해 객체들이 담긴 배열에서도 조건에 따른 객체들만 가져오는 것도 가능하다.
const arr = [
{ id: 1, score: 90 },
{ id: 2, score: 60 },
{ id: 3, score: 40 },
{ id: 4, score: 20 },
{ id: 5, score: 50 },
];
// 점수가 50점 이상인 학생들만 필터 하고 싶어
const goodStudent = arr.filter((item) => item.score >= 50);
console.log(goodStudent);
// 그럼 점수가 50점 이상인 학생들의 평균 점수를 구하고 싶어
const Avgscore =
goodStudent.reduce((sum, student) => sum + student.score, 0) /
goodStudent.length; // reduce 같은 경우엔 첫 번째 인수 값을 정적으로 정할 수 있다.
// 첫 번쨰 인수 값을 정해주면 탐색은 0번쨰 인덱스부터 탐색한다.
console.log(Avgscore); // 66.666...Array.prototype.reduce
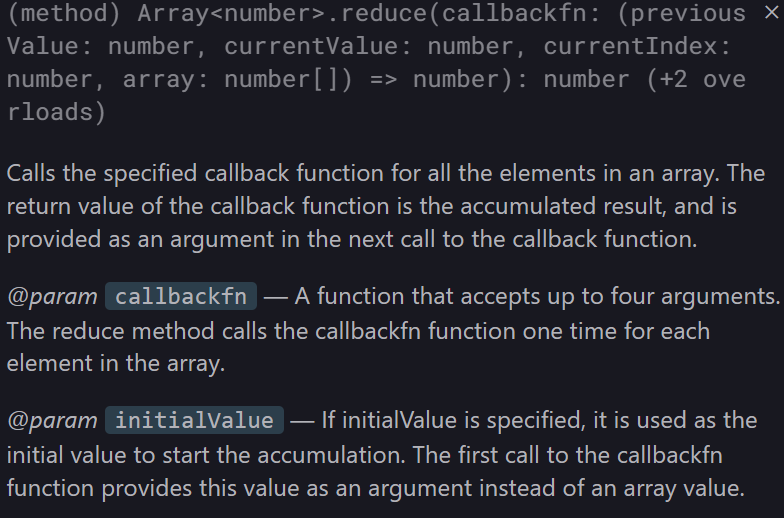
previousValue 와 currentValue 를 인수로 받는 콜백 함수를 이용한다.
이 때 반환 값은 previousValue 와 currentValue의 누적 결과값이며, 반환 값은 다음 콜백 함수 호출 때 previousValue 로 사용된다고 한다.
두 번째 매개 변수로는 initialValue 를 선택적으로 받는데, 만약 initialValue 가 정해졌다면 첫 번째 콜백 함수 호출 시 previousValue 로 사용된다고 한다.
const arr = [1, 2, 3, 4, 5];
function sum(a, b) {
return a + b;
}
let prev = 0;
let result = 0;
for (let curr = 1; curr < arr.length - 1; curr += 1) {
result += sum(arr[prev], arr[curr]);
prev += 1;
}
console.log(result); // 15이런 식의 로직으로 흘러간다.
이 때는 sum 을 콜백 함수로 사용 한 것이다.
해당 식을 reduce 를 이용하면
const arr = [1, 2, 3, 4, 5];
const result = arr.reduce((prev, curr) => prev + curr);
console.log(result); // 15와우 ㅋㅋ
초기값을 설정해줄 수도 있다.
초기값으로 설정해주면 prev 값이 초기값, curr 이 0 번째 인덱스로 시작한다.
const arr = [1, 2, 3, 4, 5];
const result = arr.reduce((prev, curr) => prev + curr, 100);
console.log(result); // 115reduce 안에 콜백 함수를 어떻게 만드느냐에 따라서
다양하게 사용 할 수 있다.
평균 구하기
const arr = [1, 2, 3, 4, 5];
const avg = arr.reduce((acc, cur, index, { length }) => {
return index === length - 1 ? (acc + cur) / length : acc + cur;
});
console.log(avg); // 3여기서 포인트는 {length} 로 한 것은 thisArg 로 넘어오는 arr 객체의 length 프로퍼티만 가져오는 destructuring 문법을 사용 한 것이다.
이후 반환 값은 마지막 인수에 닿기 전에는 누적 값을, 마지막 인수 값일 때에는 길이로 나눠 리턴했다.
최대값 구하기
const arr = [1, 2, 3, 4, 5];
const max = arr.reduce((acc, cur) => {
return acc > cur ? acc : cur;
}, 0);
console.log(max); // 5삼항 연산자를 이용한다거나
값의 발생 횟수 구하기
const arr = [1, 1, 1, 1, 1, 2, 2, 3, 3, 3];
const count = arr.reduce((acc, cur) => {
acc[cur] = (acc[cur] || 0) + 1;
return acc;
}, {});
console.log(count); // { '1': 5, '2': 2, '3': 3 }초기값을 빈 객체로 설정해주었기 때문에 acc : {} , cur : 1 로 설정 될 것이다.
이후 빈 객체의 cur 프로퍼티 값을 해당 프로퍼티 값 || 0 으로 설정해주었는데
이는 만약 프로퍼티 값이 존재하지 않을 경우엔 undefined 가 되어 단축 평가를 통해 값이 0으로 자동으로 설정되는 기법을 이용했다.
중복 요소 제거
const arr = [1, 1, 1, 1, 1, 2, 2, 3, 3, 3];
const uniqueArr = arr.reduce(
(unique, val, i, _values) =>
_values.indexOf(val) === i ? [...unique, val] : unique,
[],
);
console.log(uniqueArr); // [1,2,3]초기값으로 빈 배열을 주고, 들어온 값이 기존 array 의 첫 인덱스와 같다면 unique 배열을 [...unique , val] 로 변경하고 아닐 경우엔 변경하지 않는다.
솔직히 말하면 반복문보다 더 이해 안된다.
삼항연산자 자체가 가독성을 방해해서 그런가 ?
사실 이 방법은 filter 를 이용하는 것이 더 직관적이다.
// filter 메소드 이용하기
const arr = [1, 1, 1, 1, 1, 2, 2, 3, 3, 3];
const unique = arr.filter((item, i) => arr.indexOf(item) === i);
console.log(unique); // [1,2,3]reduce 는 초기값을 지정해주는 것이 안전하다.
Array.prototype.some

some 메소드에 들어가는 콜백함수 predicate 는 배열의 어떤 값중 하나라도 true 인지를 규정하는 콜백함수이다.
그래서 최종적으로 반환하는 것은 true / false 반환 값이다.
const arr = [1, 2, 3, 4, 5];
console.log(arr.some((item) => item > 3)); // true
console.log(arr.some((item) => item > 10)); // false Array.prototype.every
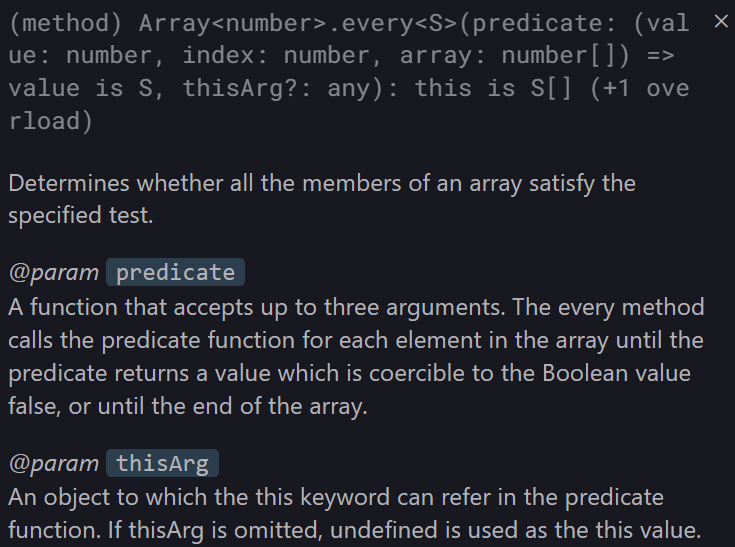
every는 배열이 모든 콜백 함수 내에 규정된 조건을 모두 만족하는지를 확인한다.
const arr = [1, 2, 3, 4, 5];
console.log(arr.every((item) => item > 0)); // true
console.log(arr.every((item) => item > 3)); // falseArray.prototype.find
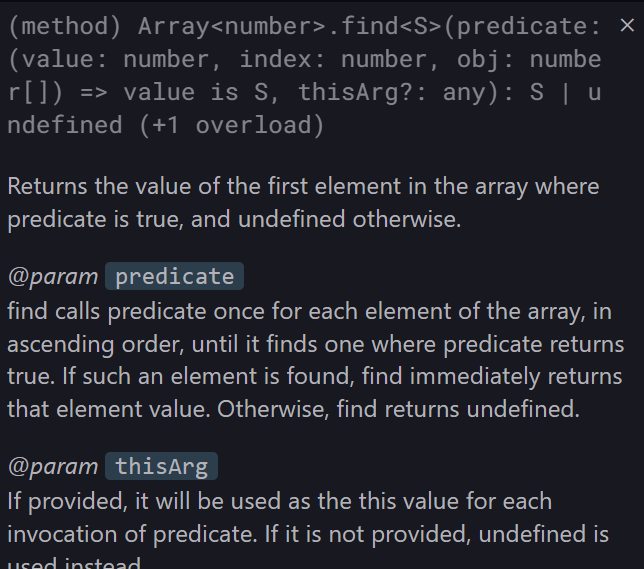
find 는 조건에 맞는 값 자체를 반환한다.
이 때 배열에 조건에 맞는 값이 여러개가 있더라도 최초로 발견된 값 하나를 반환하며 , 존재하지 않을 경우엔 -1 을 반환한다.
filter는 조건에 맞는 모든 값들을 담은 배열을 반환한 것과 대비된다 .
Array.prototype.findIndex
이건 ~ 그 인덱스를 반환하며 -1 을 반환하는 것 :)
