
Image가 뭘까요?
Image는 (x,y) 좌표계에서 f(x,y)로 정의된,
intensity 또는 color의 continuous distribution을 의미합니다.
f(x,y)를 light amplitude의 강도로 해석하면 좋습니다.
Digital Images
Digital image와 image는 다릅니다.
Digital image는 Digital Sampling의 값을 갖습니다.
finite, discrete quantities of image로 정의됩니다.
무슨 말이냐.
Digital Image는 일반적으로 R, G, B의 3가지 채널을 갖는데,
이 3가지 속성은 0~255까지의 값만 가질 수 있고, (finite)
이 3가지 속성은 0~255 사이의 정수 1개만 가질 수 있습니다. (discrete)
Pixel (Picture Element)
Pixel은 디지털 image의 1개 단위를 의미합니다.
RGB처럼 multi-channel digital image라면,
3개의 채널 요소가 합쳐져 1개의 pixel을 만드는 거죠.
비슷하게, 여러 채널요소가 합쳐져 Volume을 만들 수도 있고,
texture를 만들 수도 있습니다.
각각을 Voxel, Texel이라 부릅니다.
Raster Graphics
Image를 Pixel 단위로 표현한 것을 raster graphic representation,
또는 bitmap이라고 부릅니다.
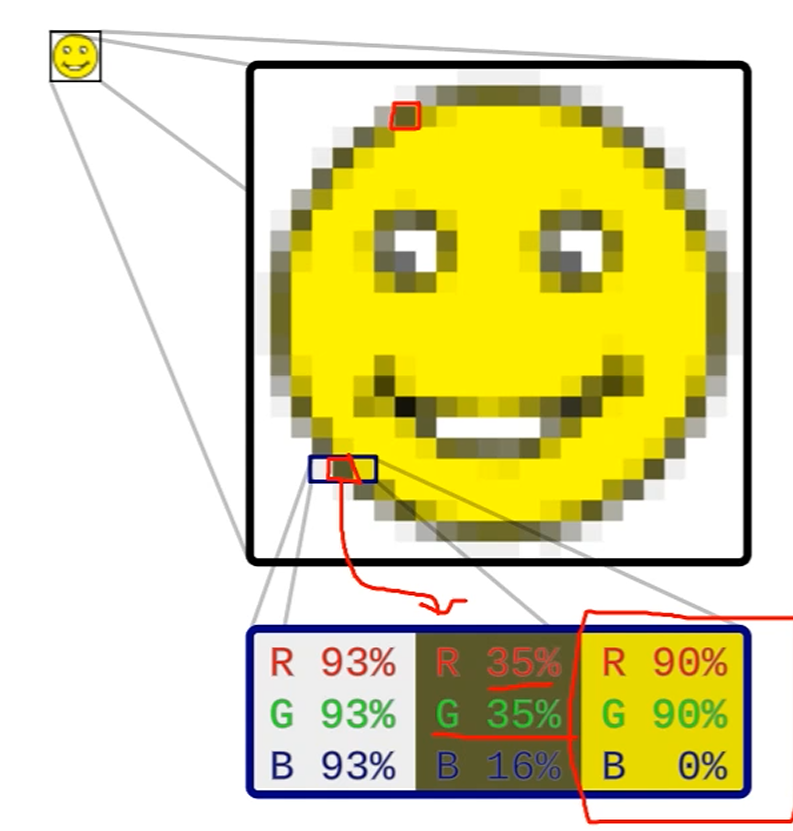
다음을 보시면 2D Array Structure로 pixel의 각 grid를 표현했죠.
실제 구현은 이렇게 되어 있습니다.
unsigned char image[height*width*3];
가령 Windows BMP에선 BGR 포맷으로 image가 저장됩니다.
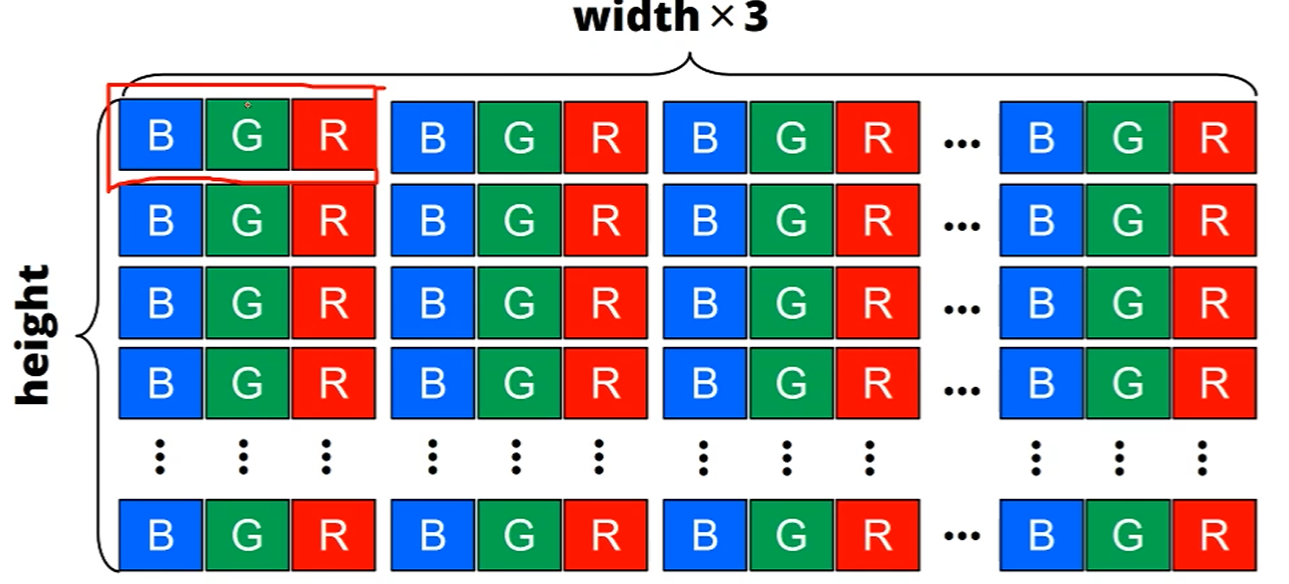
그리고 OpenGL이나 Windows에서 각 row는 4-byte alignment를 기준으로 하기 때문에,
만약 width*3이 4의 배수가 안 된다면 각 row 끝에 추가적인 byte를 추가하여 저장합니다.
Raster Image의 특징이 또 하나 있는데,
Raster Image는 실제 intensity distribution의 approximation입니다.
현실 세계의 image는 연속적입니다.
하지만 Raster Image는 Discrete하죠. 특정 지점을 딱 찝어서,
가장 가까운 Discrete Value로 Pixel을 표현합니다.
또한, Pixel의 색은 그 Pixel의 정 중앙의 색을 표현합니다.
하나의 Pixel 크기 내에 여러 색이 실제 세상엔 존재할 수 있겠죠?
그 중 정 중앙만 찝어서 색을 표현합니다.
Why use raster graphics?
이런 식으로 pixel단위로 digital image를 표현하는 raster graphic은,
-
실제 image의 function따윈 몰라도 brute-forcing을 통해 image를 대략 근사해낼 수 있습니다.
픽셀 단위로 쪼개서 가장 가까운 색으로 approximate만 시키면 되잖아요. -
Sampling을 더 빽빽하게 진행하면, (higher resolution) Quality가 늘어납니다.
-
대부분의 Display Device는 직사각형이죠?
그래서 Pixel단위의 image를 display device에 끼워넣기 편합니다.
pixel도 네모낳거든요.
What is the data types of raster graphics?
-
Bitmaps
pixel당 boolean으로 표현합니다. Fax나 오래된 신문같은 경우죠. -
Grayscale
Pixel 당 integer로 표현합니다.
각 integer는 gray level을 의미합니다.
보통 pixel당 8bit까지 표현하지만, 정교도를 위해 10, 12, 16bpp도 허용합니다. -
Color
Pixel 당 3 / 4개의 integer로 표현합니다. RGB거나, RGB/A(alpha/opacity)이거나.
보통 pixel당 8bit씩 줘서, 24bpp나 32bpp로 표현합니다. -
Floating Point
픽셀 값을 정수가 아니라 실수로 저장합니다.
HDR (High Dynamic Range) 이미지에 사용을 합니다.
48bpp 또는 96bpp를 쓰는데, 즉 RGB 각 채널이 16 또는 32bit float로 표현이 된다는거죠. (ㄷㄷ)
만약 1024 * 1024의 1 MegaPixel의 이미지를 저장할 때는 얼마나 용량이 필요할까요?
Bitmap의 경우 bool이 1bit니까, 10241024bit = 128KB
Grayscale은 10241024*8bit (8bpp일 때) = 1MB
Color 24bpp라면? 3MB겠죠?
HDR 96bpp면 12MB겠네요.
뭐 당연한거지만, 표현이 다채로워지고 풍부해질수록 용량을 많이 먹습니다.
Raster Graphics - File Containers
Image를 그냥 file로 저장하면, memory가 좀 빡세죠. 그래서 보통 압축을 합니다.
우리가 아는 것들이 좀 있습니다.
-
BMP : 아까의 Bitmap과 다르고, 이건 Windows Bit-map입니다.
Lossless raw format으로, 비트를 그대-로 저장합니다.
당연히 size는 high하겠죠? 대신 quality는 보장됩니다. -
JPEG (제이펙) : Lossy Compression입니다.
DCT (Discrete Cosine Transform)이라는 기술을 이용해 압축합니다. -
PNG (핑) : Lossless compression입니다.
ZLIB라는 기술을 이용해 압축합니다. -
WebP : Google이 개발한 압축 컨테이너입니다.
Vector Graphics
Raster Graphic과는 다르게, 기하학적인, 또는 산술적인 요소들을 사용해 표현합니다.
(Geometrical Primitives를 사용한다고 부릅니다.)
그래서, 이 '벡터 그래픽'에서의 Vector는 우리가 아는 그 크기와 방향을 가진 선이 아닌,
Circles, Lines, Triangles, Points, etc.. 와 같은
그림을 그리기 위해 쓰이는 기하학적 요소를 의미합니다.
2D Vector Graphic을 그리기 위해,
Adobe Illustrator, Adobe Acrobat, SVG, Postscripts 등이 쓰입니다.
SVG는 Vector Graphic을 Web에서 그릴 때 쓰이는 포맷이고,
PostScripts는 프린터나 프린터 파일을 위해 쓰이는 포맷입니다.
Vector Graphic의 또 다른 예시는, font입니다.
font는 언제 어디서 curve, 언제 어디서 직선처럼 정의가 되어 있어요!
유명한 VG의 예시죠.
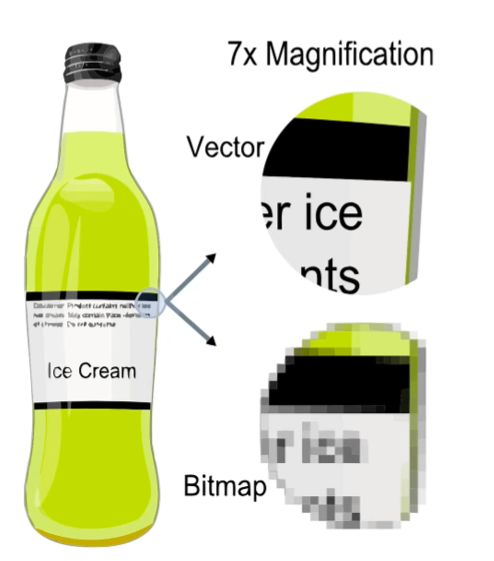
Vector Graphic은 확대한다고 Raster처럼 픽셀이 보이지 않습니다.
수학적으로 정의된 primitive들만 존재하기 때문에,
정해진 곳에서 정해진 곳까지 선을 긋기만 하면 되는거죠.
3D Graphics - 3D Vector to 2D Raster
3D Graphic의 기본 원리는 3D 세계의 vector를 Raster로 바꾸는 것입니다.
Point, Line, Polygon, Curve 등,
3D 세계에 존재하는 벡터 정보들을 입력으로 넣으면,
뚝딱 뚝딱 뭘 해서,
2D Raster Image로 바꾸는게 3D Graphic의 중요한 요소에요.
Graphic Terms
그래픽에 쓰이는 용어들을 좀 배워봅시다.
-
Capture Images
카메라의 센서에 들어오는 빛의 분포를 기록하는걸 Capture라고 부릅니다. -
Represent Images
Image를 Numerically, 보통은 Binary하게 인코딩하는 걸 의미합니다. -
Display Images
encode된 image를 실제 display device에,
실제 intensity distribution (real light)로 표현하는걸 의미합니다.
이렇게 3개의 과정이 이미지를 찍어서 화면에 보여주는 과정이겠죠?
Displays
Raster Display System
Screen Image는 RAM 내에서, 2D array로 정의됩니다.
그 Memory 영역을 Frame Buffer라고 부르는데요.
Frame Buffer는 대부분 GPU Memory 안에 들어있습니다.
그리고 GPU Memory는 보통 main memory와 공유됩니다.
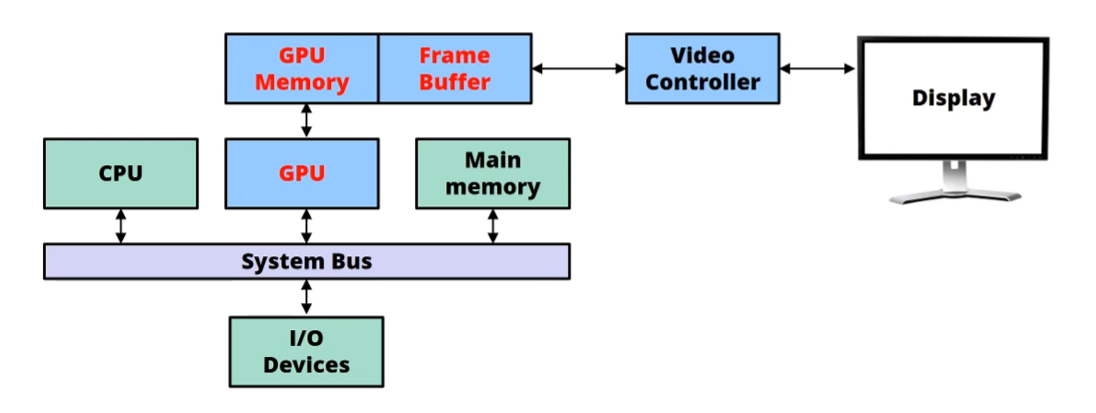
다음 아키텍처를 참고하시면 편할 것입니다.
