웹 크롤링이란 웹의 정보를 자동으로 수집하는 것을 의미하며 이런 목적을 위해 만든 프로그램을 웹 크롤러라고 말한다.
html 페이지를 가져와서, html/css등을 파싱하고 필요한 데이터만 추출하는 기법이다.
필요 라이브러리
2가지의 라이브러리가 필요하다.
- requests 라이브러리
- 웹페이지를 가져오기 위한 라이브러리이다.
- bs4(BeautifulSoup) 라이브러리
- 웹페이지 분석(크롤링)을 하기 위한 라이브러리이다.
라이브러리가 없을 경우, pip install을 통해 설치해주자.

사용법
-
res = requests.get(url)을 통해 res 객체에 HTML 데이터가 저장되고 res.content로 데이터를 추출할 수 있다.
-
Html 페이지를 파싱하는 bs4
soup = BeautifulSoup(res.content , 'html.parser') -
필요한 데이터 검색
item = soup.find('태그명') -
데이터 추출
print(item.get_text())
다양한 추출 방법
- find vs find_all
==> find는 해당하는 태그를 하나만 추출한다.(가장 먼저 나오는 것)
==> find_all은 해당하는 것을 모두 추출해 리스트 형식으로 추출한다.(반복문으로 가져와야함)
HTML 언어를 기반으로 추출을 한다.
ex) p태그 문장이 두 개인데 이중에 하나를 선택하려면
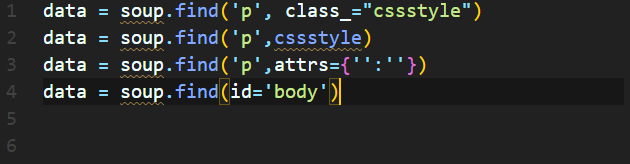
p태그를 전부 가져오려면

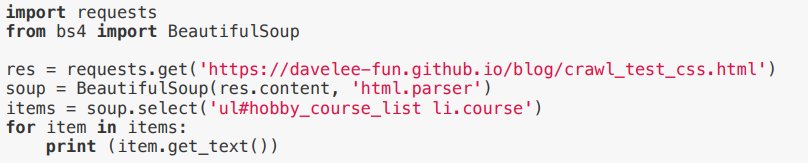
- CSS selector 사용
select와 select_one가 있다.
==> select는 해당 데이터를 리스트 형태로 반환하고, select_one는 첫번째 데이터만 얻고자 할 때 사용한다.
- 추출한 것에서 추출하기
find()/select()로 가져온 객체끼리 서로 함수를 사용할 수 있다.
