Number , Date 단원도 있긴 하지만 해당 단원은 나중에 쓰면서 배우는게 더 많을 것 같기에 .. 넘어가자
정규표현식은 책을 보기도 했지만 드림코딩 정규표현식 와 수 많은 블로그들을 가장 많이 참조했다.
정규 표현식
정규 표현식은 문자열의 검색, 추출, 대체 등의 작업을 수행하는데 사용되는 형식 언어이다.
주로 특정한 패턴을 가진 문자열을 표현하고 이를 검색하거나 다른 문자열과 일치시키는데 활용된다.
패턴 매칭
특정한 문자열 패턴을 찾거나 일치 시킴문자열 추출
특정 부분 문자열을 추출하거나 분리함대체
문자열 내에서 특정 패턴을 다른 문자열로 대체함검색
문자열 내에서 특정 패턴의 존재 여부를 확인함
자세한 문법들을 보기전에 예시를 살펴보자
const string = 'www.naver.com';
// 패턴 매칭
var pattern = /naver/;
console.log(pattern.test(string)); // // true
// 문자열 추출
var pattern = /naver/;
const result = string.match(pattern);
console.log(result); // ["naver"]
// 대체 (문자열 치환)
var pattern = /naver/;
const replacedString = string.replace(pattern, 'google');
console.log(replacedString); // "www.google.com"
// 검색(인덱스 확인)
var pattern = /naver/;
const index = string.search(pattern);
console.log(index); // 4 (일치하는 부분이 시작하는 인덱스)문법
| / | /(http|https|ftp|telnet|news|mms):\/\/[^\"'\s()]+/i | / | i |
|---|---|---|---|
| 패턴 시작 | 찾을 문자열의 패턴 | 패턴 종료 | 패턴 변경자 |
다음처럼 사용된다.
메타문자
다른 언어에서 연산자나 예약어로 쓰이는 문자를 정규 표현식에서는 메타 문자라고 한다.
메타 문자로 된 자원을 찾아야 하는 경우다른 언어와 마찬가지로 앞에 역슬래시 \ 를 붙여 이스케이프 해주면 된다.
- 메타 문자 :
\ ^ $ . | [ ] ( ) * + ? { } - 의미를 갖는 메타 문자
-^: 문자열의 시작
괄호 안에 들어가서 사용되면 부정 문자가 된다.$: 문자열의 종료
문자 집합과 특수 문자
| 문자 또는 패턴 | 설명 |
|---|---|
[abc] | a, b, c 중 하나에 일치 |
[^abc] | a, b, c 이외의 문자에 일치 |
[a-z] | a부터 z까지의 알파벳 중 하나에 일치 |
[A-Z] | A부터 Z까지의 대문자 중 하나에 일치 |
[0-9] | 0부터 9까지의 숫자 중 하나에 일치 |
[a-zA-Z] | 모든 알파벳 중 하나에 일치 |
| 특수 문자 | |
. | 어떤 문자 하나에 일치 (줄 바꿈 문자 제외) |
\d | 모든 숫자에 일치 ([0-9]와 동일) |
\D | 숫자 이외의 모든 문자에 일치 ([^0-9]와 동일) |
\w | 단어 문자 (알파벳, 숫자, 밑줄)에 일치 |
\W | 단어 문자 이외의 모든 문자에 일치 |
\s | 공백 문자에 일치 (공백, 탭, 줄 바꿈 등) |
\S | 공백 이외의 모든 문자에 일치 |
^ | 문자열의 시작 부분에 일치 |
$ | 문자열의 끝 부분에 일치 |
\b | 단어 경계에 일치 |
패턴 변경자
| 패턴 변경자 | 설명 |
|---|---|
i | 대소문자를 무시한 일치 |
g | 전역 검색 (문자열 내에서 모든 일치 검색) |
m | 다중 행 모드 (여러 행에서 일치 검색) |
u | 유니코드 모드 |
y | 스티커(y-sticky) 모드 |
예시
| 정규표현식 | 설명 |
|---|---|
^[0-9]*$ | 숫자 |
^[a-zA-Z]*$ | 영문자. 패턴변경자를 써서 /^[a-z]*$/i 같이 쓸 수 있다. |
^[가-힣]*$ | 현대 한글 (유니코드를 지원하는 정규식 엔진에 한정) |
^[ㄱ-ㅎㅏ-ㅣ가-힣]*$ | 한글 자모 낱자를 포함한 모든 현대 한글. 굳이 유니코드 환경에서도 KS X 1001 완성형의 현대 한글 2350자만 선택하고 싶다면 완성형/한글 목록/KS X 1001 문서의 끝부분을 참고할 것. |
^[a-zA-Z0-9]*$ | 영문/숫자 |
정리
어찌 됐든 정규 표현식을 사용해서 어떠한 값을 찾거나 대체 하려면 결국 찾고자 하는 키워드를 작성해야 한다.
그 키워드는 / / 사이에 넣어 시작하며 안에 찾고자 하는 키워드를 기술 하면 된다.
/ / 이후에는 패턴 변경자를 넣어준다.
패턴 변경자는 주로 i , g 를 사용하는데 i 는 패턴을 대 소문자 없이 검사한다.
g 는 문자열 내에서 모든 일치를 찾는다. 기본적으로 정규표현식은 첫 번째 일치만 반환하지만 g 를 사용하면 모든 일치를 반환한다.
ReqExr 사이트에 가서 실습하며 배워봐야겠다.

해당 문구들에서 정규 표현식을 이용해서 문자들을 조회해보자
키워드 입력하는 방법만 안다면 키워드를 이용해서 부가적인 것은 언제나 할 수 있으니까
단순히 단어 찾아보기
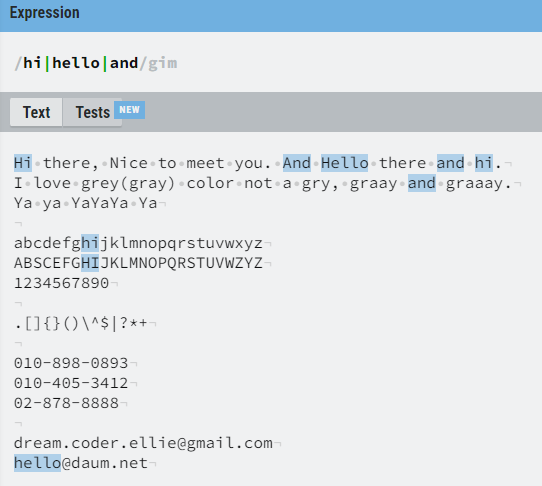
| 를 이용해서 찾을 수 있다.
이 때 매칭되는 것들은 다른 설정이 없다면 모두 하나의 그룹으로 묶이게 되는데
() 를 이용하여 그룹을 나눠 줄 수 있다.
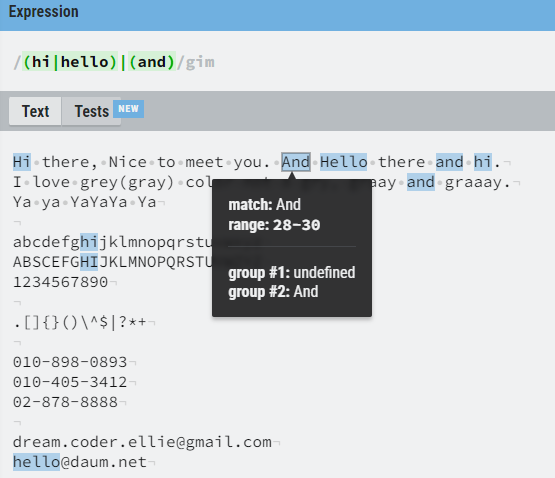
() 를 이용해서 단어에 조건 찾아 찾아보기
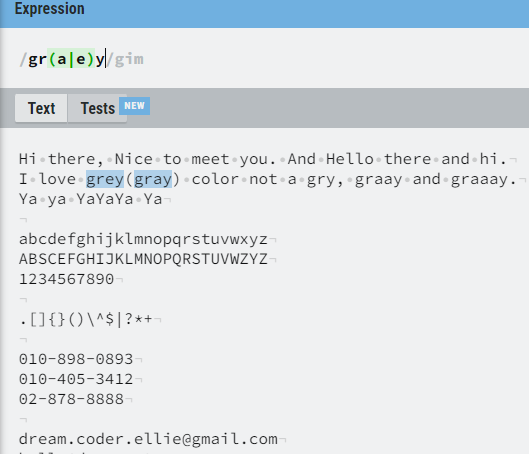
gr()y 를 찾을건데 이 때 () 안에 가능 한 키워드를 | 를 통해서 찾아줄 수 있다.
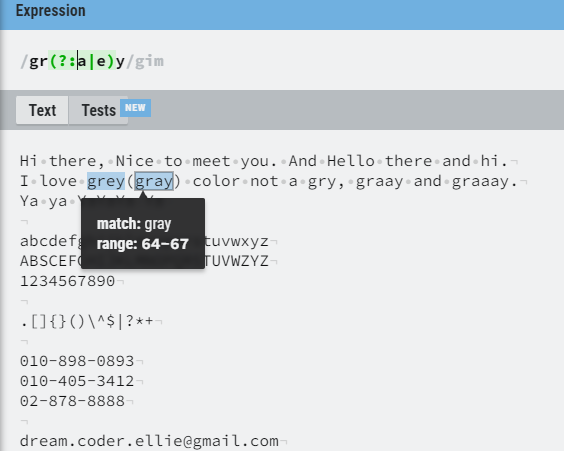
소괄호를 사용 할 때 괄호 안에 ?: 를 사용해주면 그룹핑이 되지 않는 모습을 볼 수 있다.
() 사용하지 않고 단어에 조건 넣어 찾아보기
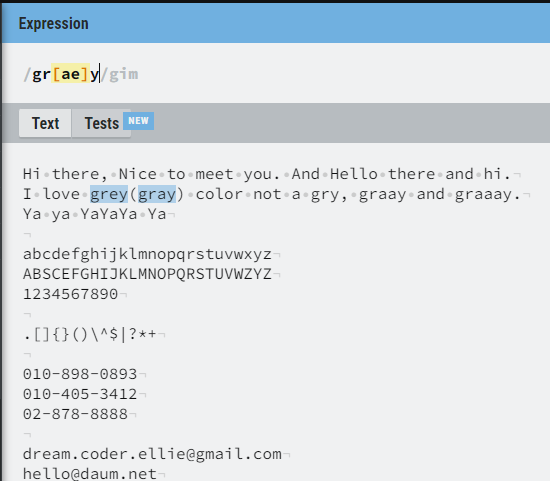
소괄호가 아닌 대괄호를 이용하여 필요한 조건들을 나열 하는 것이 가능하다.
위를 보면 [ae] 에서 a 거나 e 거나를 이용해 매칭 한 것을 볼 수 있다.
만약 더 많은 경우의 수를 나열 하고 싶다면 (예를 들어 a 부터 f까지) 하나하나 모두 쓸 필요 없이
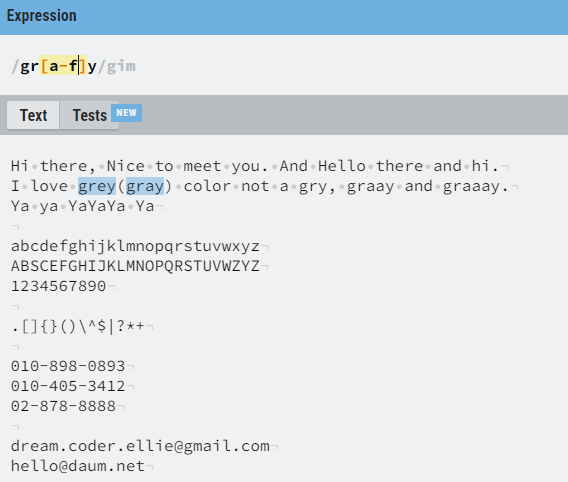
- 를 이용해서 범위를 구해줄 수 있다.
[] 를 사용하면 좋은 점
위에서 봤듯 [] 를 사용하면 단일 문자를 판단하는 것 뿐이 아니라 범위를 통해 찾을 수 있다.
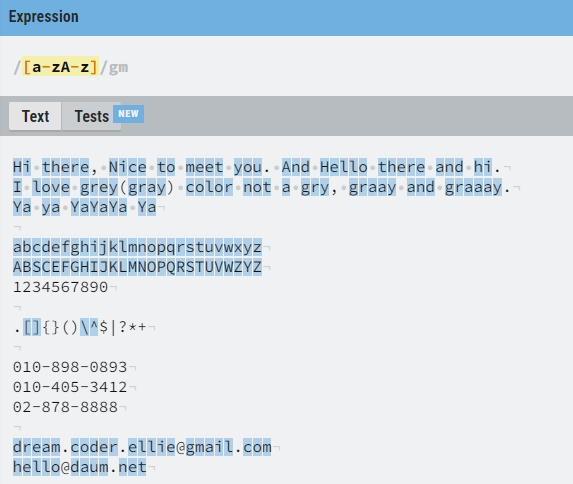
대문자를 구분하기 위해 플래그에스
i를 제거해줬다.
이뿐만 아니라 부정적 일치 를 사용하여서도 찾을 수 있다.
[a-zA-Z] 는 문자열 중 a-z 이거나 A-Z 인 경우를 찾았다면
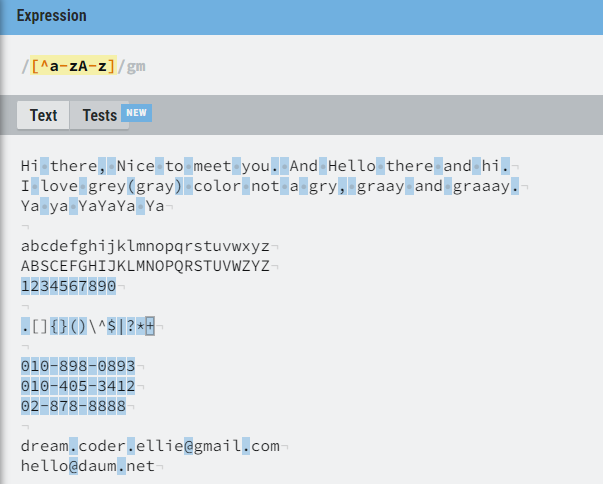
^ 를 괄호 안에 넣어주면 부정 표현자가 되어 해당 범위가 아닌 문자열들을 찾는다.
Boundary type
| 표현식 | 설명 | 예제 | 일치하는 문자열 예시 |
|---|---|---|---|
^ |
문자열의 시작 지점과 일치 | ^abc |
"abc", "abcd", but not "xabc" |
$ |
문자열의 끝 지점과 일치 | abc$ |
"abc", "xabc", but not "abcx" |
\b |
단어 경계와 일치 (단어의 시작 또는 끝) | \bword\b |
"word", "words", but not "keyword" |
\B |
비단어 경계와 일치 | \Bword\B |
"keyword", "subword", but not "word" |
(?<=...) |
전방탐색 (Lookbehind), ...의 뒤에 있는 위치와 일치 | (?<=@)\w+ |
이메일 주소에서 "@" 뒤의 단어에 일치 |
(?=...) |
전방탐색 (Lookahead), ...의 앞에 있는 위치와 일치 | \d+(?=%) |
숫자 뒤에 "%"가 있는 경우에 일치 |
^ 는 문장의 시작 부분이 해당 단어인 경우 해당 단어를 찾는다.

$ 는 문장의 마지막 부분이 해당 단어인 경우 해당 단어를 찾는다.
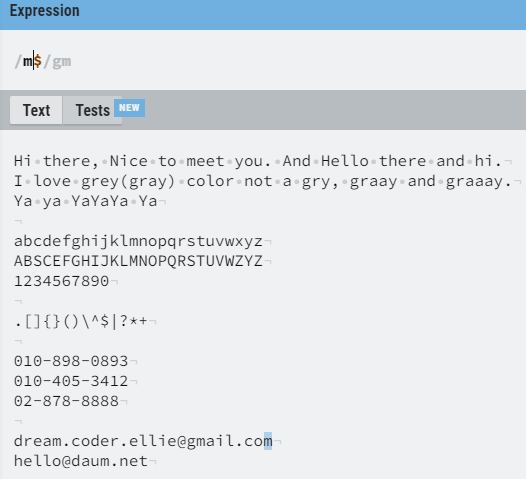
\b 는 문장에서 단어의 경계와 일치하는 단어를 찾는다.
문장별로가 아니라 문장의 단어 경계를 기준으로 대상으로 찾는다.
해당 패턴이 단어 경계에 위치하는가를 기점으로 이야기 한다
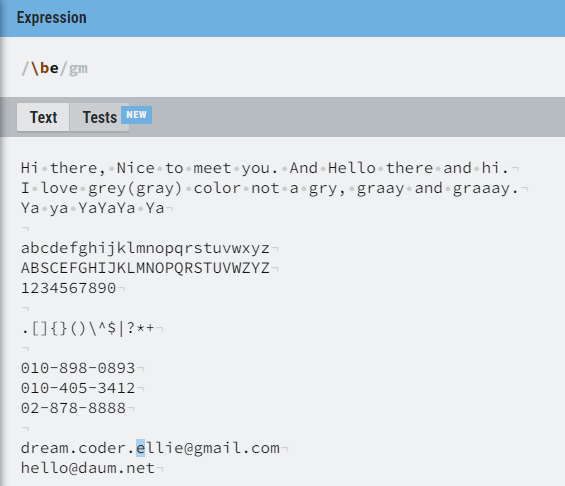
\b 가 앞에 가면 문장의 단어 시작 부분이 해당 단어일 경우를 찾고
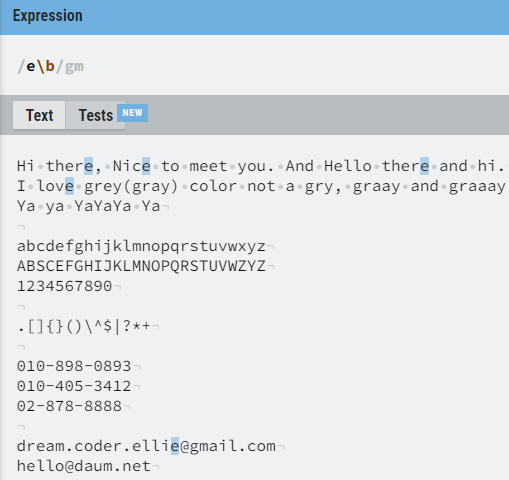
\b 가 뒤에 가면 문단의 단어 마지막 부분이 해당 단어일 경우를 찾는다.
그럼 만약 문장에서 단어들 중 H 로 시작하고 o 로 끝나는 단어를 찾아보겠다고 한다면
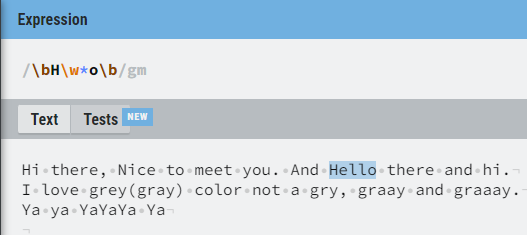
처럼 찾을 수 있다.
\w는[a-zA-Z_]와 같다.
*는 추후 나오겠지만 해당 단어들이 0회 이상 발생하느냐를 찾는 것으로\w*는 중간에 어떤 문장이 있든지와 상관 없겠다는 뜻이다.
\B 는 \b 와 같은 위치에서 쓰이지만 부정의 뜻을 담고 있다.
해당 위치에서 해당 단어로 시작하지 않는 단어를 찾는다.
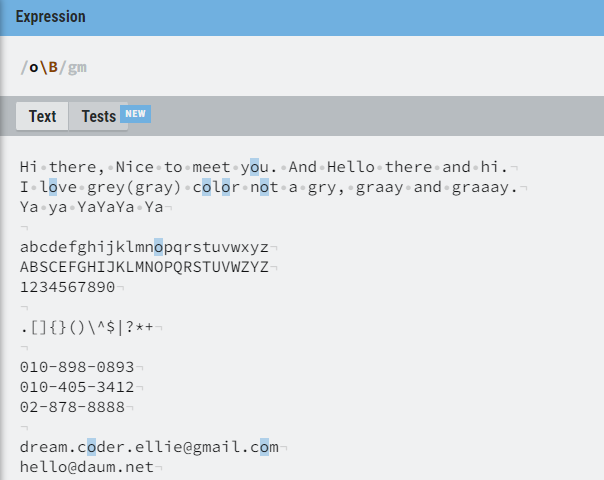
모든 o 를 탐색하는데 단어에서 마지막에 쓰인 o가 아닌 단어들을 찾았다.
수량 문법 정리
| 수량자 | 설명 | 예제 | 일치하는 문자열 예시 |
|---|---|---|---|
| ? | 0 또는 1회 발생 (0 또는 1개) | a? | "a" 또는 빈 문자열 |
| * | 0회 이상 발생 | a* | "a", "aa", "aaa", ... |
| + | 1회 이상 발생 | a+ | "a", "aa", "aaa", ... |
| {n} | 정확히 n회 발생 | a{3} | "aaa" |
| {min,} | 최소 min회 이상 발생 | a{2,} | "aa", "aaa", "aaaa", ... |
| {min,max} | 최소 min회부터 최대 max회까지 발생 | a{2,4} | "aa", "aaa", "aaaa" |
예시를 통해 공부하자
어차피 여기서 지금 하루종일 외워봤자 일주일 지나면 기억도 안날 것 같다.
차라리 예시를 통해 찾아보자
정규 표현식은 주로 언제 쓸까 ?
폼 유효성 검사(validation):
사용자로부터 입력 받은 데이터를 검사하고 유효성을 검증할 때 정규 표현식이 유용합니다. 예를 들어, 이메일 주소, 전화번호, 비밀번호 등의 형식을 확인하는 데 사용될 수 있습니다.
문자열 처리:
문자열에서 특정 패턴이나 문자를 찾아내거나 대체할 때 정규 표현식이 편리합니다. 예를 들어, 특정 단어를 찾거나 대문자를 소문자로 변환할 때 사용할 수 있습니다.
텍스트 검색과 대체:
웹 페이지 내에서 특정 문자열이나 패턴을 검색하거나 다른 문자열로 대체할 때 정규 표현식이 유용합니다. 이는 문자열 검색, 치환, 추출 등의 작업에 사용될 수 있습니다.
URL 파싱:
URL에서 필요한 정보를 추출하거나 URL의 유효성을 확인하는 데 정규 표현식을 사용할 수 있습니다.데이터 형식 변환:
데이터를 특정 형식으로 변환하거나 추출할 때 정규 표현식이 도움이 됩니다. 예를 들어, 날짜 형식, 숫자 형식 등을 다룰 때 사용할 수 있습니다.문서 내용 검색:
웹 페이지에서 특정 패턴이나 키워드를 찾거나 문서의 특정 부분을 추출하는 데 정규 표현식을 활용할 수 있습니다.텍스트 필터링:
사용자 입력에서 부적절한 문자나 패턴을 걸러내거나 교체할 때 정규 표현식을 사용할 수 있습니다.
폼 유효성 검사
주로 아이디나 비밀번호를 사용자가 제출했을 때 해당 형식이 맞는지 유효성 검사를 하기 위해 사용된다.
쉬운 것부터 하나씩 차례대로 가보자
1. 전화번호 유효성 검사
조건 : 000 - 0000 - 0000 형태의 핸드폰 번호나 000 혹은 00 - 000 - 0000 형태의 집전화를 유효성 검사 한다고 해보자
const isPhoneNumber = (number) => {
const regExp = /^(01(?:0|1|[6-9])|(0\d{1,2}))-*(?:\d{3}|\d{4})-*\d{4}/;
console.log(`${number} : ${regExp.test(number)}`);
};
const numbers = [
// 맞는 패턴
'010-1234-1234',
'01012341234',
'02-123-4567',
'0212345678',
// 틀린 패턴
'010-123-456',
'010-123456',
'02-123a-4567',
];
numbers.forEach((number) => isPhoneNumber(number));010-1234-1234 : true
01012341234 : true
02-123-4567 : true
0212345678 : true
010-123-456 : false
010-123456 : false
02-123a-4567 : false\d 숫자가 {} 를 이용해 몇 번 등장하고 - 는 발생 할 수도 있고 없을 수도 있으니 * 로 표현해줬다.
?: 는 전방 탐색으로
잘 걸러낸다.
이메일 유효성 검사
... to be continue ..
